
Bon, les amis, je vais être abrupte, mais voilà:
Les boucles sont officiellement has been depuis le printemps-été 2017. Non, je ne parle pas des boucles soyeuses et joyeuses qui s'ébattent sur vos têtes (pour les plus chanceux d'entre vous). Je veux parler des boucles laborieuses et épineuses qui s'étirent sur vos scripts.
Alors, je me sens quand-même légèrement gênée de vous annoncer cela vu que, peut-être, vous avez récemment appris à faire des boucles et vous vous en trouvez fort aise (moi aussi, je me souviens, quand j'ai fait mes premières boucles, de la joie, de la fierté éprouvée, de la conviction vibrante que j'allais désormais dire adieu aux assommantes tâches répétitives). Peut-être que mentionner la ringardise des boucles devant des gens qui apprennent à utiliser R, c'est comme annoncer à un ado tout fier des ses trois premiers poils de moustache que bon, c'est pas très joli et qu'il va falloir raser tout ça. Je précise donc, au cas où cette idée vous démoralise trop, qu'un peu de ringardise n'a jamais fait de mal à personne et que vous pouvez choisir de voir vos bonnes vieilles boucles for de derrière les fagots comme une touche "vintage" dans vos scripts (et nous ne sommes pas là pour juger!).
Concrètement, la boucle for n'a pas le vent en poupe pour plusieurs raisons: elle est assez longue à écrire, elle peut donner lieu à pas mal d'erreurs (elle est "error-prone", comme diraient les anglophones), et elle n'est pas très efficace en termes de calcul (ce dernier argument pouvant revêtir une importance plus ou moins avérée selon que vos scripts sont calculatoirement gourmands ou non).
Notez aussi que, non contentes de remplacer les boucles for, les fonctions de purrr sont aussi susceptibles de remplacer dans vos scripts les fonctions apply(), tapply(), sapply() et consorts...
