Apprentissage statistique - TELECOM ParisTech
2011 - 2012
Responsable du cours :
Stéphan Clémençon
Site pédagogique du cours
en accès limité.
Objectifs et présentation
Beaucoup d'applications modernes (génomique, finance, e-marketing) requièrent de manipuler et traiter des données de très grande dimension. La discipline qui développe et étudie des méthodes concrètes pour modéliser ce type de données s'appelle l'apprentissage statistique (statistical machine learning). Il s'agit, in fine, de produire des outils de prédiction et d'aide à la décision dédiés à une application spécifique. L'apparition d'algorithmes très performants pour la classification de données en grande dimension, tels que le boosting ou les Support Vector Machines dans le milieu des années 90, a progressivement transformé le champ occupé jusqu'alors par la statistique traditionnelle qui s'appuyait en grande partie sur le prétraitement réalisé par l'opérateur humain. En s'appuyant sur la théorie popularisée par Vapnik (The Nature of Statistical Learning, 1995), un nouveau courant de recherche est né: il se situe à l'interface entre les communautés mathématique et informatique et mobilise un nombre croissant de jeunes chercheurs tournés vers les applications liées à l'analyse de données massives. Dans ce module, on présentera le domaine, ses fondements, les problèmes qu'il permet d'aborder et les méthodes les plus récentes qui sont actuellement étudiées.
Feuilles de TD/TP
Petites expériences en R
Données utiles en TP
QUELQUES RÉFÉRENCES
Référence généraliste
- J. Friedman, T. Hastie, R. Tibshirani (2009).
The Elements of Statistical Learning. Third edition, Springer. Disponible en ligne .
Concernant la théorie de l'apprentissage
- O. Bousquet, S. Boucheron,; G. Lugosi (2004). Introduction to statistical learning theory. In O. Bousquet, U.V. Luxburg, G. Rätsch (editors), Advanced Lectures in Machine Learning, Springer, pp. 169-207, 2004. Disponible en ligne.
- S. Kulkarni, G. Lugosi and S. Venkatesh (1998). Learning Pattern Classification. A Survey. 1948-1998 Special Commemorative Issue of IEEE Transactions on Information Theory, vol.44, 2178-2206. Reprinted in S. Verdú, S.W. McLaughlin (editors.), Information Theory: 50 Years of Discovery, IEEE Press, New York, 1999.
Disponible en ligne.
- Györfi, Kohler, Krzyzak, Walk (2002) A Distribution-Free Theory of Nonparametric Regression.
- A. Karatzoglou and D. Meyer, Support Vector Machines in R, Journal of Statistical Software, April 2006, Volume 15 Issue 9.
Disponible en ligne.
Concernant la prédiction de séquences individuelles
- Cesa-Bianchi, Lugosi (2006) Prediction, Learning, and Games.
- G. Lugosi (2006). Prédiction randomisée de suites individuelles.
Journal de la Société Française de Statistique, 147:5-37.
Disponible en ligne.
- G. Stoltz (2011). Prédiction de suites individuelles, notes de cours. Disponibles en ligne.
Concernant l'apprentissage par renforcement
- Puterman (1994) Markov Decision Processes, Discrete Stochastic Dynamic Programming
- Sutton, Barto (1998) Reinforcement Learning.
- J.Y. Audibert, R. Munos (2010). ICML Tutorial on bandits.
Disponible en ligne .
- Sigaud, Buffet (2008) Processus Décisionnels de Markov en Intelligence Artificielle. Disponible en ligne.
- Bertsekas (1995) Dynamic Programming and Optimal Control. Disponible en ligne.
- Devroye, Györfi, Lugosi (1996) A Probabilistic Theory of Pattern Recognition.
Concernant le langage R
- Manuel d'utilisation en ligne de R
- R pour les débutants, par Emmanuel Paradis
- Statistiques avec R, par Pierre-André Cornillon, Arnaud Guyader, François Husson, Nicolas Jégou, Julie Josse, Maela Kloareg, Eric Matzner-Lober et Laurent Rouvière
- Régression avec R, par Pierre André Cornillon et Eric Matzner-Lober
MINI PROJETS
Par groupe de deux, à choisir dans la liste ci-dessous. Date de soutenance prévue : le vendredi 11 mai 2012.
- Forêt aléatoire
L'algorithme "Random Forest" introduit par L. Breiman dans le contexte de la classification/régression est considéré comme l'une des méthodes d'apprentissage les plus efficaces. Il s'agira ici de s'approprier les concepts sur lesquels reposent la procédure (ré-échantillonnage, agrégation et randomisation), les résultats théoriques et empiriques reflétant ses propriétés/limitations et de le mettre en oeuvre sur des données simulées et réelles (on pourra utiliser les données proposées à cet effet) afin de les illustrer. On pourra se référer au chapitre 15 de "The Elements of Statistical Learning", Trevor Hastie, Robert Tibshirani et Jerome Friedman, Springer 2007.
Références : article 1, article 2, article 3.
