
Ah, la joie de vous parler d’un package qui va me/vous simplifier la vie!… Aujourd’hui, il s’agit de dplyr, qui fait partie de la suite de packages tidyverse (qui comprend ggplot2, tidyr, stringr, lubridate et tellement d’autres) qui fait grand bruit en ce moment dans l’univ-R.
dplyr vise à simplifier la manipulation de tables de données à travers l’usage de cinq « verbes » (ou fonctions):
select, qui permet de sélectionner des variables (colonnes) du tableau de donnéesfilter, qui permet de filtrer les individus (lignes) du tableau de donnéesarrange, qui permet de réarranger le tableau de données selon l’ordre d’une ou plusieurs variablesmutate, qui permet de créer et ajouter de nouvelles variables (colonnes) au jeu de donnéessummarisequi permet de résumer plusieurs valeurs en une seule
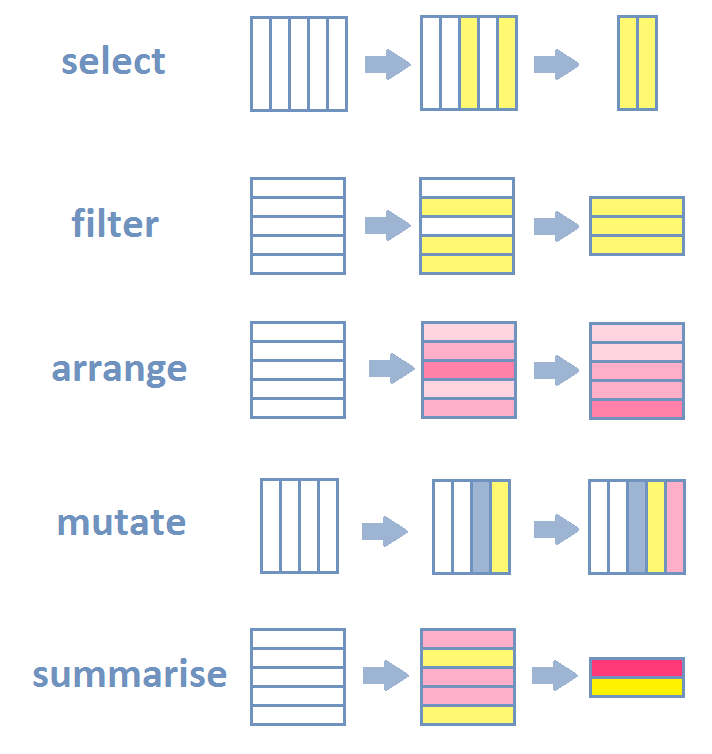
S’il est clair qu’il y avait déjà moyen de réaliser toutes ces opérations AVANT l’existence du package dplyr, il n’en demeure pas moins que ce package révolutionne la manipulation de données sous R en offrant des fonctions complètement intuitives et hyper pratiques pour réaliser des opérations qui pouvaient auparavant se révéler quelque peu rébarbatives…
Testons ces fonctions sur le jeu de données (fictif) suivant data_exemple.csv. Bien sûr, ce jeu de données traite de chats (de toutes les formes et de toutes les couleurs) car c’est le sujet le plus intéressant et le plus porteur qui soit.
