
J’ai récemment eu à travailler avec des données d’enquête (ce qui m’arrive somme toute assez rarement) et notamment à tenter de produire des tableaux et des figures rendant compte de ces données, souvent catégorielles.
J’ai été assez rapidement confrontée à un problème qui peut sembler trivial de prime abord, mais qui néanmoins n’est pas si anecdotique que cela au regard du temps qu’il peut faire perdre: la manipulation de factors, et notamment les changements d’ordre et de noms de leurs niveaux.
Ce changement de noms est souvent nécessaire pour rendre les noms de niveaux explicites (i.e. transformation d’un « code », par exemple « SiteTemAvt », en langage naturel, comme « Site témoin avant traitement »). Quand au changement d’ordre, il peut être utile pour rendre compte d’une ordination naturelle de niveaux (par exemple les niveaux « Adolescent », « Adulte », « Enfant », « Nourrisson » d’un factor « Tranche d’âge » devraient a priori s’organiser dans l’ordre « Nourrisson », »Enfant », »Adolescent », »Adulte »).
Or, ces opérations peuvent être assez pénibles en n’utilisant que les fonctions de R base. Je suis donc allée faire un tour du côté du tidyverse pour voir s’il n’existerait pas, par hasard, un package pour faire ce genre de choses… Et bien sûr, il y en a un. Il s’agit du package forcats (nom de package qui confirme, une fois de plus, que le monde des développeurs R est un monde de crazy cat ladies et crazy cat buddies ergo je suis juste parfaitement adaptée à mon milieu).
Je me suis donc empressée d’aller voir ce billet de blog dont voici ci-après ma ré-interprétation/mise en images.
