La semaine dernière, je suis allée aux Rencontres R présenter un poster portant sur un package/appli shiny nommé HALtere, qui fournit quelques data-visualisations des données bibliographiques renseignées sur HAL. On peut ainsi s’en servir pour visualiser les publications d’une collection, d’un labo, d’un auteur, ou encore autour d’une thématique choisie.

Si vous voulez voir ce que ça donne en ligne (sur quelques listes de publications choisies par mes soins), c’est ici. Si vous voulez faire tourner sur la liste de publications de votre choix, allez voir le repo ici et suivez les instructions du README…
Le fait d’être passé par HAL plutôt que par une base de donnée bibliométrique plus internationale (comme Web of Science, Scopus, OpenAlex, etc.) est un signal clair quant à l’utilisation escomptée de cet outil: il s’agit de faire de la valorisation institutionnelle (pour une évaluation HCERES, pour une évaluation annuelle, pour un point d’étape dans la carrière d’un chercheur -par exemple, HDR-). En effet dans ESR français, c’est sur HAL que l’institution (CNRS notamment) nous demande expressément de renseigner notre production bibliographique. Et à ce titre, c’est sur HAL que l’on est (à peu près) sûr de trouver les données ad hoc pour valoriser une « entité de recherche ».
C’est en tout cas dans cet objectif que j’ai développé cette appli, notamment avec l’idée de valoriser la collaboration et l’interdisciplinarité (valeurs chères à l’institution, et arguments forts pour le montage de projets par exemple). Ainsi le module principal consiste à donner à voir les liens de co-autorat au sein d’une liste de publications.
Représenter les liens de co-autorat
Illustration avec la collection de mon laboratoire, sur les 10 dernières années (ici seuls les 400 auteurs les plus prolifiques sont représentés par des noeuds, et les 50 noms avec le plus de liens sont écrits, pour des raisons de lisibilité):
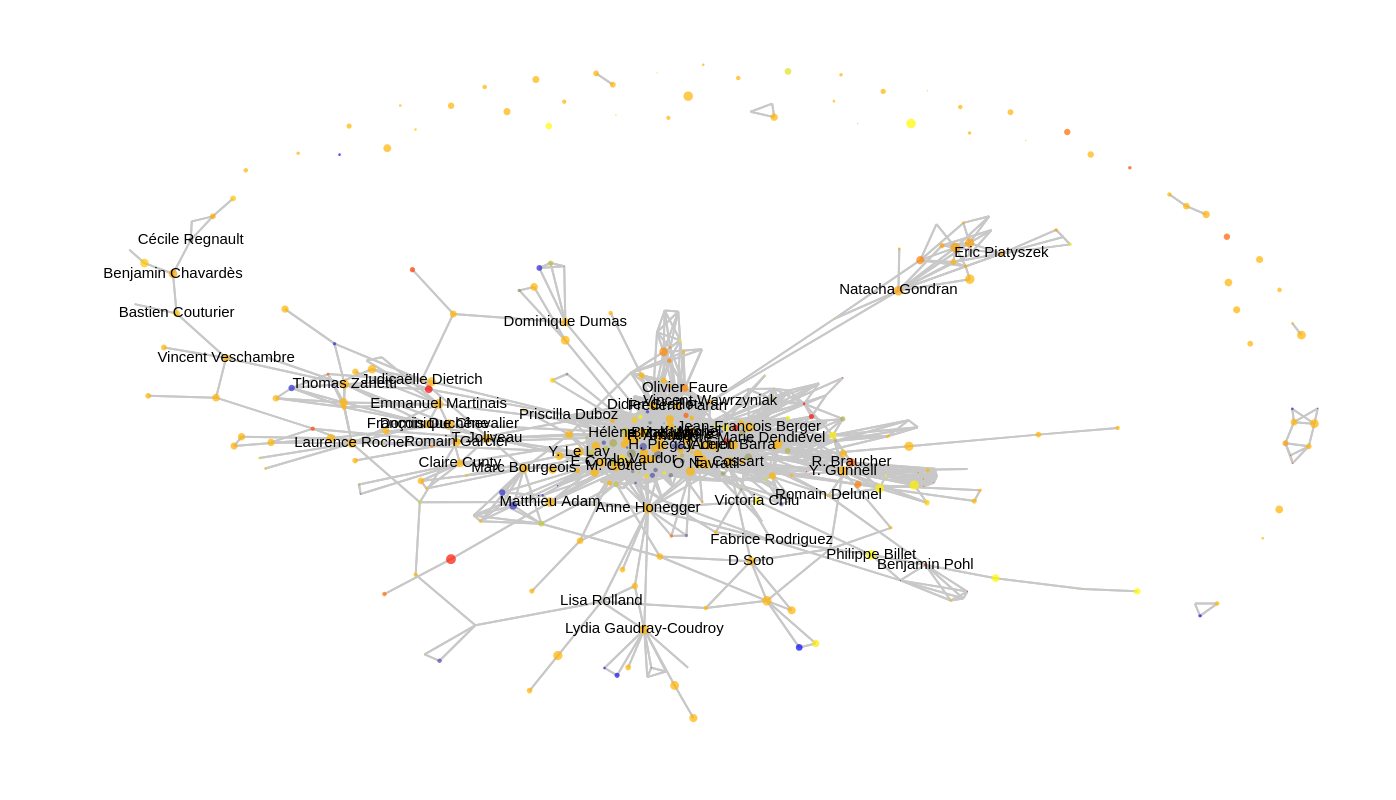
Si vous faites vous-même partie du laboratoire, vous pouvez peut-être distinguer (derrière les noms des personnes), les divers projets et thématiques qui se dessinent à travers le graphe. Néanmoins, pour mieux comprendre « de l’extérieur » ce qui sous-tend ces collaborations, il est possible d’indiquer, au lieu du nom des personnes, le lemme le plus spécifique de leur partie de corpus :
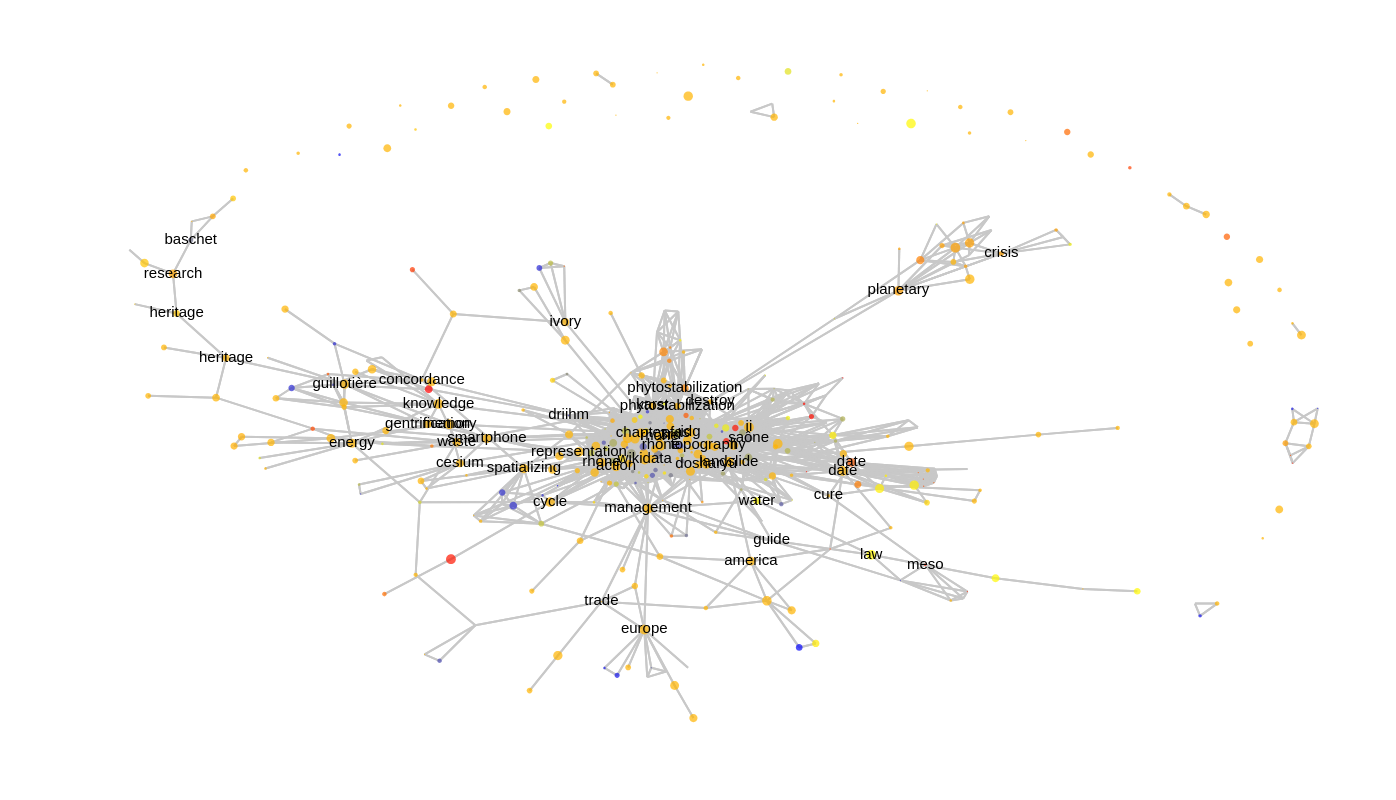
