
Plus je travaille avec R, plus je travaille sur les données de collègues, et plus je réalise l’importance (en termes de temps, et en termes de conséquences sur l’analyse elle-même) de l’étape préalable à l’analyse: le nettoyage et la mise en forme des données.
En effet, la façon dont on structure son jeu de données va d’une part conditionner notre capacité à comprendre, intuitivement, quelles sont les analyses que l’on peut réaliser (les données doivent ainsi être organisées correctement, en lien avec la question de recherche que l’on se pose!). Une organisation correcte du jeu de données va également nous permettre de réaliser facilement les analyses en question. Sous R, les fonctions sont conçues pour procéder facilement à l’analyse (la plupart du temps, même, en deux coups de cuillère à pot) pourvu qu’on leur fournisse des arguments « conformes » en entrée.
Deux types de problèmes peuvent se présenter lorsque l’on travaille sur des jeux de données « sales »:
- le premier type est lié à la lecture d’un fichier depuis R. Dans ce cas c’est l’appel à la fonction
read.table(ou consoeur) qui va poser problème. - le deuxième type est plus « conceptuel », puisqu’il est lié à l’organisation du tableau : il s’agit de bien formaliser ce qui est variable (ou attribut) et individu (ou unité d’observation), dans notre tableau de données.
Nettoyer un fichier de données pour le lire sous R
En général, lire un tableau de données sera la première chose que vous voudrez faire en travaillant sous R. Néanmoins, ce n’est pas forcément l’étape la plus facile: en pratique la lecture des tableaux de données est souvent problématique, par exemple si les noms de colonnes contiennent des caractères spéciaux ou des espaces, si le séparateur décimal du fichier est une virgule et non un point, si le fichier contient des commentaires, etc.
Ce genre de problèmes arrive très souvent à ceux qui travaillent ordinairement avec Excel et pour qui le tableau de données est également un document de travail (avec des commentaires, des noms de colonnes à rallonge destinés à être les plus explicites possible, des graphiques, des mises en forme destinées à rendre le document plus lisible, etc.).
N’oubliez que pour R, ce tableau est censé ne comporter que de la donnée BRUTE!… Veillez donc à bien « nettoyer » le fichier que vous voulez lire dans R: avoir des noms de colonnes simples et sans espaces, enlever les commentaires et mises en forme inutiles, etc.
On peut également spécifier certains des arguments de la fonction read.table pour contrôler la lecture du fichier. Ces options sont détaillées dans le fichier d’aide associé à la fonction: on peut l’ouvrir grâce à l’une ou l’autre des commandes suivantes:
help(read.table)
?read.table
Les fonctions de la famille de read.table (read.csv, read.delim, etc.) ont pour argument principal l’argument file, qui indique le chemin du fichier que vous cherchez à lire. Attention, dans le chemin indiqué, il faut proscrire les « \ », et les remplacer par « / » ou « \ » (la raison à cela, c’est que dans R, l’antislash est un caractère réservé -un « escape character »-).
La plupart du temps, les autres arguments importants pour réussir à importer un jeu de données sont:
sep: le séparateur de colonnes (qui peut être";",","," ","", etc.)dec: le séparateur décimal (qui peut être « , » si vous travaillez par exemple avec Excel en VF!)header: qui vous permet d’indiquer si la première ligne du fichier correspond à des noms de colonnes (header=TRUE) ou non
Si vous travaillez avec RStudio, vous pouvez aussi utiliser le bouton « Import Dataset« , dans l’onglet « Environnement », qui reconnaît « intuitivement » (et souvent assez bien) les caractéristiques d’un fichier de données.
Mettre en forme du tableau de données avec tidyr
Passons maintenant à la question de la structure du jeu de données. Dans l’idéal, un jeu de données devrait être structuré de la manière suivante:
## Variable1 Variable2 Variable3
## individu1 ... ... ...
## individu2 ... ... ...
## individu3 ... ... ...
## individu4 ... ... ...
## individu5 ... ... ...
Ainsi, pour mettre en forme correctement un jeu de données, il convient de bien définir ce qui est variable, et ce qui est individu, et de faire en sorte que les variables apparaissent en colonne, et les individus en ligne.
Alors, certes, j’ai un peu l’impression d’enfoncer une porte ouverte… Mais en pratique, les problèmes de structure dans un jeu de données sont courants, ce qui montre que l’exercice n’est pas si trivial.