catdata <- read.table("../../lise.vaudor/Rdata/Graphiques_avec_ggplot2/catdata.csv", sep=";", header=T)
print(dim(catdata))
## [1] 153 6
print(head(catdata))
## haircolor hairpattern sex weight age foodtype
## 1 red solid female 4.6 12 other
## 2 black tabby female 5.5 6 dry
## 3 white tabby female 5.6 8 wet
## 4 red tabby female 6.1 5 dry
## 5 brown solid female 5.3 7 dry
## 6 black tabby male 6.9 5 wet
Chargons le package dplyr:
require(dplyr)
select

Pour sélectionner certaines variables (colonnes) du jeu de données, rien de plus simple: on utilise la fonction select avec pour premier argument la table de données et arguments supplémentaires les variables que l’on souhaite sélectionner:
data=select(catdata, weight, foodtype, age)
print(head(data))
## weight foodtype age
## 1 4.6 other 12
## 2 5.5 dry 6
## 3 5.6 wet 8
## 4 6.1 dry 5
## 5 5.3 dry 7
## 6 6.9 wet 5
Il est aussi possible d’indiquer quelles variables on souhaite écarter:
data=select(catdata, - foodtype, -sex)
print(head(data))
## haircolor hairpattern weight age
## 1 red solid 4.6 12
## 2 black tabby 5.5 6
## 3 white tabby 5.6 8
## 4 red tabby 6.1 5
## 5 brown solid 5.3 7
## 6 black tabby 6.9 5
ou encore d’indiquer une plage de colonnes (soit par les noms de variables, soit par les numeros de colonne, par exemple ci-après on pourrait indiquer 1:4 au lieu de haircolor:weight)
data=select(catdata, haircolor:weight)
print(head(data))
## haircolor hairpattern sex weight
## 1 red solid female 4.6
## 2 black tabby female 5.5
## 3 white tabby female 5.6
## 4 red tabby female 6.1
## 5 brown solid female 5.3
## 6 black tabby male 6.9
On peut également (lorsque certains noms de variables sont génériques, par exemple « variable1″, »variable2″, »variable3″, »temperature_1930 », »temperature_1950, etc.) sélectionner l’ensemble des variables qui nous intéressent par des fonctions auxiliaires:
starts_withpour trouver les variables qui commencent par une certaine chaîne de caractèresends_withpour trouver les variables qui terminent par une certaine chaîne de caractèrescontainspour trouver les variables qui contiennent par une certaine chaîne de caractèresmatchespour trouver les variables qui correspondent à une expression régulièrenum_rangepour trouver des variables numérotées, dans une certaine gamme de valeursone_ofpour passer un vecteur de noms de variables
Je ne rentrerai pas dans le détail pour chacune d’entre elles (pour plus de détails vous pouvez consulter ce billet) mais voici tout de même un exemple avec starts_with:
data=select(catdata,starts_with("hair"))
print(head(data))
## haircolor hairpattern
## 1 red solid
## 2 black tabby
## 3 white tabby
## 4 red tabby
## 5 brown solid
## 6 black tabby
filter

Pour filtrer un tableau de données en fonction des valeurs de telle ou telle variable, on utilise la fonction filter. Ici, on cherche toutes les lignes qui remplissent la condition haircolor=="red":
data=filter(catdata,haircolor=="red")
print(dim(data));print(head(data))
## [1] 29 6
## haircolor hairpattern sex weight age foodtype
## 1 red solid female 4.6 12 other
## 2 red tabby female 6.1 5 dry
## 3 red solid female 2.3 3 dry
## 4 red colorpoint female 3.9 8 dry
## 5 red tabby female 4.6 7 dry
## 6 red tortoise female 5.9 8 wet
On peut combiner plusieurs conditions logiques (ET logique, par une virgule ou un &, OU logique, par l’opérateur |).