Et pour un autre billet, toujours en français, et bien plus complet (et avec un vrai meme de chat -à ne pas confondre avec la mémère à chat-), c’est ici, sur le blog de ThinkR, que ça se passe.
Chargeons de ce pas forcats, avant de décomposer les différents éléments de cette figure…
library(forcats)
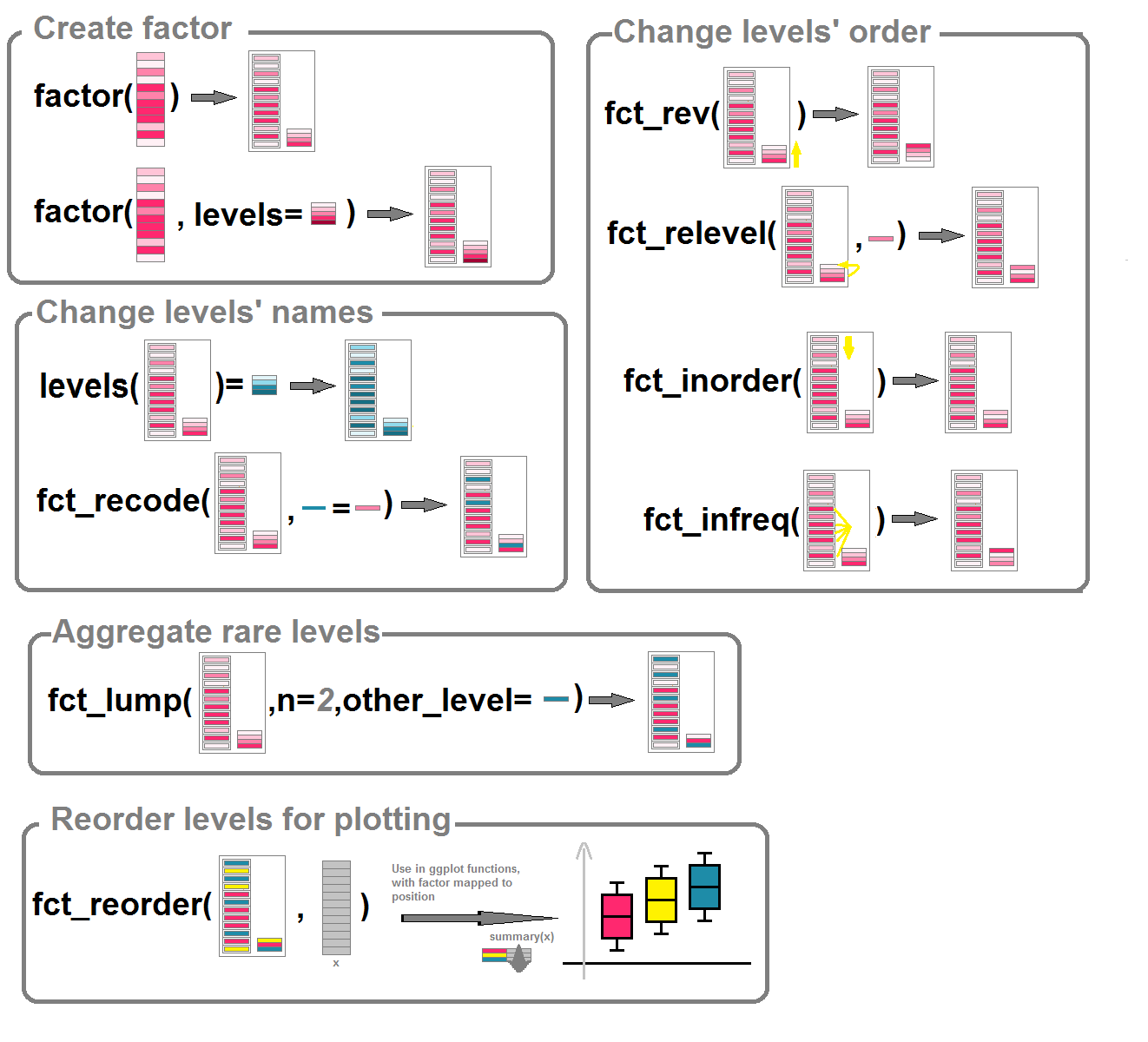
Créer des factors
On peut créer un factor à l’aide de la fonction factor() (pour le coup il ne s’agit pas d’une fonction de forcats mais d’une fonction de base).
Par défaut, quand on crée un factor à partir d’un vecteur, les niveaux sont créés en considérant l’ensemble des valeurs uniques de ce vecteur.
vecteur=c("b","a","c","a","d","c","d","d","d","b","d","a")
f1=factor(vecteur)
print(f1)
## [1] b a c a d c d d d b d a
## Levels: a b c d
Notez que les niveaux du factor sont ordonnés par défaut par ordre alphabétique.
Il est possible que certaines valeurs possibles pour ce factor soient absentes du vecteur, auquel cas on peut spécifier l’ensemble des valeurs prises de la manière suivante:
f2= factor(vecteur, levels=c("a","b","c","d","e"))
print(f2)
## [1] b a c a d c d d d b d a
## Levels: a b c d e
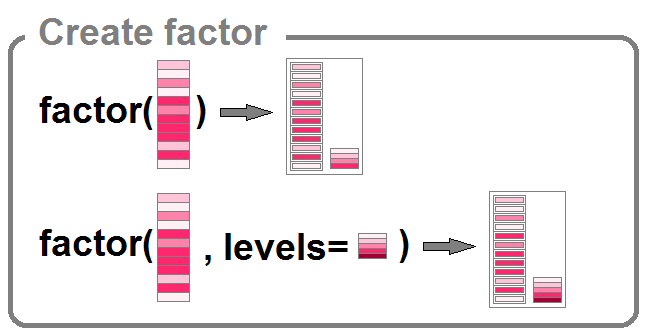
Changement des noms de niveaux
Si l’on souhaite modifier les noms de niveaux, on peut procéder de deux manières:
- soit en changeant l’ensemble des noms de niveaux d’un coup, avec la fonction
levels()debase - soit en choisissant spécifiquement le niveau qu’on souhaite modifier, à l’aide de la fonction
fct_recode()deforcats
Dans les deux cas, bien sûr, le nom n’est pas seulement modifié dans la partie « levels » du factor, mais également dans les valeurs mêmes.