Mais venons-en au fait, à savoir ce qui est censé remplacer les boucles for (parce que quand-même, savoir itérer une tâche, une routine, un script, ça reste un must), à savoir, les fonctions du package purrr.
Principe général
purrr, c'est un package du tidyverse (qui compte d'autres packages ultra-connus et appréciés comme dplyr, ggplot2, lubridate, etc.) qui sert à itérer des fonctions. C'est une package qui s'inscrit un peu dans la logique de la programmation fonctionnelle, c'est-à-dire dans l'idée que tout ce qui arrive dans R est le résultat d'un appel à une fonction (alors que ce qui existe dans R est un objet). Pour rendre à César ce qui revient à César, je reprends là les mots de John Chambers: “To understand computations in R, two slogans are helpful: Everything that exists is an object. Everything that happens is a function call.".
Fonctions: inputs, output, side effects
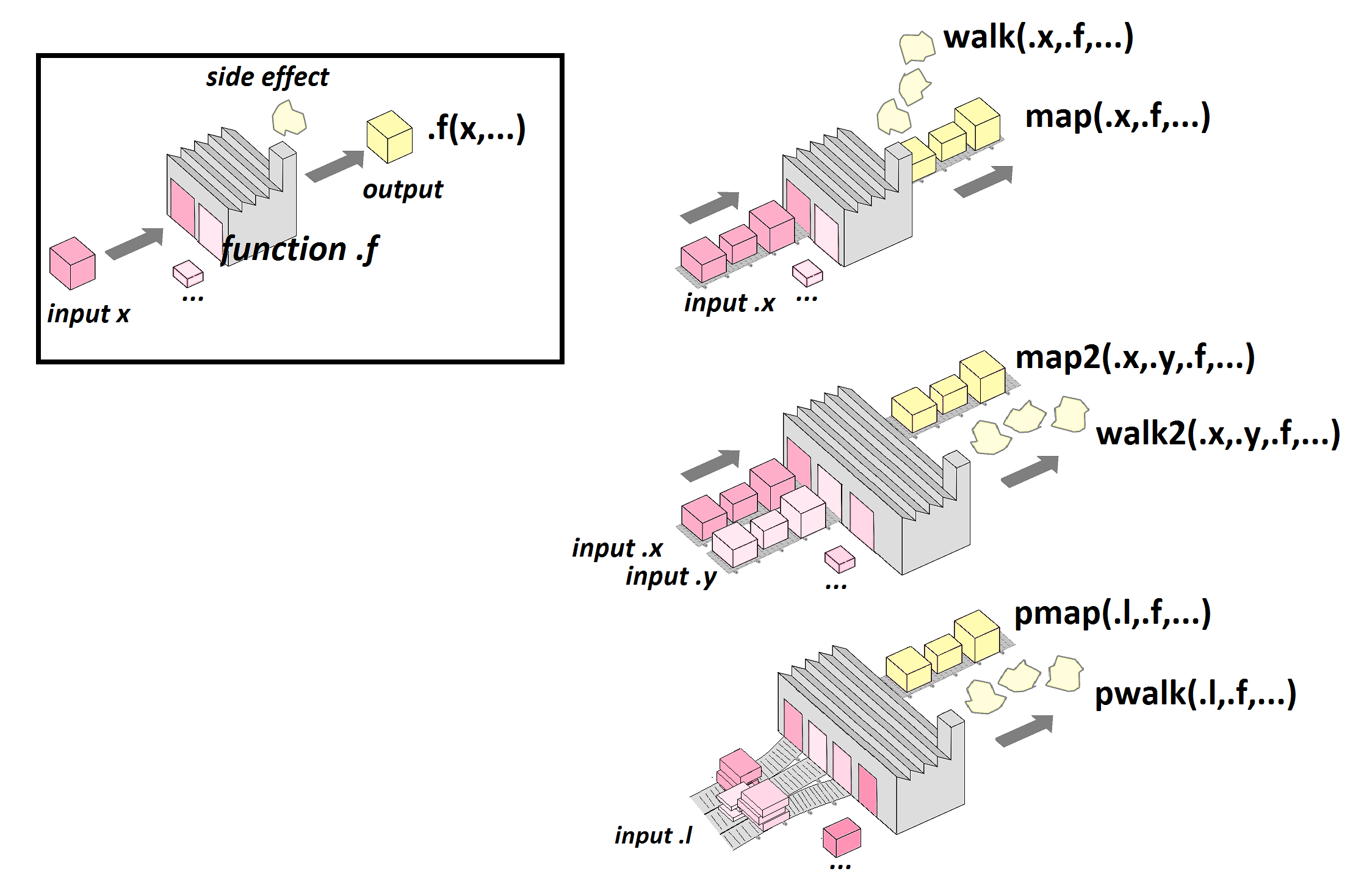
Voilà comment on peut voir une fonction...
... comme une petite usine qui transforme ses matières premières (les inputs, ou arguments) en produits finis (les outputs), en générant parfois au passage des effets "immatériels" -c'est-à-dire autres que des objets- ici représentés par de la fumée (les side effects).
Ici je considère une fonction .f() qui a un input principal x et des inputs secondaires (...). Classiquement, on va produire l'output en appelant la fonction avec pour arguments l'input x et les inputs secondaires: output=.f(x,...).
Par exemple:
x=c(33,NA,2,15,7,4,5)
moyenne=mean(x,na.rm=TRUE)
Ici, j'ai produit l'output moyenne en appelant la fonction mean(), avec pour argument principal x et pour argument secondaire na.rm=TRUE.