Exemple: plusieurs colonnes correspondent à une même variable
Considérons le jeu de données suivant, qui porte sur des abondances d’oiseaux dans différents sites touristiques parisiens, à diverses dates:
## Espece Site Date1 Date2 Date3
## 1 moineau Saint-Germain-des-Prés/6ème 5 15 13
## 2 moineau Champs-Elysées/8ème 1 3 11
## 3 moineau Montmartre/18ème 15 6 4
## 4 moineau Buttes Chaumont/19ème 5 10 8
## 5 pigeon Saint-Germain-des-Prés/6ème 6 21 6
## 6 pigeon Champs-Elysées/8ème 20 3 9
## 7 pigeon Montmartre/18ème 9 20 3
## 8 pigeon Buttes Chaumont/19ème 2 6 10
Si vous souhaitez travailler sur ce même exemple, vous trouverez le fichier ici.
Si la mise en forme de ce jeu de données permet de visualiser facilement l’évolution des abondances de moineau et pigeon au cours du temps, elle pose question dans le sens où, en fait, on pourrait considérer que les colonnes Date1, Date2 et Date3 ne renseignent pas des variables différentes, mais bien la même variable… Ainsi, il vaudrait mieux que le jeu de données soit organisé de la manière suivante:
## Espece Site Date Abondance
## 1 moineau Saint-Germain-des-Prés/6ème Date1 5
## 2 moineau Champs-Elysées/8ème Date1 1
## 3 moineau Montmartre/18ème Date1 15
## 4 moineau Buttes Chaumont/19ème Date1 5
## 5 pigeon Saint-Germain-des-Prés/6ème Date1 6
## 6 pigeon Champs-Elysées/8ème Date1 20
## 7 pigeon Montmartre/18ème Date1 9
## 8 pigeon Buttes Chaumont/19ème Date1 2
## 9 moineau Saint-Germain-des-Prés/6ème Date2 15
## 10 moineau Champs-Elysées/8ème Date2 3
## 11 moineau Montmartre/18ème Date2 6
## 12 moineau Buttes Chaumont/19ème Date2 10
## 13 pigeon Saint-Germain-des-Prés/6ème Date2 21
## 14 pigeon Champs-Elysées/8ème Date2 3
## 15 pigeon Montmartre/18ème Date2 20
## 16 pigeon Buttes Chaumont/19ème Date2 6
## 17 moineau Saint-Germain-des-Prés/6ème Date3 13
## 18 moineau Champs-Elysées/8ème Date3 11
## 19 moineau Montmartre/18ème Date3 4
## 20 moineau Buttes Chaumont/19ème Date3 8
## 21 pigeon Saint-Germain-des-Prés/6ème Date3 6
## 22 pigeon Champs-Elysées/8ème Date3 9
## 23 pigeon Montmartre/18ème Date3 3
## 24 pigeon Buttes Chaumont/19ème Date3 10
Dans cette deuxième mise en forme, une observation correspond à l’abondance d’une espèce donnée, à un endroit donné, et à une date donnée. Dans la mise en forme précédente, une observation correspondait à l’abondance d’une espèce donnée, à un endroit donné.
Et voici maintenant un des avantages que l’on a à organiser ses données de la « bonne » manière: il devient facile de réaliser des analyses et des graphiques qui retranscrivent correctement le contenu du jeu de données… Ici par exemple, on réalise très facilement avec le package ggplot2 un graphique qui montre l’ensemble du contenu du jeu de données:
library(ggplot2)
p=ggplot(mynewdata, aes(x=Date, y=Abondance))
p=p+geom_point(aes(col=Espece,shape=Site))
plot(p)
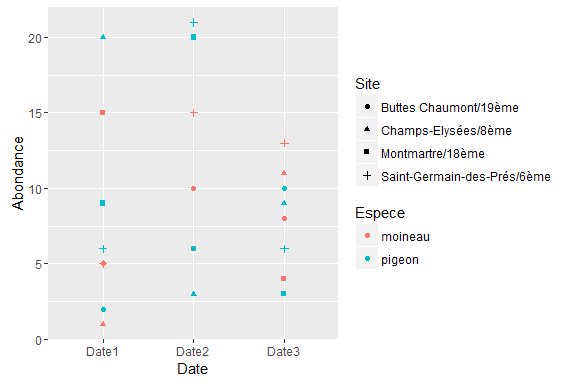
Il serait impossible (ou du moins, difficile et pénible) de réaliser ce même graphique avec le même jeu de données mis en forme selon le premier modèle, en tout cas en utilisant la logique « intuitive » de ggplot2, car dans ce cas les colonnes Date1, Date2, et Date3 seraient considérés a priori comme des variables indépendantes les unes des autres.