Encadrant : Stéphan Clémençon
- Détection d'anomalie
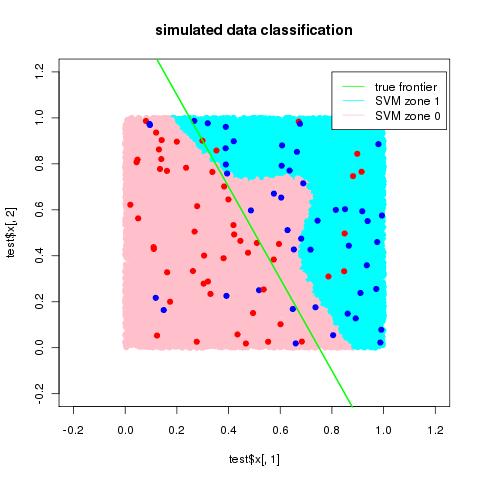
L'objectif de la détection d'anomalie ("novelty detection") est d'élaborer une règle permettant de prédire les données aberrantes ("outliers") à partir d'un échantillon d'une loi donnée (décrivant par exemple les sorties d'un système donné en régime "normal"). On parle ainsi de classification à une classe. La plupart des algorithmes disponibles pour effectuer cette tâche d'apprentissage reposent sur les mêmes principes que la classification binaire. On s'attachera dans ce projet à approfondir certaines méthodes telles que "SVM one-class" ou l'approche "MV-set" et à les mettre en oeuvre sur données simulées afin de les évaluer empiriquement.
Références : article 1, article 2, article 3, article 4.
Encadrant : Stéphan Clémençon
- Boosting
L'approche "Boosting" pour la classification est considéré comme "le meilleur algorithme de classification". Il s'agira ici de comprendre les mécanismes sur lesquels ce type de procédure repose, d'en maîtriser certaines variantes (selon le type de fonction de perte considéré, l'utilisation éventuelle de la randomisation, etc.) et de les mettre en pratique sur données simulées et réelles (on pourra utiliser les données proposées à cet effet). On pourra se référer au chapitre 10 de "The Elements of Statistical Learning", Trevor Hastie, Robert Tibshirani et Jerome Friedman, Springer 2007.
Références : article 1, article 2.
Encadrant : Stéphan Clémençon
- Filtrage Collaboratif
De nombreuses applications internet se développent sur un mode collaboratif. Les webradios exploitent les préférences des auditeurs qui ont taggé certains morceaux pour proposer des playlists personnalisées. Les moteurs de recherche constituent un autre exemple où l'information extraite est jugée pertinente par rapport aux préférences d'autres utilisateurs. Dans ce contexte, il apparaît difficile d'utiliser des requêtes avec des critères de tri pré-déterminés. Les méthodes issues du machine learning fournissent des outils permettant de faire émerger les critères de tri à partir des données enregistrées. La particularité de ce type d'applications est d'une part, la nature des données qui sont structurées en graphes ou prennent la forme de "préférences", et d'autre part la nature des sorties car les recommandations prennent la forme de rankings (listes). Au travers de ce projet, on approfondira les approches proposées dans les articles ci-dessous et on les mettra en oeuvre sur des données benchmark telles que recommandations de films (MovieLens Movie Rating Data Set), recommandations de livres (Book- Crossing Book Rating Data Set), site de rencontres (Online Dating Data Set).
Références : article 1, article 2, article 3.
Encadrant : Stéphan Clémençon
- Bandits non stationnaires
Les algorithmes de bandits classiques permettent de décider, séquentiellement, d'une suite d'action optimale à prendre dans un environnment stable. Toutefois, dans de nombreux problèmes, il n'est pas raisonnable de supposer que l'environnement est stationnaire : il faut prendre en compte la possibilité qu'il évolue dans le temps. Par exemple, en microscopie à effet tunnel, la qualité de l'image peut être considérée comme une fonction aléatoire réelle d'un paramètre donné tant que la pointe ne bouge pas; or cette pointe est amenée à bouger très légèrement de façon imprévisible de temps en temps, modifiant brutalement la distribution de la qualité des images pour chaque réglage des paramètres.
Pour faire face à ce défi, deux méthodes ont été proposées : l'algorithme EXP3.S, héritier des politiques soft-max, et l'algorithme D-UCB, qui s'appuie sur des intervalles de confiances de moyennes escomptées. Dans ce projet, on étudiera les vertus comparatives de ces deux méthodes et on cherchera mettre en évidence expérimentalement leurs différences de comportement.
Références :
On Upper-Confidence Bound Policies for Non-Stationary Bandit Problems
Switching between Hidden Markov Models using Fixed Share
Encadrant : Aurélien Garivier
- Plan d'expérience dynamique pour la maximisation
Dans beaucoup d'applications, on cherche à trouver le maximum d'une fonction
f:R^d->R, observée dans du bruit, qu'il est coûteux d'évaluer. Par exemple, si l'on recherche le point le plus chaud d'une salle d'ordinateurs, il est impossible de placer un thermomètre partout : il est important de savoir faire les bonnes mesures pour être rapidement capable de se concentrer sur les endroits les plus intéressants.