Itération: map(), walk()
Imaginons maintenant que je souhaite appeler la fonction mean() de manière répétée sur plusieurs éléments d'une liste:
myX=list(c(33,NA,2,15,7,4,5),
c(22,1,3,NA,11,2),
c(1,5),
c(3),
c(12,5,9))
Je pourrais choisir de le faire via une boucle for "vintage":
moyennes=vector("list",length=5)
for (i in 1:length(myX)){
moyennes[i]=mean(myX[[i]],na.rm=TRUE)
}
print(moyennes)
## [[1]]
## [1] 11
##
## [[2]]
## [1] 7.8
##
## [[3]]
## [1] 3
##
## [[4]]
## [1] 3
##
## [[5]]
## [1] 8.666667
OU BIEN je peux choisir de le faire avec la fonction map() du package purrr
library(purrr)
moyennes=map(myX,mean, na.rm=TRUE)
print(moyennes)
## [[1]]
## [1] 11
##
## [[2]]
## [1] 7.8
##
## [[3]]
## [1] 3
##
## [[4]]
## [1] 3
##
## [[5]]
## [1] 8.666667
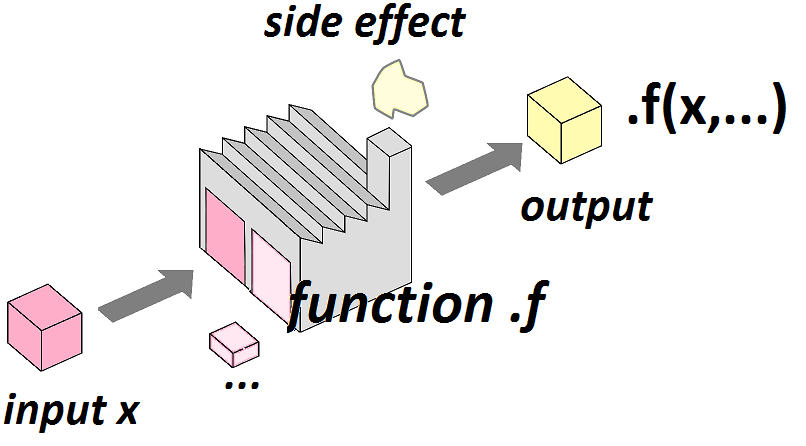
Ainsi, en utilisant map(), j'ai en quelque sorte transformé ma petite fonction/usine mean() en lui adjoignant une "rampe d'approvisionnement":
Mon argument principal, x, devient ainsi une liste d'éléments utilisés comme input pour la fonction mean(). Mon argument secondaire, na.rm=TRUE, est en revanche le même pour toutes les itérations.
L'output "moyennes" est par défaut également une liste.
Notez que l'on aurait pu ici demander explicitement à ce que le résultat nous soit renvoyé non pas comme une liste, mais comme un vecteur de valeurs numériques de type "double":
moyennes=map_dbl(x,mean,na.rm=TRUE)
print(moyennes)
## [1] 33 NaN 2 15 7 4 5
Selon le type d'output renvoyé par la fonction, il peut ainsi être assez pratique d'utiliser les fonctions map_dbl() (double) map_lgl (logique) map_int() (entier), etc.
Considérons maintenant les "effets secondaires"", en prenant pour exemple une fonction dont l'utilité première n'est pas de renvoyer un output, mais plutôt d'afficher quelque chose dans la console:
print_moyenne=function(x){
print(paste("la moyenne est de",
mean(x,na.rm=TRUE)))
return(NULL)
}
La fonction "walk()" permet d'itérer les "effets secondaires" d'une fonction... ici 5 messages/nuages de fumée différents:
walk(x,print_moyenne)
## [1] "la moyenne est de 33"
## [1] "la moyenne est de NaN"
## [1] "la moyenne est de 2"
## [1] "la moyenne est de 15"
## [1] "la moyenne est de 7"
## [1] "la moyenne est de 4"
## [1] "la moyenne est de 5"
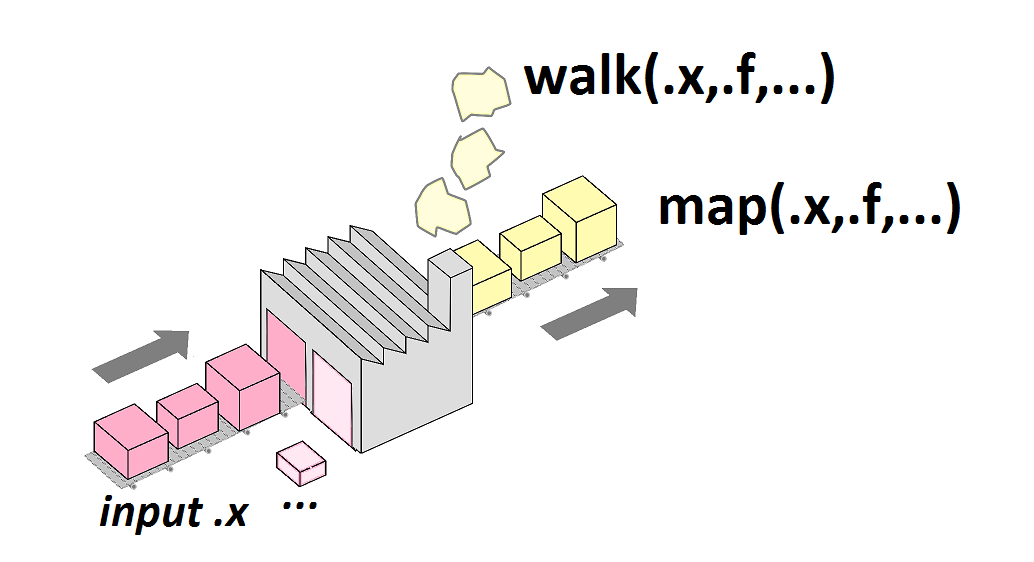
2 arguments principaux: map2()
Considérons maintenant une fonction à laquelle on voudrait adjoindre "deux rampes d'approvisionnement":
reg=function(x,y,w=rep(1,length(x))){
result=lm(y~x,weights=w)
return(result)
}
Cette fonction reg() réalise une régression linéaire de y en fonction de x (avec des poids uniformes, par défaut) et renvoie l'objet "régression linéaire" correspondant (l'output de reg() est donc un objet "composite" de type liste).
myX=list(c(2,5,6,7,1,0,1,1),
c(5,1,6,NA,2),
c(2,5,8,6))
myY=list(c(5,8,9,7,22,1,9,9),
c(2,8,9,5,4),
c(8,9,8,7))
On veut itérer la fonction reg() en considérant chaque élément de x ET de y (le i-ième élément de x correspondant au i-ième élément de y...). On peut faire cela en considérant la fonction map2().
map2(myX,myY,reg)
## [[1]]
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 9.2162 -0.1622
##
##
## [[2]]
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 5.85294 -0.02941
##
##
## [[3]]
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 8.28000 -0.05333
Notez ici que la fonction reg() renvoie une liste donc ce n'est pas pertinent ici d'essayer d'utiliser une fonction de type map_xxx() (en l'état, le résultat de l'itération ne peut pas être mis en forme comme un vecteur).