Pour les chats noirs qui pèsent plus de 7 kilos:
data=filter(catdata,haircolor=="black" , weight>7)
print(data)
## haircolor hairpattern sex weight age foodtype
## 1 black tipped male 7.5 4 dry
## 2 black colorpoint male 7.1 5 wet
## 3 black solid male 7.1 5 wet
Pour les chats particulièrement gros (plus de 7 kilos) OU particulièrement vieux (plus de 15 ans):
data=filter(catdata, weight>7 | age>15)
print(data)
## haircolor hairpattern sex weight age foodtype
## 1 black tipped male 7.5 4 dry
## 2 red colorpoint male 5.9 17 wet
## 3 black tabby female 1.9 17 dry
## 4 black colorpoint male 7.1 5 wet
## 5 black solid male 7.1 5 wet
## 6 black solid female 6.2 17 dry
arrange

Pour réarranger un tableau selon l’ordre d’une variable, on peut faire appel à la fonction arrange (ici, par exemple on réordonne catdata selon l’ordre croissant de weight):
data=arrange(catdata,weight)
print(head(data))
## haircolor hairpattern sex weight age foodtype
## 1 black tabby female 1.9 17 dry
## 2 red solid female 2.3 3 dry
## 3 white solid male 2.5 3 wet
## 4 black tabby female 2.6 10 dry
## 5 black solid female 2.8 11 dry
## 6 brown tipped female 2.9 8 dry
On peut également trier le tableau selon les niveaux d’une facteur:
data=arrange(catdata,sex)
print(head(data))
## haircolor hairpattern sex weight age foodtype
## 1 red solid female 4.6 12 other
## 2 black tabby female 5.5 6 dry
## 3 white tabby female 5.6 8 wet
## 4 red tabby female 6.1 5 dry
## 5 brown solid female 5.3 7 dry
## 6 black colorpoint female 5.5 4 wet
Il est en outre possible de choisir un deuxième (troisième, etc.) critère de tri:
data=arrange(catdata,sex,age)
print(head(data))
## haircolor hairpattern sex weight age foodtype
## 1 red solid female 2.3 3 dry
## 2 brown tipped female 6.1 3 dry
## 3 red tabby female 4.6 3 dry
## 4 red tabby female 4.5 3 dry
## 5 brown tipped female 4.4 3 dry
## 6 black tipped female 6.7 3 dry
et pour ordonner par ordre décroissant, on utilise desc:
data=arrange(catdata,sex,desc(age))
print(head(data))
## haircolor hairpattern sex weight age foodtype
## 1 black tabby female 1.9 17 dry
## 2 black solid female 6.2 17 dry
## 3 red tortoise female 3.4 13 wet
## 4 red solid female 4.6 12 other
## 5 black colorpoint female 5.4 12 other
## 6 black solid female 2.8 11 dry
mutate

Pour créer de nouvelles variables et les ajouter au tableau de données on peut utiliser la fonction mutate:
Voici par exemple comment procéder si je souhaite créer une nouvelle variable, « hair », en combinant les variables haircolor et hairpattern:
data=mutate(catdata,hair=paste(haircolor,hairpattern,sep="_"))
print(head(data))
## haircolor hairpattern sex weight age foodtype hair
## 1 red solid female 4.6 12 other red_solid
## 2 black tabby female 5.5 6 dry black_tabby
## 3 white tabby female 5.6 8 wet white_tabby
## 4 red tabby female 6.1 5 dry red_tabby
## 5 brown solid female 5.3 7 dry brown_solid
## 6 black tabby male 6.9 5 wet black_tabby
ou si je souhaite connaître « l’âge équivalent humain » de mes chats:
data=mutate(catdata,age_humain=age*7)
print(head(data))
## haircolor hairpattern sex weight age foodtype age_humain
## 1 red solid female 4.6 12 other 84
## 2 black tabby female 5.5 6 dry 42
## 3 white tabby female 5.6 8 wet 56
## 4 red tabby female 6.1 5 dry 35
## 5 brown solid female 5.3 7 dry 49
## 6 black tabby male 6.9 5 wet 35
summarise

Last but not least, imaginons que je souhaite calculer quelques statistiques un peu basiques sur mon jeu de données. Je peux pour ce faire utiliser la fonction summarise.
