
purrr et dplyr sont dans un bateau: aucun ne tombe à l’eau
Voilà déjà 3 ans, je publiais sur ce blog un billet sur le package purrr. Depuis, avec la pratique, j’ai pu identifier quelques points techniques qui me mettaient en difficulté assez fréquemment et pour lesquels j’aimerais vous présenter quelques explications.
Ces difficultés sont en fait nées de l’utilisation simultanée de dplyr et de purrr, qui sont certes conçus pour fonctionner ensemble, mais dont l’usage conjoint pouvait des fois causer quelques noeuds à mon cerveau lors de l’écriture de mes codes.
Un petit rappel rapide d’abord:
Le principe de base de purrr, c’est d’itérer n fois une fonction sur les n éléments d’un vecteur ou d’une liste.
Si la fonction .f() prend en entrée un argument x (et éventuellement des arguments supplémentaires figurés ici par ...) et renvoie en sortie un résultat y
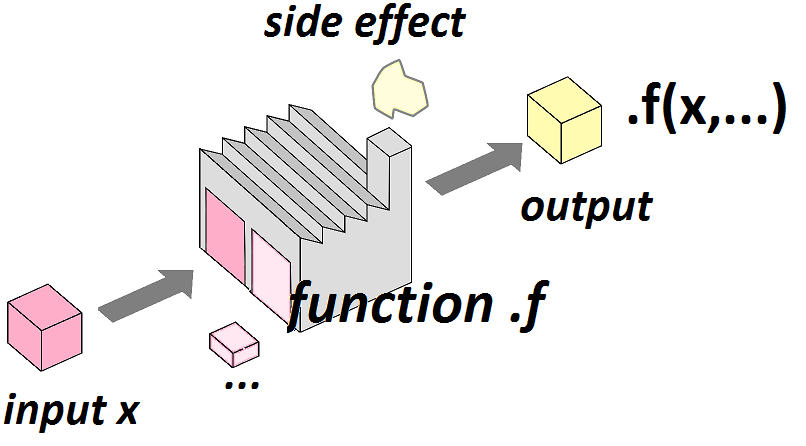
alors on peut grâce à purrr::map() appliquer la fonction .f() à tout un vecteur ou liste .x=(x_1,x_2,x_3,...,x_n) pour obtenir un vecteur ou liste (y_1,y_2,y_3,...,y_n).|
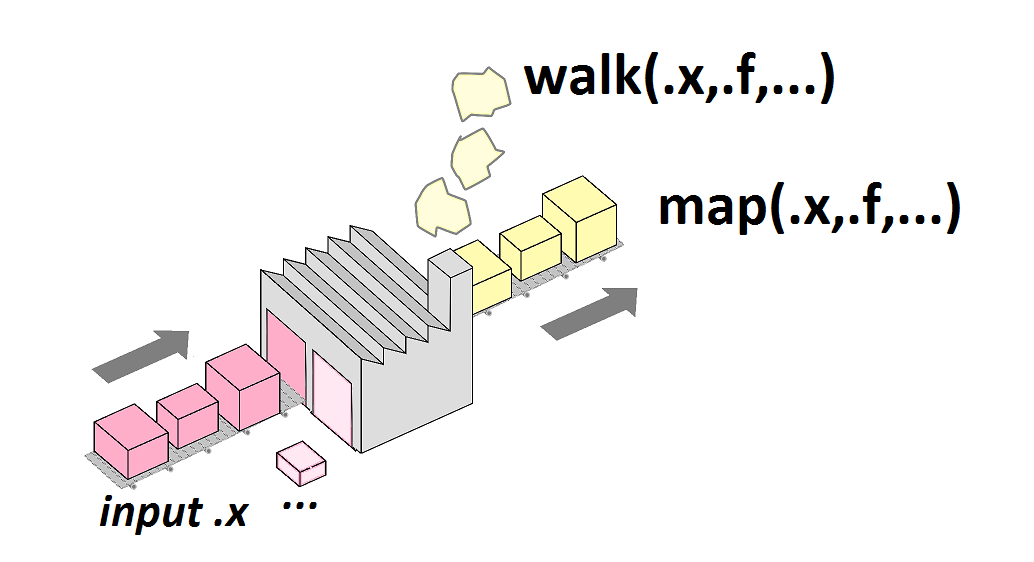
Alors, partant de ce principe, comment les fonctions de purrr peuvent-elles s’articuler avec les idées “tidy” et notamment l’omniprésence de tableaux pour traiter les données?
Fonctions, formules et pipéabilité
Le premier petit souci que j’ai pu avoir dans l’usage conjoint de dplyr et purrr était lié au fait que (faute d’avoir compris toutes les possibilités syntaxiques des fonctions du package) je me retrouvais souvent obligée d’écrire des petites fonctions “rustines” destinées à ne servir qu’une seule fois, et qui faisaient tache dans la beauté ondoyante et serpentine de mon code :-p (beauté ondoyante et serpentine conférée par l’usage de dplyr et des pipes bien sûr).
C’est-à-dire que, au lieu de faire
resultat <- blabla %>%
dplyr::truc() %>%
dplyr::bidule() %>%
dplyr::machin() %>%
dplyr::mutate(chose=purrr::map(fonction_standard)) %>%
dplyr::bidule() %>%
dplyr::machin()
j’étais régulièrement de faire un truc du genre
resultat <- blabla %>%
dplyr::truc() %>%
dplyr::bidule() %>%