f1
## [1] b a c a d c d d d b d a
## Levels: a b c d
f2=f1
levels(f2)=c("tagada","pouetpouet","tsointsoin","boum")
f2
## [1] pouetpouet tagada tsointsoin tagada boum tsointsoin boum boum boum pouetpouet boum tagada
## Levels: tagada pouetpouet tsointsoin boum
f2=fct_recode(f1, tsointsoin="c")
f2
## [1] b a tsointsoin a d tsointsoin d d d b d a
## Levels: a b tsointsoin d
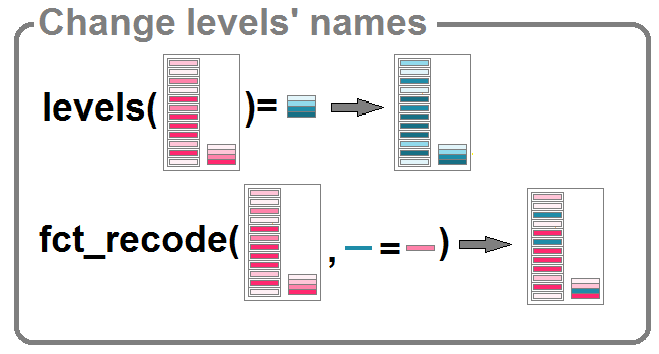
Changement de l’ordre des niveaux
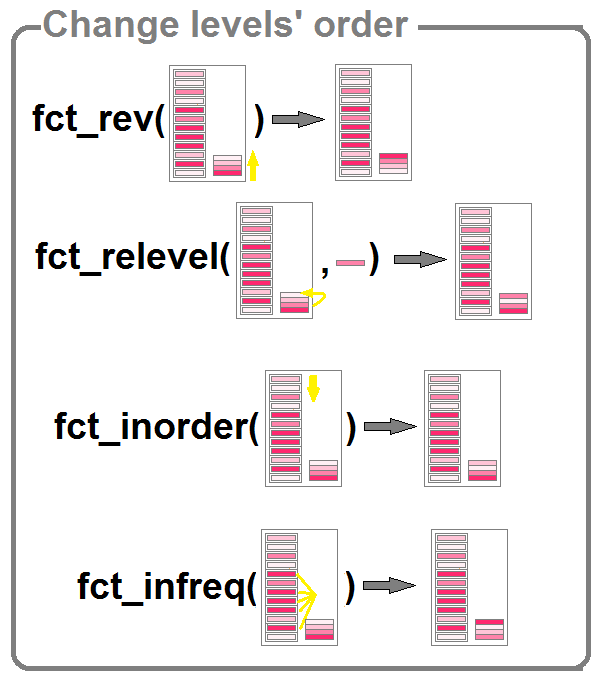
Plusieurs fonctions permettent de réordonner les niveaux.
fct_rev()permet d’inverser l’ordre des niveauxfct_relevel()permet de spécifier le rang d’un ou plusieurs niveaux spécifiquesfct_inorder()permet de ranger les niveaux selon leur ordre d’apparition dans la série de valeursfct_infreq()permet de ranger les niveaux selon leur ordre (décroissant) de fréquence.
fct_rev(f1) #inverse les niveaux
## [1] b a c a d c d d d b d a
## Levels: d c b a
fct_relevel(f1,"c") #remonte "c" en tête
## [1] b a c a d c d d d b d a
## Levels: c a b d
fct_relevel(f1,"c","d") #remonte "c" et "d" en tête
## [1] b a c a d c d d d b d a
## Levels: c d a b
fct_relevel(f1,"a",after=2) #place a en 3ième position
## [1] b a c a d c d d d b d a
## Levels: b c a d
fct_inorder(f1) # ordre d'apparition: b apparaît en premier, puis a, etc.
## [1] b a c a d c d d d b d a
## Levels: b a c d
fct_infreq(f1) # ordre de fréquence: d est le plus fréquent, puis a, etc.