Alors, comment passer d’une mise en forme à l’autre? Eh bien, auparavant, pour passer de l’un à l’autre, il fallait soit changer le format de tableau à la main (par exemple, pour ceux qui ne sont pas trop à l’aise avec les langages de script, à coups de copier-coller dans votre tableur favori…), soit transformer le tableau à l’aide de quelques lignes de commande (par exemple sous R, par exemple à l’aide d’une boucle for). Cela pouvait vite être long (surtout dans le premier cas), compliqué (surtout dans le deuxième cas), et pénible (dans les deux cas).
Heureusement, il existe désormais des packages qui sont là pour nous simplifier la tâche. Permettez-moi ainsi de vous présenter le package tidyr. Comme son nom l’indique, l’objectif de tidyr (prononcer « tidyer »,in English of course), est de proposer quelques fonctions qui permettent de réaliser des opérations classiques lorsque l’on nettoie et restructure ses jeux de données. (J’ai bien dit « classiques », hein… dans certains, cas, il reste utile voire indispensable de savoir un petit peu programmer…).
Voici par exemple comment passer du jeu données avec les colonnes Date1, Date2, et Date3, à un jeu de donnée avec une seule colonne Date:
La fonction gather prend en entrée:
data: le jeu de données d’origine,key: le nom de la variable catégorielle à créer, iciDate(ses niveaux correspondront aux actuels noms de colonnes de mydata, à l’exception des colonnes indiquées ici par un « – » ,i.e., ici,EspeceetSite)value: le nom de la nouvelle variable contenant les valeurs auparavant contenues dansDate1,Date2,Date3
print(head(mydata))
## Espece Site Date1 Date2 Date3
## 1 moineau Saint-Germain-des-Prés/6ème 5 15 13
## 2 moineau Champs-Elysées/8ème 1 3 11
## 3 moineau Montmartre/18ème 15 6 4
## 4 moineau Buttes Chaumont/19ème 5 10 8
## 5 pigeon Saint-Germain-des-Prés/6ème 6 21 6
## 6 pigeon Champs-Elysées/8ème 20 3 9
print(head(mynewdata))
## Espece Site Date Abondance
## 1 moineau Saint-Germain-des-Prés/6ème Date1 5
## 2 moineau Champs-Elysées/8ème Date1 1
## 3 moineau Montmartre/18ème Date1 15
## 4 moineau Buttes Chaumont/19ème Date1 5
## 5 pigeon Saint-Germain-des-Prés/6ème Date1 6
## 6 pigeon Champs-Elysées/8ème Date1 20
N’est-ce pas merveilleusement simple?
Notez que gather a (en quelque sorte) une fonction inverse, spread:
mydataisback=spread(data=mynewdata,
key=Date,
value=Abondance)
print(head(mydataisback))
## Espece Site Date1 Date2 Date3
## 1 moineau Buttes Chaumont/19ème 5 10 8
## 2 moineau Champs-Elysées/8ème 1 3 11
## 3 moineau Montmartre/18ème 15 6 4
## 4 moineau Saint-Germain-des-Prés/6ème 5 15 13
## 5 pigeon Buttes Chaumont/19ème 2 6 10
## 6 pigeon Champs-Elysées/8ème 20 3 9
Exemple: une même colonne correspond à plusieurs variables
Deuxième exemple d’opération assez classique: prendre une colonne (comme Site dans le jeu de données ci-dessus) et en faire deux variables, à l’aide de la fonction separate…
finaldata=separate(data=mynewdata,
col=Site,
into=c("Quartier", "Arrondissement"),
sep="/")
print(head(finaldata))
## Espece Quartier Arrondissement Date Abondance
## 1 moineau Saint-Germain-des-Prés 6ème Date1 5
## 2 moineau Champs-Elysées 8ème Date1 1
## 3 moineau Montmartre 18ème Date1 15
## 4 moineau Buttes Chaumont 19ème Date1 5
## 5 pigeon Saint-Germain-des-Prés 6ème Date1 6
## 6 pigeon Champs-Elysées 8ème Date1 20
La fonction separate prend en entrée:
data: le jeu de données d’origine,col: le nom de la colonne à séparer en plusieurs variablesinto: les noms des nouvelles variables