dplyr::machin()
fonction_rustine=function(blabla){
blabla
}
resultat= resultat %>%
dplyr::mutate(chose=purrr::map(fonction_rustine)) %>%
dplyr::bidule() %>%
dplyr::machin()
car je ne trouvais pas la fonction standard adéquate.
Ainsi donc, ma méconnaissance de l’usage des formules dans les fonctions de purrr nuisaient à la “pipéabilité” de mon code. Cela vous semble peut-être un détail, mais ça m’ennuyait beaucoup (imaginez l’exemple ci-dessus avec davantage de lignes et plusieurs “petites fonctions rustines” par exemple: la relecture et compréhension de la chaîne de traitement s’en trouve vite complexifiée, même pour des opérations “toutes bêtes”).
Ainsi donc, première prise de conscience de ma part, on peut écrire, au lieu de :
rustine=function(blabla){
lignes_de_commande_impliquant_blabla
}
purrr::map(.x=truc, .f=rustine)
quelque chose comme:
purrr::map(.x=truc,
~lignes_de_commande_impliquant_.x)
L’usage d’une formule peut aussi permettre d’utiliser une fonction standard qu’on souhaite itérer sur un autre argument que son premier argument. Par exemple:
purrr::map(.x=truc,
~fonction_standard(a=33,b=.x))
Attention à la position des arguments supplémentaires pour la fonction .f() dans l’appel à map!
Dans le cas où on spécifie une fonction:
purrr::map(.x=truc,
.f=fonction_machin,
argument_supplémentaire=33)
#argument spécifié dans l'appel à map()
Dans le cas où on spécifie une formule:
purrr::map(.x=truc,
.f=~fonction_machin(blabla,
argument_supplémentaire=33))
# argument spécifié dans l'appel à fonction_machin()
Je n’ai pas réussi pour le moment à construire un “vrai” exemple permettant d’illustrer ces principes tout en restant simple… Je vais donc me contenter pour le moment de ces ‘fausses’ lignes de code…
Petit à petit, les données font leur nid
Passons maintenant à une autre fonction qui me permet régulièrement d’utiliser purrr pour mes jeux de données.
Il s’agit de la fonction tidyr::nest().
Chargeons le tidyverse:
library(tidyverse)
et examinons la situation suivante:
birds=tibble(id=paste0("ad_",1:6),
species=c("orange","yellow","blue",
"blue","yellow","orange"),
sex=rep(c("M","F"),3))