On se propose dans ce projet d'étudier une modélisation particulière de ce problème, basée sur les Processus Gaussiens. L'idée est d'utiliser les observations pour construire un intervalle de confiance pour f en tout point à la fois, et de demander comme nouvelle observation le point dont le sommet de l'intervalle est le plus élevé. On s'attachera à comprendre l'intérêt et les limites de cette approche, et on la testera sur simulations.
Références :
Gaussian Process Optimization in the Bandit Setting : No Regret and Experimental Design,
Regret Bounds for Gaussian Process Bandit Problems
Encadrant : Aurélien Garivier
- Algorithmes optimistes pour Processus de Décision Markoviens
Le principe d'optimisme, bien connu pour les problèmes de bandits, peut également être mis en oeuvre dans le cadre plus large des processus de décision markoviens (MDP) : il s'agit de trouver, parmi tous les paramètres rendants nos observations suffisamment vraisemblables, lesquels conduisent au MDP de valeur maximale, et de jouer suivant la politique optimale de ce "MDP optimiste".
On peut montrer qu'un tel algorithme peut être réalisé efficacement, et qu'il conduit à des stratégies dont le regret est seulement logarithmique. Les deux articles mis en références diffèrent par le choix de la métrique utilisée sur l'espace des paramètres, qui conduit à des comportement significativement différents.
Il s'agira, pour ce projet, de comprendre comment est menée l'analyse du regret, et d'expérimenter sur des exemples simples les alogorithmes UCRL et KL-UCRL.
Références :
Near-optimal regret bounds for Reinforcement Learning
Optimism in Reinforcement Learning and Kullback-Leibler Divergence
Encadrant : Aurélien Garivier
- Efficient Algorithms for Universal Portfolios
A constant rebalanced portfolio is an investment strategy that keeps the same distribution of wealth among a set of stocks from day to day. There has been much work on Cover’s Universal algorithm, which is competitive with the best constant rebalanced portfolio determined in hindsight. While this algorithm has good performance guarantees, all known implementations are exponential in the number of stocks, restricting the number of stocks used in experiments. We present an efficient implementation of the Universal algorithm that is based on non-uniform random walks that are rapidly mixing. This same implementation also works for non-financial applications of the Universal algorithm, such as data compression and language modeling .
Références :
article
- Finite-time Regret Bound of a Bandit Algorithm for the Semi-bounded Support Model
In this paper we consider stochastic multiarmed bandit problems. Recently a policy, DMED, is proposed and proved to achieve the asymptotic bound for the model that each reward distribution is supported in a known bounded interval, e.g. [0,1]. However, the derived regret bound is described in an asymptotic form and the performance in finite time has been unknown. We inspect this policy and derive a finite-time regret bound by refining large deviation probabilities to a simple finite form. Further, this observation reveals that the assumption on the lower-boundedness of the support is not essential and can be replaced with a weaker one, the existence of the moment generating function.
Références :
article.
Encadrant : Aurélien Garivier
- Réseaux bayésiens
Les réseaux bayésiens sont un outil de modélisation qui permet de représenter
les liens entre les données ou entre différentes sources de connaissances. On
peut aussi les voir comme des systèmes experts probabilistes. Cette approche
est utilisée de nombreuses applications : diagnostic, reconnaissance d’objets,
de parole, d’écriture, aide à l’annotation d’images. Il s’agira de comprendre
les mécanismes sous-jacents aux réseaux Bayésiens et de mettre en pratique des
réseaux simples (Naïve Bayes, Tree Augmented Network (TAN ) et Augmented Naïve
Bayes). On pourra utiliser des données réelles proposées par
http://archive.ics.uci.edu/ml/.
Références : Dynamic Bayesian Networks for Vehicle classification in Video,
Bayesian Networks.
Encadrante : Laurence Likforman
- A Link-Based Cluster Ensemble Approach for Categorical Data Clustering
Although attempts have been made to solve the problem of clustering categorical data via cluster ensembles, with the
results being competitive to conventional algorithms, it is observed that these techniques unfortunately generate a final data partition
based on incomplete information. The underlying ensemble-information matrix presents only cluster-data point relations, with many
entries being left unknown. The paper presents an analysis that suggests this problem degrades the quality of the clustering result, and
it presents a new link-based approach, which improves the conventional matrix by discovering unknown entries through similarity
between clusters in an ensemble. In particular, an efficient link-based algorithm is proposed for the underlying similarity assessment.
Afterward, to obtain the final clustering result, a graph partitioning technique is applied to a weighted bipartite graph that is formulated
from the refined matrix. Experimental results on multiple real data sets suggest that the proposed link-based method almost always
outperforms both conventional clustering algorithms for categorical data and well-known cluster ensemble techniques.
Références :
article.
Encadrante : Marine Campedel