
La boucle for est un peu le B-A BA de la programmation sous R, mais (pour ceux qui ne connaissent pas), elle a de quoi vous mettre des étoiles dans les yeux (sans exagérer!).
En effet, elle permet de vous éviter certaines tâches répétitives en les automatisant, et ainsi de vous faire gagner beaucoup de temps...
Voici comment elle est structurée:
for (i in 1:n){
## tâche à répéter n fois pour i variant de 1 à n
}
On a un compteur (ici appelé i) qui varie de 1 à n par incrément de 1.
Exemple stupide mais simple:
Par exemple, si l'on veut afficher 10 fois de suite "Bonjour!" à l'écran, on peut procéder ainsi:
for (i in 1:10){
print("Bonjour!")
print(i)
}
## [1] "Bonjour!"
## [1] 1
## [1] "Bonjour!"
## [1] 2
## [1] "Bonjour!"
## [1] 3
## [1] "Bonjour!"
## [1] 4
## [1] "Bonjour!"
## [1] 5
## [1] "Bonjour!"
## [1] 6
## [1] "Bonjour!"
## [1] 7
## [1] "Bonjour!"
## [1] 8
## [1] "Bonjour!"
## [1] 9
## [1] "Bonjour!"
## [1] 10
Voici ce qui se passe:
- D'abord, i=1,
- On affiche "Bonjour!", puis la valeur de i
- La valeur de i est incrémentée de 1 (i.e., désormais, i=2)
- On revient au début du code inséré dans la boucle
- On affiche "Bonjour!", puis la valeur de i
- La valeur de i est incrémentée de 1 (i.e., désormais, i=3)
- On revient au début du code inséré dans la boucle
- etc.(La dernière itération correspond à i=n)
Exemple intelligent mais un peu moins simple:
Afficher "Bonjour!" dans la console R n'étant pas, en soi, un objectif de travail très réaliste, voyons maintenant un "vrai" exemple de travail.
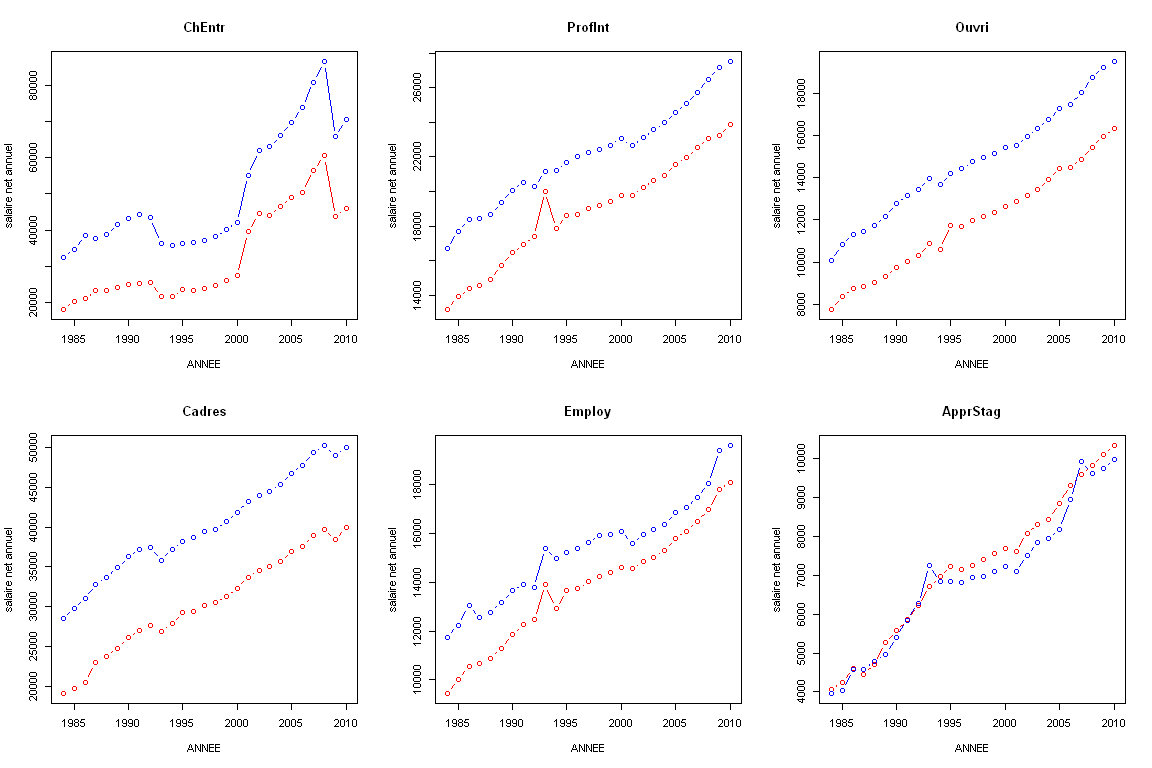
Imaginons que l'on souhaite travailler sur les données disponibles ici.