Par exemple, pour calculer l’âge et le poids moyen de mes chats:
data=summarise(catdata,mean_weight=mean(weight), mean_age=mean(age))
print(data)
## mean_weight mean_age
## 1 4.891503 6.124183
Et surtout, si je souhaite calculer une statistique pour différents groupes (définis ici, par exemple, par la variable sex), je vais le spécifier dans l’argument spécifiant la table de données, à l’aide de la fonction group_by:
data=summarise(group_by(catdata,sex,haircolor),mean_weight=mean(weight), mean_age=mean(age))
print(data)
## Source: local data frame [8 x 4]
## Groups: sex [?]
##
## sex haircolor mean_weight mean_age
## <fctr> <fctr> <dbl> <dbl>
## 1 female black 4.634286 6.885714
## 2 female brown 4.833333 5.416667
## 3 female red 4.675000 6.450000
## 4 female white 4.900000 6.250000
## 5 male black 5.245455 5.681818
## 6 male brown 5.230000 6.000000
## 7 male red 4.822222 7.111111
## 8 male white 4.600000 5.200000
Il est en outre possible de travailler avec des groupements définis par plusieurs variables, et (évidemment) avec des fonctions autres que la moyenne!
data=summarise(group_by(catdata,sex,haircolor),
min_weight=min(weight),
max_weight=max(weight),
nbre_individus=n(),
nbre_hairpattern=n_distinct(hairpattern)
)
print(data)
## Source: local data frame [8 x 6]
## Groups: sex [?]
##
## sex haircolor min_weight max_weight nbre_individus nbre_hairpattern
## <fctr> <fctr> <dbl> <dbl> <int> <int>
## 1 female black 1.9 7.0 35 5
## 2 female brown 2.9 6.3 12 4
## 3 female red 2.3 6.6 20 5
## 4 female white 3.2 6.0 8 3
## 5 male black 3.5 7.5 44 5
## 6 male brown 4.2 6.3 10 4
## 7 male red 3.8 6.1 9 5
## 8 male white 2.5 6.4 15 5
Remarquez au passage l’usage des fonctions auxiliaires n() et n_distinct() qui permettent simplement de compter le nombre d’individus dans chaque groupe ainsi que le nombre de niveaux distincts d’une variable pour un groupe.
Chainage
Vous avez vu que les fonctions de dplyr permettaient de faire toutes sortes d’opérations sur les tableaux de données. Il est bien entendu possible de les combiner pour réaliser des opérations complexes…
Imaginons par exemple que l’on souhaite répondre à une question telle que « Quel est le sexe et le poids du plus gros chat roux qui mange des croquettes? »
Pour répondre à cette question, je pourrais par exemple (il y a en fait plusieurs possibilités):
- sélectionner les variables qui m’intéressent, à savoir, sex, haircolor, weight, et foodtype puis
- filtrer les lignes pour n’avoir que les chats roux qui mangent des croquettes puis
- filtrer pour ne garder que le plus gros chat
Classiquement, pour coder cette chaîne d’opérations sous R, on procéderait de la manière suivante:
data1=select(catdata, sex,haircolor,weight,foodtype)
data2=filter(data1, haircolor=="red",foodtype=="dry")
data3=filter(data2, weight==max(weight))
print(data3)
## sex haircolor weight foodtype
## 1 female red 6.6 dry
Ainsi, le plus gros chat roux mangeant des croquettes est une femelle. (Pour ceux qui, connaissant le petit Bertrand s’étonneraient de ce résultat je précise à nouveau qu’il s’agit d’un jeu de données fictif…)
{kind=link}
Si je souhaitais réaliser cet enchaînement de commandes en une seule opération, et ainsi éviter la création d’objets intermédiaires data1, data2, etc., voici (classiquement) comment il faudrait procéder:
filter(
filter(
select(
catdata, sex,haircolor,weight,foodtype
),
haircolor=="red",foodtype=="dry"
),
weight==max(weight)
)
## sex haircolor weight foodtype
## 1 female red 6.6 dry
Il faut avouer que ce n’est ni très pratique à écrire, ni très facile à relire, car il faut faire un petit effort mental pour retracer l’ordre des opérations (de l’intérieur vers l’extérieur) là où en « syntaxe humaine » on envisageait plutôt le chaînage de ces opérations de manière linéaire (on fait ça puis ça puis ça).