p arguments principaux: pmap()
Enfin, on peut généraliser ce principe à p > 2 arguments principaux:
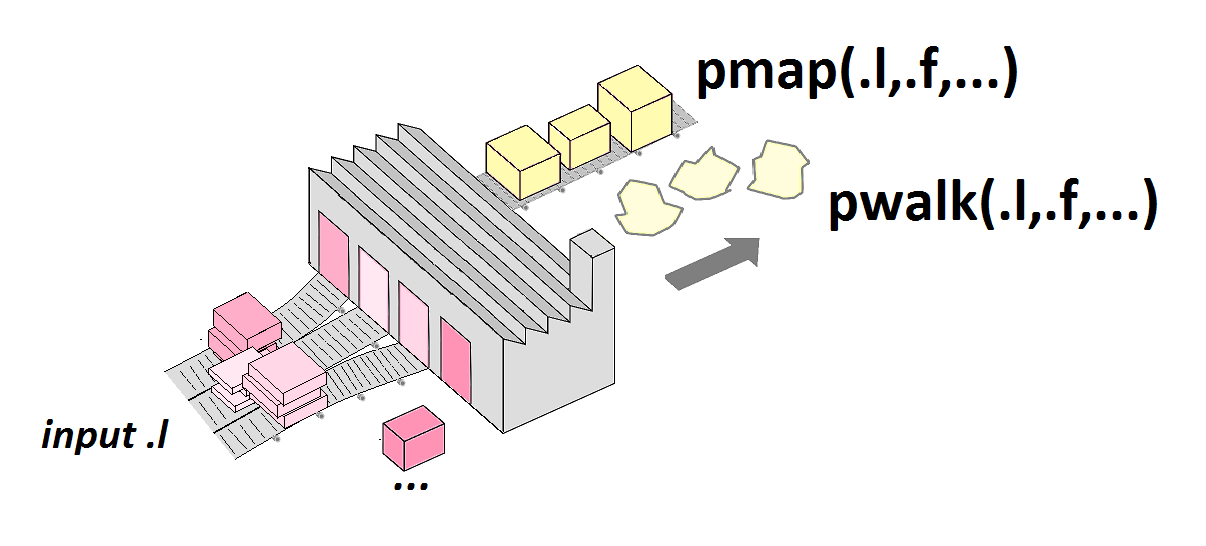
Dans ce cas, les p listes d'arguments sont fournis comme une liste, i.e. on passe à pmap() un argument .l qui est une liste de p éléments qui sont eux-mêmes des listes...
Considérons par exemple un cas où l'on souhaite itérer la fonction reg(), considérée précédemment, mais cette fois-ci sur 3 arguments, à savoir x, y, et w:
myW=list(c(1,2,1,1,1,2,1,1),
c(2,1,1,1,1),
c(1,2,1,1))
pmap(list(x=myX,
y=myY,
w=myW),
reg)
## [[1]]
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 7.3805 0.1855
##
##
## [[2]]
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 6.011 -0.266
##
##
## [[3]]
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 8.53191 -0.06383
Echapper aux erreurs: safely()
Jusqu'ici, tout va bien: j'ai choisi pour commencer des exemples d'application simples, où tout se déroule comme sur des roulettes.
Mais avec les fonctions de purrr comme avec une boucle for, il est particulièrement problématique qu'une des itérations génère une erreur, car même si cette erreur ne concerne qu'un élément parmi peut-être beaucoup d'autres, son occurrence stoppe l'exécution de toutes les itérations.
Considérons ainsi l'exemple suivant:
myX=list(c(2,5,6,7,1,0,1,1),
c(5,1,6,NA,2),
c())
myY=list(c(5,8,9,7,22,1,9,9),
c(2,8,9,5,4),
c())
map2(myX,myY,reg)
## Error in model.frame.default(formula = y ~ x, weights = w, drop.unused.levels = TRUE): type (NULL) incorrect pour la variable 'y'
Aïe... La fonction reg n'accepte pas que ses arguments x ou y soient nuls et génère ainsi une erreur sur la troisième itération. On n'obtient donc pas de résultat pour la troisième itération, ni, du reste, pour les autres...
Pour remédier à cela, outre modifier la fonction reg() pour qu'elle puisse s'adapter à ce cas particulier, il est possible d'utiliser la fonction safely():
map2(myX,myY,safely(reg))
## [[1]]
## [[1]]$result
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 9.2162 -0.1622
##
##
## [[1]]$error
## NULL
##
##
## [[2]]
## [[2]]$result
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 5.85294 -0.02941
##
##
## [[2]]$error
## NULL
##
##
## [[3]]
## [[3]]$result
## NULL
##
## [[3]]$error
## <simpleError in model.frame.default(formula = y ~ x, weights = w, drop.unused.levels = TRUE): type (NULL) incorrect pour la variable 'y'>
Dans ce cas, pour chaque élément d'input, on obtient un élément d'output qui contient deux choses:
- un élément
result(qui correspond au résultat souhaité et est dans ce cas vide pour le troisième élément, problématique) - un élément
error(qui correspond à l'éventuel message d'erreur généré et est dans ce cas vide pour les deux premiers éléments, qui ne génèrent pas d'erreur)
Manipulation des listes
Vous l'avez vu, purrr fait beaucoup appel à des objets de type liste, que ce soit en argument d'entrée ou en sortie. Il peut donc être utile de vous donner ou redonner quelques repères pour manipuler ces listes sans que cela vous cause trop d'inconfort...