Il s'agit des salaires moyens (en euros) en France selon la catégorie socio-professionnelle et le sexe entre 1984 et 2010 (données INSEE).
- ChEntr: chefs d'entreprise
- CadSup: cadres et professions intellectuelles supérieures
- ProfInt: professions intermédiaires
- Employ: employés
- Ouvri: ouvriers
- ApprStag: apprentis et stagiaires
data_boucles_for=read.csv(paste(dat.path,"data_boucles_for.csv",sep=""), sep=";")
print(data_boucles_for[1:10,])
## ANNEE SEXE ChEntr Cadres ProfInt Employ Ouvri ApprStag
## 1 1984 Homme 32464 28479 16716 11752 10063 3959
## 2 1984 Femme 18169 19090 13200 9443 7754 4062
## 3 1985 Homme 34827 29764 17710 12236 10813 4046
## 4 1985 Femme 20493 19682 13921 10011 8359 4243
## 5 1986 Homme 38614 31047 18389 13034 11311 4574
## 6 1986 Femme 21135 20478 14418 10532 8761 4602
## 7 1987 Homme 37625 32814 18431 12544 11470 4588
## 8 1987 Femme 23259 22960 14612 10653 8863 4455
## 9 1988 Homme 38799 33692 18709 12780 11745 4788
## 10 1988 Femme 23298 23760 14952 10893 9050 4713
attach(data_boucles_for)
Si l'on veut produire un graphique représentant l'évolution des salaires au cours du temps pour chaque catégorie socioprofessionnelle en distinguant les hommes et les femmes, voici comment on peut procéder.
Voici les variables du jeu de données:
colnames(data_boucles_for)
## [1] "ANNEE" "SEXE" "ChEntr" "Cadres" "ProfInt" "Employ" "Ouvri" "ApprStag"
Les données pour chaque catégorie socio-professionnelle se trouvent sur les colonnes 3 à 8
# On divise la fenêtre graphique en 6 sous-fenêtres
layout(matrix(1:6,nrow=2))
# On veut répéter les mêmes instructions pour j variant de 3 à 8:
for (j in 3:8){
# On trace un nuage de points qui correspond à l'ensemble des données
# (hommes et femmes)
plot(ANNEE, data_boucles_for[,j],
main=colnames(data_boucles_for)[j],
ylab="salaire net annuel")
# On sélectionne les données qui correspondent aux femmes
# pour tracer la série en rouge
indf=which(SEXE=="Femme")
points(ANNEE[indf],data_boucles_for[indf,j], col="red", type="b")
# On sélectionne les données qui correspondent aux hommes
# pour tracer la série en bleu
indh=which(SEXE=="Homme")
points(ANNEE[indh],data_boucles_for[indh,j], col="blue", type="b")
}
Exemple encore plus intelligent mais encore moins simple:
On peut imbriquer des boucles for. Considérons à nouveau le graphique précédent. On fait en fait deux fois la même chose pour les hommes et les femmes... De ce fait il serait possible de faire une deuxième boucle à l'intérieur de la première:
# On divise la fenêtre graphique en 6 sous-fenêtres
layout(matrix(1:6,nrow=2))
# On veut répéter les mêmes instructions pour j variant de 3 à 8:
for (j in 3:8){
# On trace un nuage de points qui correspond
# à l'ensemble des données (hommes et femmes)
plot(ANNEE, data_boucles_for[,j],
main=colnames(data_boucles_for)[j],
ylab="salaire net annuel")
# On sélectionne les données qui correspondent aux femmes (k=1)
# puis aux hommes (k=2) pour tracer les séries en rouge puis en bleu
for (k in 1:2){
ind=which(SEXE==c("Femme","Homme")[k])
points(ANNEE[ind],data_boucles_for[ind,j], col=c("red","blue")[k], type="b")
}
}
Ici on produit exactement le même graphique que ci-dessus. L' "économie" en temps (et en nombre de lignes de code) n'est certes pas très important dans la mesure où l'on n'a répété le processus que deux fois, mais cet exemple permet de comprendre le principe des boucles imbriquées...
Notez que l'ordre des boucles a son importance!!