Eh bien, dplyr permet de se rapprocher de cette « syntaxe humaine » en permettant d’utiliser un opérateur (l’opérateur « pipe ») qui s’écrit de la manière suivante : %>% et que l’on pourrait (en gros) traduire par « puis »…
Voyez plutôt comment le code ci-dessus peut être simplifié par l’usage de cet opérateur:
select(catdata, sex,haircolor,weight,foodtype) %>%
filter(haircolor=="red",foodtype=="dry") %>%
filter(weight==max(weight))
## sex haircolor weight foodtype
## 1 female red 6.6 dry
Les 3 lignes ci-dessus forment une seule commande, qui exécute exactement les mêmes opérations que les 9 lignes de la commande précédente, mais de manière beaucoup plus concise et claire…
Remarquez qu’avec l’usage du pipe, le premier argument -qui devrait être une table- disparaît de l’appel aux fonctions filter et arrange. En effet, le pipe envoie le résultat de la ligne précédente comme premier argument de la ligne suivante (i.e. le résultat de select() est envoyé comme premier argument de filter(..., haircolor=="red",foodtype=="dry") puis le résultat de filter(...,haircolor=="red",foodtype=="dry")est envoyé comme premier argument de filter(..., weight==max(weight)).
Si au tout début la syntaxe que permet le pipe est un peu déstabilisante (une fois qu’on a appris la syntaxe de R « classique ») elle devient vite addictive tant elle permet de faire en deux coups de cuillère à pot des chaînes d’opérations complexes…
Pour votre culture personnelle, sachez que cet opérateur pipe %>% qui pourrait bien devenir votre nouveau meilleur ami provient d’un autre package R, magrittR, qui lui même fait partie de la suite de packages tidyverse que j’évoquais au tout début de ce billet…
10 Comments
nnnn
bravo .j ‘ai bien compris les fonctions de ce package , votre explications est bien détaillée . rien à ajouter .
belhouari
Merci
C’est clair
BarbelKing
Super blog et très bon article! Cependant, pour les prochaines fois, pouvez-vous remplacer les chats par des poissons? Nos ancêtres à tous.
Merci
lvaudor
Merci BarbelKing pour ce retour. Les poissons, c’est bien sympa, mais c’est clairement moins cute and fluffy que les chats. Aussi ai-je un peur qu’ils fassent un flop auprès d’un public moins averti que vous. Néanmoins, j’essaierai à l’avenir de prendre en compte votre remarque et de faire un effort pour la représentation de la biodiversité sur ce blog.
Bonne journée à vous!
Cheikh
Merciiiiiiiiii
Claire
Très clair! Merci beaucoup!
Nina
Merci beaucoup. Je débute R et c’est bien plus clair que d’autres sites plus « pro ».
Mathilde Hutin
Bonjour et merci pour ces explications! Comme d’autres avant moi, je les trouve bien plus claires que celles d’autres sites!
Cependant j’ai une question:
Admettons que je veuille utiliser une fonction type « contains » avec « filter ». Par exemple, filtrer pour supprimer les lignes où « haircolor » contains « ow ». Comment feriez-vous?
J’ai essayé quelque chose comme
new_filename <- data=filter(filename$column, contains!="abc")
… mais sans surprise ça ne marche pas:
Error in UseMethod("filter_") :
no applicable method for 'filter_' applied to an object of class "factor"
Merci d'avance pour votre aide!
lvaudor
Merci 🙂
Alors l’idée c’est de sélectionner des lignes en se basant sur le contenu de la chaîne de caractère: la solution est donc à rechercher du côté de la manipulation de « strings » par exemple à l’aide du package stringr (il y a un billet sur ce package sur ce blog).
Du coup la commande que vous recherchez serait quelque chose de ce genre:
newdata= data %>% filter(stringr::str_detect(column, « abc »))
(on filtre le jeu de données « data » pour ne conserver que les lignes dans lesquelles on détecte le pattern « abc » dans la colonne « column »)
Koffi Frederic
Merci infiniment