Reprenons ainsi le résultat généré précédemment:
myRegs=map2(myX,myY,safely(reg))
On peut récupérer un élément de cette liste de la manière suivante (attention, des crochets simples récupéreraient une liste de longueur 1 contenant l'objet issu de reg(), et non l'objet issu de reg() directement):
myRegs[[1]]
## $result
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 9.2162 -0.1622
##
##
## $error
## NULL
On peut ensuite accéder aux éléments de myRegs[1] soit en utilisant leur nom (ici result ou error) soit en utilisant leur index (ici 1 ou 2)
myRegs[[1]]$result # idem: myRegs[[1]][1]
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 9.2162 -0.1622
... et si, pour chacun des 3 éléments de myRegs, je veux récupérer l'élément result, eh bien, là encore, la fonction map() peut me servir:
map(myRegs,"result")
## [[1]]
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 9.2162 -0.1622
##
##
## [[2]]
##
## Call:
## lm(formula = y ~ x, weights = w)
##
## Coefficients:
## (Intercept) x
## 5.85294 -0.02941
##
##
## [[3]]
## NULL
Attention, notez bien la différence de syntaxe:
map(x,"pouetpouet")
cherche à extraire un élément appelé "pouetpouet" des différents éléments de la liste x.
En revanche
map(x,pouetpouet)
cherche à appliquer une fonction appelée pouetpouet aux différents éléments de la liste x
Enfin, notons que le package purrr partage une caractéristique sympathique de ses petits collègues de tidyverse, à savoir la compatibilité avec le "piping". On peut ainsi enchaîner facilement différents appels à ses fonctions. Par exemple:
map2(myX,myY,safely(reg)) %>% #On itère la fonction reg()
map("result") %>% #On récupère l'élément "result"
map("coefficients") %>% #On récupère l'élément "coefficients"
map(2) #On récupère le deuxième élémnent de ce tableau
## [[1]]
## [1] -0.1621622
##
## [[2]]
## [1] -0.02941176
##
## [[3]]
## NULL
#On obtient ainsi les pentes des régressions
Enfin, une petite commande qui peut s'avérer pratique si l'on veut revenir à des données tabulaires :
myCoeffs=map(myRegs,"result") %>%
map("coefficients")
print(myCoeffs)
## [[1]]
## (Intercept) x
## 9.2162162 -0.1621622
##
## [[2]]
## (Intercept) x
## 5.85294118 -0.02941176
##
## [[3]]
## NULL
do.call("rbind",myCoeffs)
## (Intercept) x
## [1,] 9.216216 -0.16216216
## [2,] 5.852941 -0.02941176
En effet, do.call() permet de "redispatcher" les éléments d'une liste comme autant d'arguments d'entrée d'une fonction, c'est-à-dire qu'il permet d'utiliser myCoeffs (qui correspond à la liste des arguments myCoeffs=list(arg1,arg2,arg3)) pour appeler rbind(), alors que classiquement, rbind() devrait s'appeler de la manière suivante :
rbind(arg1,arg2,arg3)
Un mot d'encouragement ?
Je ne sais pas si vous êtes déjà convaincus, alors je vais en rajouter une couche: oui, les fonctions de purrr peuvent vous simplifier la vie, même si, oui, c'est une gymnastique intellectuelle au début...
Si vous comprenez bien l'usage des fonctions, et que vous prenez l'habitude d'utiliser des listes, ce package pourrait bien devenir une seconde nature... Et ça n'empêche pas de s'autoriser un petit plaisir rétro de temps en temps en écrivant une boucle for, de la même manière qu'on a le droit d'écouter des vinyles, d'aimer les plats mijotés, ou de porter la moustache en 2018.