Hop, zoomons un peu (c’est un graphique plotly: on peu zoomer, exporter, s’attarder sur chaque noeud pour avoir des informations supplémentaires). Je constate ainsi que si dans ce corpus, mon terme spécifique est « wikidata » (et de fait, je suis la seule dans le laboratoire à m’être intéressée à ce sujet), je suis largement entourée de personnes s’intéressant de près aux cours d’eau (« Rhône », « PFAS », « phytostabilization », « saône », etc.): c’est bien l’objet thématique « cours d’eau » qui sous-tend la majeure partie des collaborations dans le laboratoire, même si d’autres parties du graphe se détachent.
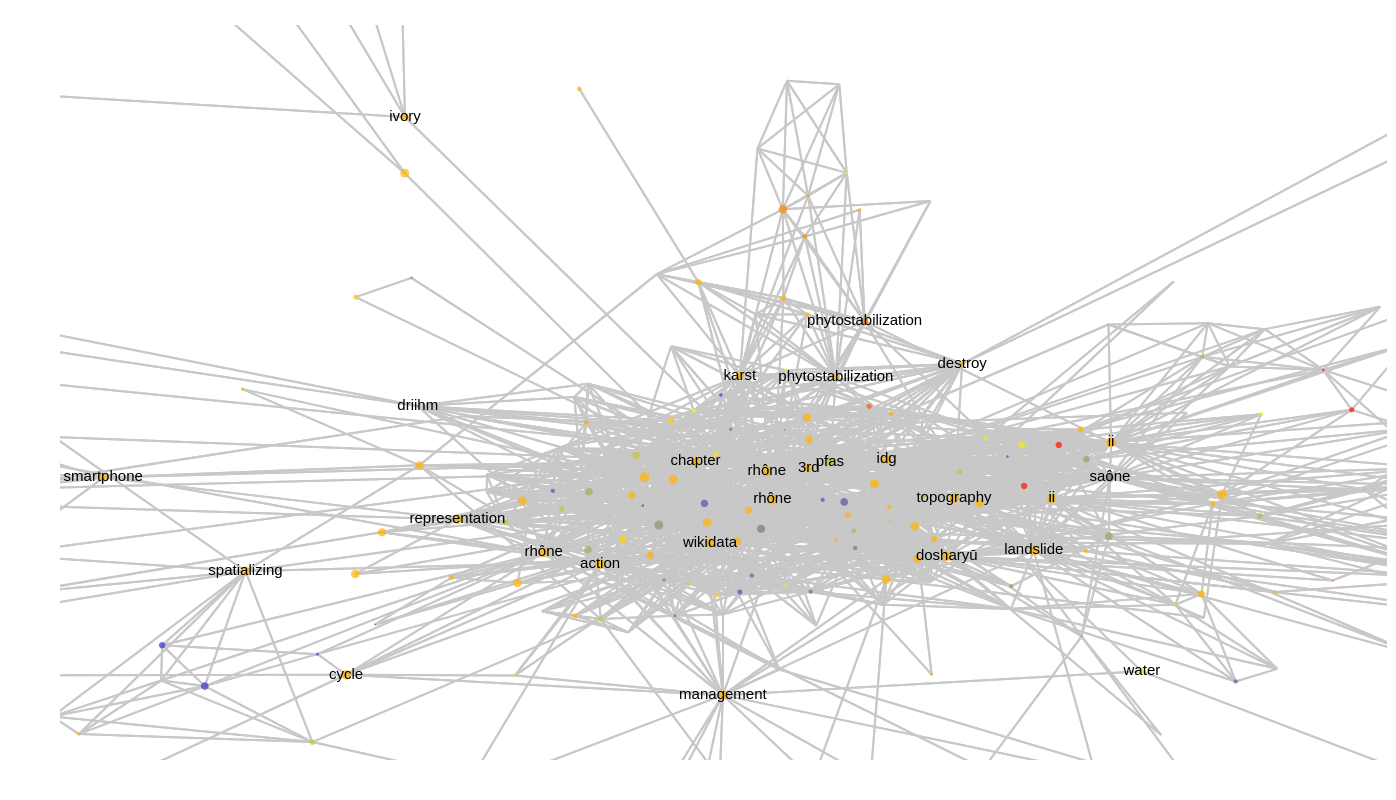
En filigrane de telles représentations (et du terme « valorisation »), se pose évidemment la question de la valeur intrinsèque de nos productions… Un graphe comme celui produit par HALtere met plus en avant les auteurs qui co-signent que ceux qui signent seuls (même si les auteurs les plus prolifiques, si isolés, sont représentés dans le graphe par un point à la marge). Or, en poussant ce principe à l’extrême, on pourrait imaginer qu’une logique de valorisation très « quantitativiste », mettant en avant les collaborations, pourrait amener des effets pervers, comme une tendance à faire co-signer les publications par de très