## [1] b a c a d c d d d b d a
## Levels: d a b c
Agrégation des niveaux rares en un seul niveau
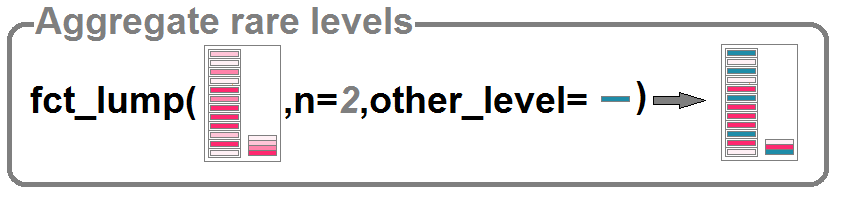 Dans certains cas, les effectifs des différents niveaux peuvent être très désequilibrés. Dans ce cas, il peut être utile de réagréger un certain nombre de niveaux rares en un seul niveau. C’est ce que permet la fonction
Dans certains cas, les effectifs des différents niveaux peuvent être très désequilibrés. Dans ce cas, il peut être utile de réagréger un certain nombre de niveaux rares en un seul niveau. C’est ce que permet la fonction fct_lump().
vecteur=c(rep("a",9),rep("b",6),rep("c",3),"d","e")[sample(1:20, 20, replace=FALSE)]
f3=factor(vecteur)
f3
## [1] b a a a b a a a c c b d b e a c b a a b
## Levels: a b c d e
Les effectifs sont répartis comme suit:
table(f3)
## f3
## a b c d e
## 9 6 3 1 1
La fonction fct_lump peut réagréger les niveaux moins fréquent (« c », »d », et « e ») en un seul niveau « Other »:
fct_lump(f3)
## [1] b a a a b a a a Other Other b Other b Other a Other b a a b
## Levels: a b Other
Bien entendu, il est possible de paramétrer cette fonction pour définir plus explicitement les seuils de fréquence ou de proportion que l’on utilise pour définir quels niveaux sont considérés comme peu fréquents.
fct_lump(f3, n=3) # niveaux rares= effectif < 3
## [1] b a a a b a a a c c b Other b Other a c b a a b
## Levels: a b c Other
fct_lump(f3, prop=0.15) # niveaux rares= proportion < 15%
## [1] b a a a b a a a Other Other b Other b Other a Other b a a b
## Levels: a b Other
fct_lump(f3, other_level="autre") # nom du nouveau niveau
## [1] b a a a b a a a autre autre b autre b autre a autre b a a b
## Levels: a b autre
Changement d’ordre en vue d’une production graphique
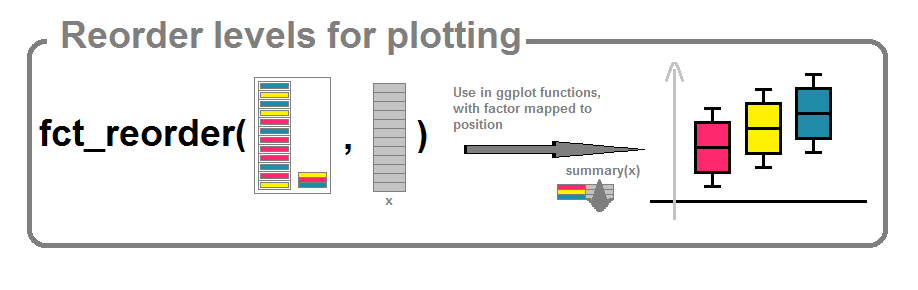 Quand on produit des graphiques impliquant une variable catégorielle, il peut être utile d’ajuster la position/les niveaux des points/barres/boîtes à moustaches de manière à rendre le graphique le plus lisible possible.
Quand on produit des graphiques impliquant une variable catégorielle, il peut être utile d’ajuster la position/les niveaux des points/barres/boîtes à moustaches de manière à rendre le graphique le plus lisible possible.