Ici aussi, on a une fonction inverse… Il s’agit de unite:
backtomynewdata=unite(finaldata,
col=Site,
Quartier,
Arrondissement,
sep="/")
print(head(mynewdata))
## Espece Site Date Abondance
## 1 moineau Saint-Germain-des-Prés/6ème Date1 5
## 2 moineau Champs-Elysées/8ème Date1 1
## 3 moineau Montmartre/18ème Date1 15
## 4 moineau Buttes Chaumont/19ème Date1 5
## 5 pigeon Saint-Germain-des-Prés/6ème Date1 6
## 6 pigeon Champs-Elysées/8ème Date1 20
2 Comments
Liorel
Merci pour l’article ! je ne connaissais pas tidyr, il va s’avérer très pratique pour moi qui dois souvent passer du temps à expliquer à des médecins (voire à des data managers) que non, une ligne par patient, ça n’est pas pertinent quand on a plusieurs observations par patient. Question qui en découle : connais-tu une solution simple pour passer d’un tableau à une ligne par individu, et plusieurs variables mesurées de manière répétée, à une ligne par observation avec ces variables dans les bonnes colonnes ? Autrement dit, pour passer de :
Id datevisite1 fréquencecardiaque1 datevisite2 fréquencecardiaque2
1 12/03/16 88 14/05/16 73
2 14/04/10 63 21/05/16 60
à :
id datevisite fréquencecardiaque
1 12/03/16 88
1 14/05/16 73
2 14/04/10 63
2 21/05/16 60
Sinon, pour commenter sur la première partie du post : j’aurais ajouté quelques mots sur les pièges de l’encodage de caractères, qui me coincent souvent. En effet, quand il lit un fichier, R suppose par défaut qu’il a été encodé avec le codage de la machine sur laquelle il est installé. Quand il écrit un fichier, il l’écrit par défaut avec le codage de la machine sur laquelle il est installé.. Jusque là, pas de problème. Par contre, essaie de lire sous Windows (par défaut en latin1) un fichier créé sous Linux (généralement en UTF-8), et tu vas avoir des gags avec les accents… La solution est simple : elle consiste à préciser de façon explicite l’encodage de caractères au moment de la lecture et/ou de l’écriture avec l’argument encoding= »latin1″ ou encoding= »UTF-8″. À partir de là, plus de problème. À noter aussi que pour ceux qui travaillent avec LibreOffice plutôt qu’Excel, LibreOffice Calc propose une interface remarquablement bien fichue pour lire les fichiers CSV, au point que je ne vois plus vraiment d’argument pour utiliser Excel plutôt que LibreOffice, à part pour le cas rare où on a absolument besoin d’utiliser du VBA (et si c’est le cas, franchement, on ferait mieux de tout passer en CSV et d’utiliser R :P).
lvaudor
Bonjour!
Merci pour ces remarques!
En ce qui concerne la mise en forme du tableau que tu montres, je n’ai pas trouvé de solution directe, mais en fusionnant les variables date et fréquence de la manière suivante (avec la fonction unite() de dplyr), avant d’appliquer gather(), ça fait le job:
data=data.frame(Id=c(1,2),
datevisite1=c("12/03/16","14/04/10"),
fréquencecardiaque1=c(88,63),
datevisite2=c("14/05/16","21/05/16"),
fréquencecardiaque2=c(73,60))
data %>%
tidyr::unite(var1, datevisite1,fréquencecardiaque1) %>%
tidyr::unite(var2, datevisite2,fréquencecardiaque2) %>%
tidyr::gather(key="val",value="var", var1,var2) %>%
tidyr::separate(var,c("datevisite","fréquencecardiaque"),sep="_") %>%
dplyr::select(-val)
En ce qui concerne l’encodage: oui, c’est un problème fréquent et souvent pas évident à résoudre! Je pense qu’il mérite un billet à part entière et c’est pour ça que je ne l’avais pas trop évoqué dans ce billet… Mais c’est sur ma to-do-list! (oui bon, ça fait un moment que c’est sur ma to-do-list :-/ !)
A bientôt,
Lise