nombreux auteurs, quand bien même leur apport réel à la publication serait très limité, voire inexistant. Cette tendance est bien réelle, mais découle davantage de pratiques de recherche que, je pense, de l’existence d’outils de visualisation adaptés. Par ailleurs, le fait d' »anonymiser » le graphe en affichant les éléments de discours plutôt que les personnes permet de raisonner sur ce qui donne forme à la collaboration plutôt que sur des logiques comptables liées aux stratégies de carrière et d’évaluation (au sens managerial du terme). Ainsi, l’appli ne se veut pas normative, elle ne dit pas « La recherche devrait être collaborative et interdisciplinaire »; elle dit: « Montrez ce qui de fait, dans votre recherche, est collaboratif et interdisciplinaire ».
Représenter les termes spécifiques
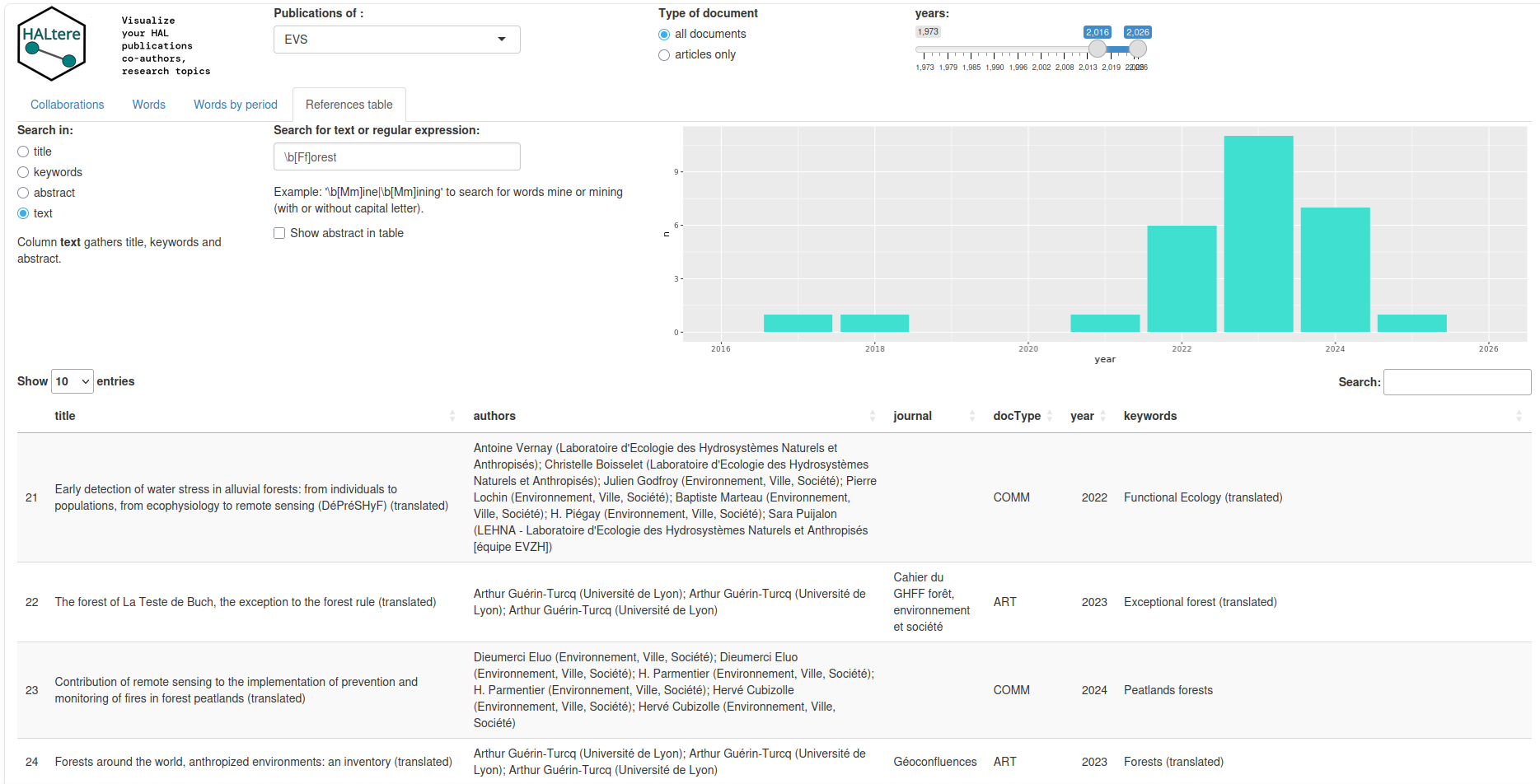
De manière générale, le traitement des informations textuelles (titre, mots-clés, abstract) permet de valoriser un bilan bibliographique d’une façon qui va un peu au-delà des indicateurs quantitatifs classiques. Examinons ainsi le module « Words by period »: il permet de mettre en regard deux périodes dans la production bibliographique en représentant les termes les plus fréquents pour chaque période, ou les plus spécifiques à chaque période. Voici par exemple les termes les plus spécifiques aux deux dernières périodes de 5 ans pour EVS:
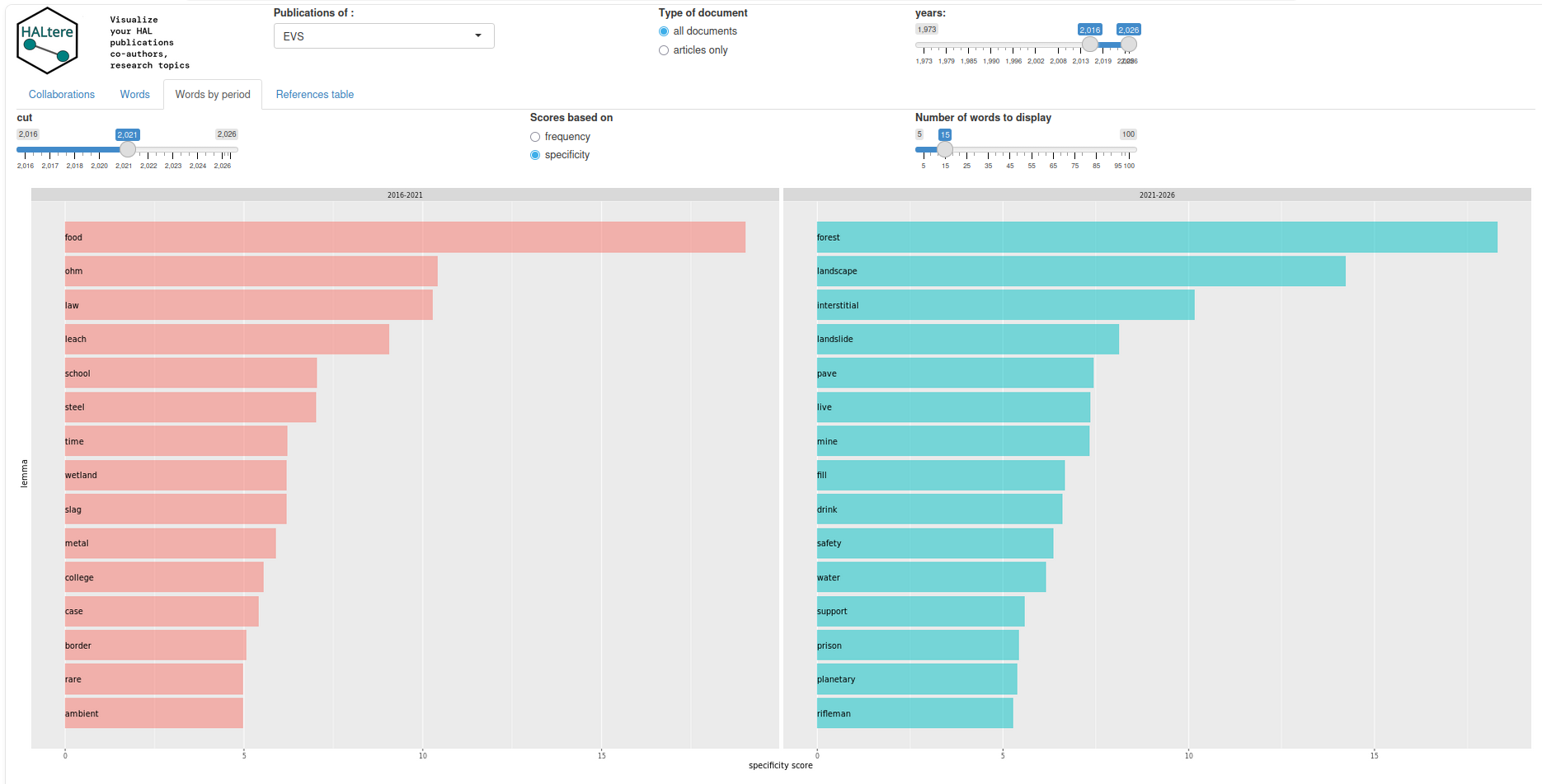
On constate ainsi que le terme le plus spécifique au dernier quinquennat d’EVS est « forest », suivi de près par « landscape ». Si l’on veut en savoir plus sur le contexte dans lequel ces termes sont utilisés, on peut consulterl’onglet « References table », et faire une petite recherche par expressions régulières (ici on récupère Forest* ou forest*), pour pouvoir avoir une idée des publications qui expliquent l’apparition de ce terme dans les lemmes les plus spécifiques de la période 2022-2027. On peut ainsi se faire une idée de thématiques émergentes, par exemple dans le cadre de l’évaluation d’un laboratoire.
Ce module est pour l’instant très rudimentaire et appellera sans doute des modifications (que vous pouvez appeler de vos voeux dans une Issue sur github, du reste).
Et en terme de développement?
Je ne suis pas la première (ni la dernière, probablement) à avoir l’idée de faire de la bibliométrie avec R, ni même à avoir l’idée de faire de la bibliométrie avec R sur la base des données de HAL (en ont témoigné quelques discussions que j’ai pu avoir autour de mon poster la semaine dernière), mais il me semble qu’HALtere peut être un premier jalon vers un travail plus avancé et généralisable sur la bibliométrie avec R, qui a le potentiel de rassembler un certain nombre d’ingénieurs de la donnée (et/ou de documentalistes), indépendamment de la discipline ou du domaine dans lequel ils exercent leur métier.
En effet, les bases de données bibliographiques sont multiples et les outils pour les interroger sont eux-mêmes divers et variés (certains étant orientés sur la récupération de la donnée, d’autres plus orientés sur l’analyse et la visualisation). Cette multiplicité de formats et d’ontologies n’est pas sans rappeler certaines problématiques propres au web sémantique et illustre l’intérêt qu’il pourrait y avoir à travailler sur l’interopérabilité des données bibliographiques. Ainsi, la bibliométrie sous R pourrait être un terrain de jeu et d’application privilégié pour une réflexion sur les ontologies et la structure des données, permettant d’articuler au mieux les outils bibliométriques existants (les « gros paquets » bibliometrix, openalexR,… et les petits comme HALtere), et les outils futurs (un « bibliverse »?).