17 Comments
Claire Della -Vedova
Bonjour Lise,
super article ! Merci pour cette introduction à purrr. Je pense que ça va me permettre de commencer à utiliser ce package pour de vrai !
lvaudor
Bonjour Claire!
Mais de rien! merci pour ce commentaire qui m'encourage à continuer d'écrire pour le blog 🙂
Mara
These are beautiful, and this explains so much so well!
lvaudor
Thanks Mara! I'm glad you like this, and I'm also glad you so reliably relay everything you like on Twitter :-). I owe you!
random (happy) cat
https://purrli.com/
lvaudor
Ah, merci random cat (pas si random que ça, je crois avoir une idée de qui se cache derrière ce pseudo 😉 ). Voilà qui devrait nous mettre à l'abri de tout burn out ou dépression hivernale 🙂
emilbebri
Google Translate did a good job of translating this.. thanks alot, I never really understood the map-function, but know I (think I) do.. this is immensely useful! Merci!
lvaudor
Thanks Emil! I'm glad you found it useful. That's right, the map() function is worth our struggling to finally understand how it works 🙂 !
LN
Super!! Cela semble si simple... adieu les belles boucles (ou presque).
merciiiii pour cette explication so pédago et si jolie!!
lvaudor
Héhé! Mais tout le plaisir est pour moi 🙂 ! Bon purrr!
Max
Bonjour,
Très bon tutoriel, très agréable à suivre, même si je ne partage pas toutes tes convictions sur l'utilisation "vintage" de R (lapply, for). Depuis que la compilation JIT est implémentée par défaut dans R, les gains de temps de calculs sont parfois considérables, ce qui rend les fonctions de tidyverse pas forcément plus efficaces (voir moins rapides). Par contre je partage pleinement ton avis sur le fait que tidyverse et ses développements sont une source incroyable de confort d'utilisation pour la manipulation des objets, graphiques etc.
Bonne continuation à ce blog que je trouve merveilleux et très instructif.
Max
lvaudor
Bonjour Max,
Merci beaucoup pour ces beaux compliments 🙂
En effet, j'ai mentionné le fait que la boucle for me semblait être de plus en plus considérée comme "vintage" mais pour tout te dire je ne suis pas non plus hyper sûre de pouvoir pleinement reprendre à mon compte les arguments de ses détracteurs. Je n'ai pas voulu me lancer dans une thèse-antithèse-synthèse donc... voilà. De mon point de vue (et pour la pratique que j'en ai) les fonctions de purrr sont surtout superbes de par leur facilité d'utilisation avec leurs consoeurs du tidyverse. Par ailleurs, d'un point de vue pédagogique/logique de programmation, je ne suis pas encore prête à passer les boucles for à l'as...
Alexandre STRAUSS
Bonjour,
article très didactique (je rejoins les autres sur ce point), c'est toujours intéressant d'avoir des explications plus illustrées et pédagogiques que la documentation du CRAN qui est, globalement, assez indigeste.
J'aurais une question, j'ai un besoin un spécifique que je réalise actuellement avec des "apply" :
j'ai deux listes d'arguments et une matrice (dont le noms de lignes et de colonnes sont les éléments de mes deux listes) de booléens. La fonction que j'appelle dans les apply fais du web scrapping particulièrement gourmand et long, je fais donc en sorte de ne l'appeler que sur les éléments pertinents. Pour cela, je construit ma matrice de booléens pour qu'elle vale "vrai" quand il faut faire la recherche. Or, disons que ma première liste s'appelle myX et contient (x1,x2,x3) et ma deuxième liste s'appelle myY et contient (y1,y2). Si j'ai bien compris le fonctionnement de "map2()", map2(myX,myY,maFonction) ne va pas fonctionner car myX et myY n'ont pas la même longueur (et de toute façon, ce n'est pas ce que je veux, puisque je souhaite combiner myX et myY et pas les dérouler parallèlement). Ma question est donc (désolé pour la longueur du post) : est-il possible avec "purrr" d'appliquer une fonction sur l'ensemble (ou certaines) combinaisons de deux listes ? Voire, y'aurait-il une méthode plus générale pour appliquer une fonction f. prenant n arguments à l'ensemble (ou certaines) combinaisons de n listes de valeurs des arguments (ces listes n'étant pas nécessairement de même longueur) ?