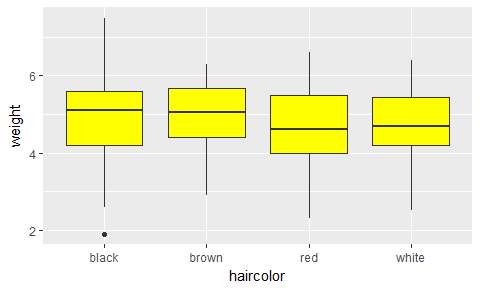
Sans fct_reorder():
catdata= read.csv(url("http://perso.ens-lyon.fr/lise.vaudor/Rdata/Graphiques_avec_ggplot2/catdata.csv"), sep=";")
library(ggplot2)
ggplot(catdata, aes(x=haircolor, y=weight)) +
geom_boxplot(fill="yellow")
Avec fct_reorder():
ggplot(catdata, aes(x=fct_reorder(haircolor,weight), y=weight)) +
geom_boxplot(fill="yellow")
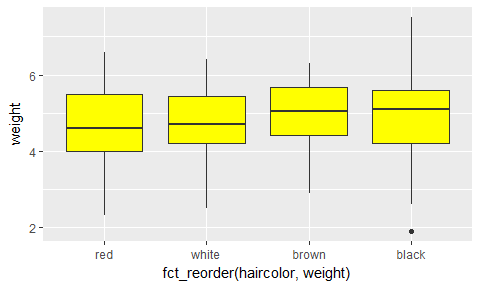 Les niveaux sont ordonnés par ordre croissant de médiane de
Les niveaux sont ordonnés par ordre croissant de médiane de weight (median() est la fonction utilisée par défaut par fct_reorder() mais il est possible d’en changer en utilisant l’argument fun=...) .
Autre exemple, les effectifs:
Sans fct_reorder():
ggplot(catdata, aes(x=haircolor)) +
geom_bar(aes(fill=sex))
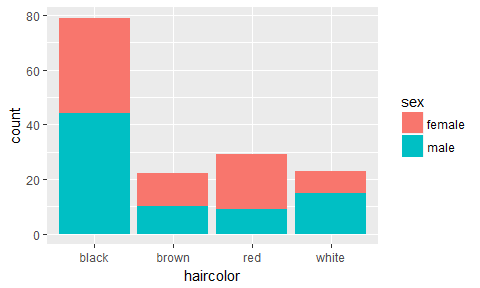
Avec fct_reorder():
ggplot(catdata, aes(x=fct_reorder(haircolor, sex, fun=length, .desc=TRUE))) +
geom_bar(aes(fill=sex))
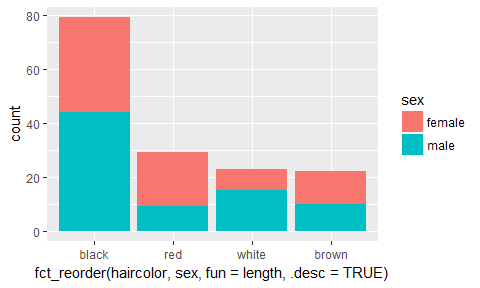
Les niveaux de haircolor sont réorganisés par ordre (ici, l’ordre décroissant du fait de l’argument .desc=TRUE) de fréquence.
4 Comments
Gina
Non d’un petit bonhomme mais vous êtes combien à blogguer sur ce thème ????????
lvaudor
Hihi, Gina, bienvenue dans l’univers de utilisateurs de R. Le problème de la manip de facteurs, ça semble être un problème bête, mais c’est un vrai problème…
Julien
Merci pour cette présentation, les fonctions de forcats sont effectivement pratiques pour ces opérations très fréquentes quand on travaille sur des enquêtes.
Si je peux me permettre un tout petit peu d’autopromo, l’extension questionr propose deux « addins » (petites interfaces graphiques qui génèrent du code R) qui peuvent faciliter le recodage et le réordonnancement des modalités d’une variables quali. Plus d’infos ici (en anglais, désolé) :
https://juba.github.io/questionr/articles/recoding_addins.html
lvaudor
Bonjour Julien,
Pas de souci pour l’autopromo :-). Justement, `questionr` fait partie des extensions que je me suis promis d’explorer prochainement -dès que j’aurai un peu de temps, ou que je déciderai que « tant pis si je n’ai pas le temps »- (j’aime beaucoup `explor` donc j’ai des a priori positifs 🙂 ). En tout cas je vais en toucher deux mots à mes collègues qui travaillent un peu sur données d’enquête!