La fonction tidyr::nest() permet de regrouper des lignes et colonnes en sous-jeux de données dans une colonne data. La colonne data correspond à une colonne-liste (ou list-column en anglais). Autrement dit, la commande ci-dessous regroupe les données (selon l’argument spécifié pour group_by()) en nids.
nested_couples=birds %>%
group_by(species) %>%
nest()
nested_couples
## # A tibble: 3 × 2
## # Groups: species [3]
## species data
## <chr> <list>
## 1 orange <tibble [2 × 2]>
## 2 yellow <tibble [2 × 2]>
## 3 blue <tibble [2 × 2]>

Chaque couple-nid pond alors des oeufs selon des règles propres à leur espèce. Définissons la fonction lay_eggs() correspondant à ce processus.
lay_eggs=function(species){
n_egg=case_when(species=="orange"~2,
species=="blue"~1,
species=="yellow"~3)
eggs=tibble(egg=paste0("egg_",1:n_egg))
return(eggs)
}
lay_eggs("orange")
## # A tibble: 2 × 1
## egg
## <chr>
## 1 egg_1
## 2 egg_2
Cette fonction prend en argument d’entrée l’espèce considérée, et renvoie en sortie une table comprenant autant de lignes que d’oeufs pondus.
On peut appliquer cette fonction à l’ensemble des couples-nids de la manière suivante:
after_lay_eggs=nested_couples %>%
mutate(eggs=purrr::map(species,lay_eggs))

Examinons de plus près ce résultat, par exemple pour l’espèce “yellow”:
after_lay_eggs %>% filter(species=="yellow") %>% pull(eggs)
## [[1]]
## # A tibble: 3 × 1
## egg
## <chr>
## 1 egg_1
## 2 egg_2
## 3 egg_3
Il va s’agir maintenant de voir éclore les oeufs. Voici la fonction qui correspond à ce processus. Elle prend deux arguments: eggs, évidemment, mais aussi species, dont dépend le sex-ratio des juvéniles.
hatch_eggs=function(eggs,species){
sex_ratio=case_when(species=="blue"~0.54,
species=="yellow"~0.6,
species=="orange"~0.4)
youngs=eggs %>%
mutate(young=str_replace(egg,"egg","young")) %>%
select(-egg) %>%
mutate(sex=runif(nrow(eggs),0,1)) %>%
mutate(sex=sex<sex_ratio) %>%
mutate(sex=case_when(sex==T~"M",
sex!=T~"F"))
}
On itère sur les deux arguments de la fonction donc on utilise purrr::map2() :
set.seed(33)
after_hatch=after_lay_eggs %>%
mutate(youngs=purrr::map2(eggs,species,hatch_eggs)) %>%
select(-eggs)
Je retire la colonne eggs qui n’a plus lieu d’être après éclosion…

Examinons plus en détail par exemple ce qu’on obtient pour l’espèce “yellow”:
after_hatch %>% filter(species=="yellow") %>% pull(youngs)
## [[1]]
## # A tibble: 3 × 2
## young sex
## <chr> <chr>
## 1 young_1 F
## 2 young_2 F
## 3 young_3 M
Il est maintenant de laisser s’envoler nos petits oiseaux! Nous allons les faire sortir du nid…

birds_youngs=after_hatch %>%
unnest(cols=c("youngs")) %>%
ungroup()
birds_youngs
## # A tibble: 6 × 4
## species data young sex
## <chr> <list> <chr> <chr>
## 1 orange <tibble [2 × 2]> young_1 M
## 2 orange <tibble [2 × 2]> young_2 F
## 3 yellow <tibble [2 × 2]> young_1 F
## 4 yellow <tibble [2 × 2]> young_2 F
## 5 yellow <tibble [2 × 2]> young_3 M
## 6 blue <tibble [2 × 2]> young_1 M
En faisant appel à unnest() sur la colonne youngs, on sort les juvéniles de leur nid et les attributs des “nids” (ici species) sont répétés autant de fois que nécessaire pour qualifier désormais les individus juvéniles.
Notez qu’on ne pourrait pas faire la même opération de manière concomittante sur data pour une question de dimensions (data comporte des éléments qui ont tous 2 lignes, youngs comporte des éléments dont le nombre de ligne varie entre 1 et 3).
Ce petit exemple très simple (et imagé) vous aidera j’espère à exploiter les possibilités offertes par le trio dplyr-tidyr::nest()-purrr!
1 Comment
Belgacem Gasmi
C’est une page magnifique