Merci beaucoup et bonne continuation pour ce blog.
lvaudor
Bonjour Alexandre,
Si j'ai bien compris votre idée, alors il faudrait que vous transformiez légèrement votre fonction et vos arguments de la manière suivante:
1) transformer myX, myY et votre matrice en une seule table avec quelque chose du genre:
myDf=bind_cols(id=1:length(myMatrix),expand.grid(myX,myY),myZ=as.vector(myMatrix)) et en faire une "nested tibble" par identifiant de ligne (vous aurez alors une liste dont chaque élément correspondra à une ligne de la table)
myDf=myDf %>% group_by(id) %>% nest()
2) transformer légèrement votre fonction f en fonction g pour qu'elle prenne pour argument une table de 1 ligne et qu'elle ne s'exécute que quand le booléen est TRUE
g=function(df1row){
if(df1row$Z){
result=NA
if(df1row$Z){
result=f(df1row$myX,df1row$myY)
}
return(result)
}
3) appliquer map avec comme arguments myDf et la fonction "g"
myResult=map(myDf,g)
Alexandre STRAUSS
Bonjour,
merci pour la réponse. En essayant, la piste semble prometteuse, il faudra juste que j'étudie un peu plus précisément les fonctions "expand.grid" et "nest". Pour info, j'ai noté déjà que fournir à expand.grid une liste nommée des deux listes a l'intérêt de conserver le nom des variables dans la "nested tibble", ce qui n'était pas le cas si je ne fournissait que deux vecteurs normaux.
Merci encore pour la réponse très rapide, un blog bien écrit et pédagogique et ou, en plus, les questions ne sont pas laissées sans réponses, je l'ajoute tout de suite dans mes marque-page 🙂
Alexandre STRAUSS
Bonjour,
juste pour dire, qu'en m'inspirant de la réponse, j'ai finalement créer une nouvelle fonction qui prend en argument la ville de départ, la ville d'arrivée et deux booléens (je scrap deux sites web). Le principe de cette fonction est simple, elle s'écrit :
Recup <- function(ville_depart,ville_arrivee,afaire_site1,afaire_site2) {
resultat <- tibble()
if (afaire_site1) resultat <- bind_rows(resultat,recup_site1(ville_depart,ville_arrivee))
if (afaire_site2) resultat <- bind_rows(resultat,recup_site2(ville_depart,ville_arrivee))
return(resultat)
}
J'ai ensuite utilisé la fonction "combinations", qui a l'avantage de ne pas créer de doublons (y compris dans le désordre, donc si vous avez déjà le couple (x,y) il ne vous mettra pas le couple (y,x)).
Ensuite je crée une table, appelons-la maTable, avec quatre colonnes, la première sont mes villes départ, la deuxième les villes arrivée, les deux autres sont les booléens pour les deux sites.
Enfin, je fais un pmap sur maTable et la fonction Recup qui s'écrit comme suit :
Resultat_complet <- pmap_df(maTable,Recup)
L'avantage que j'y trouve, c'est que comme ma fonction Recup renvoie une data.frame, pmap_df colle tout seul les tables renvoyées les unes en dessous des autres, le résultat est donc une data.frame. Par ailleurs, comme je le disais c'est assez long, cette méthode me permet aussi de créer une barre de progression avec la fonction "progress_estimated" et d'afficher la progression en pourcentage et le temps restant estimé.
Merci en tout cas pour votre aide, en espérant que ce commentaire pourra aider d'autres personnes a utiliser purrr.
BONNEFOY
Merci c'est fort agréable de lire et de comprendre ce que vous expliquez. Encore