Distributed Shared Memory Systems
D.S.M.
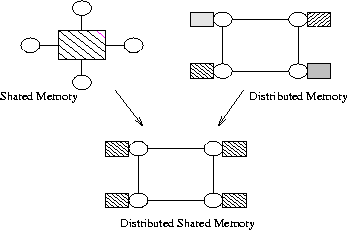
MIMD parallel machines can be divided in two class according to memory architecture:
- Shared memory machines
- are composed of a set of processors accessing to a single memory. The main advantage of these machines lies in their easy programmability due to the fact that there are no communications between the processors. However, contentions and collisions (due to concurrent accesses to the shared memory) prevent applications to be actually scalable. Therefore, in spite of some attempts, most of shared-memory machines are limited to a small number of processors ( < 32).
- Distributed memory machines,
- on the contrary, can integrate a large number of processors ( > 1000). Applications using these architectures can be scalable (if the programmer is good enough !). The communication model usually used is message passing, which can allow considerable speedups. However its programming remains difficult since end-users have to handle all
communication operations.
In that context, by allowing the programmer to access and to share "memory objects" (pages or variables) without being in charge of their management, Virtually shared memory systems want to propose a trade-off between the easy-programming of shared memory machines and the efficiency and scalability of
distributed memory systems. As we will see it below, these systems can be classified into two groups: Shared Virtual Memory (SVM) systems allow to use all the memories like a single address space memory; Objects Distributed Shared Memory (DSM) systems allow to share programming variables among several processors.
A distributed shared memory is a mechanism allowing end-users' processes to access shared data without using inter-process communications.
In other words, the goal of a DSM system is to make inter-process communications transparent to end-users. Both hardware and software implementations have been proposed in the literature.
From a programming point of view, two approaches have been studied:
- Shared virtual memory: This notion is very similar to the well-known concept of paged virtual memory implemented in mono-processor systems.
The basic idea is to group all distributed memories together into a single wide address space. Drawbacks: such systems do not allow to take into account the semantics of shared data: the data granularity is arbitrarily fixed to some page size whatever the type and the actual size of the shared data might be. The programmer has no means to provide informations about these data.
- Object DSM: in that class of approaches, shared data are objects i.e. variables with access functions. In his applications, the user has only to define which data (objects) are shared. The whole management of the shared objects (creation, access, modification) is handled by the DSM system. In opposite of SVM systems which work at operating system layer, objects DSM systems actually propose a programming model alternative to the classical message-passing.
In any case, implementing a DSM system implies to address problems of data location, data access, sharing and locking of data, data coherence. Such problems are not specific to
parallelism but have connections with distributed or replicated databases management systems
(transactionnal model), networks (data migrations), uniprocessor operating systems (concurrent programming), distributed systems.
The DOSMOS project proposes a new kind of DSM system which takes into account of efficiency and scalabity of the applications. To help the user to develop his applications it is completed with a monitoring tool called DOSMOS-Trace .
DOSMOS Team
 Lionel Brunie
Lionel Brunie
 Laurent Lefèvre
Laurent Lefèvre
 Olivier Reymann
Olivier Reymann
 Nathalie Restivo
Nathalie Restivo

 You
are the
You
are the
 th visitor, for more information, please contact : llefevre@lip.ens-lyon.fr
th visitor, for more information, please contact : llefevre@lip.ens-lyon.fr