
Chers lecteurs, bonjour!
Aujourd’hui, je vais vous parler du package janitor, un package qui comprend notamment (mais pas seulement) un certain nombre de fonctions pour améliorer vos tableaux de contingence. En Anglais, “janitor” veut dire (plus ou moins) “homme à tout faire”. Et en effet, outre les tâches liées à la mise en forme de ces tableaux, le package janitor vise à prendre en charge pour vous un certain nombre de tâches aussi variées que pénibles…
![]()
Jetons un coup d’oeil à l’ensemble des fonctions comprises dans ce package (je fais ça à l’aide de mon package flowrpowr (http://perso.ens-lyon.fr/lise.vaudor/certains-packages-sont-comme-des-fleurs/):
library(janitor)
library(flowrpowr)
flowrpowr::flowr_package("janitor")
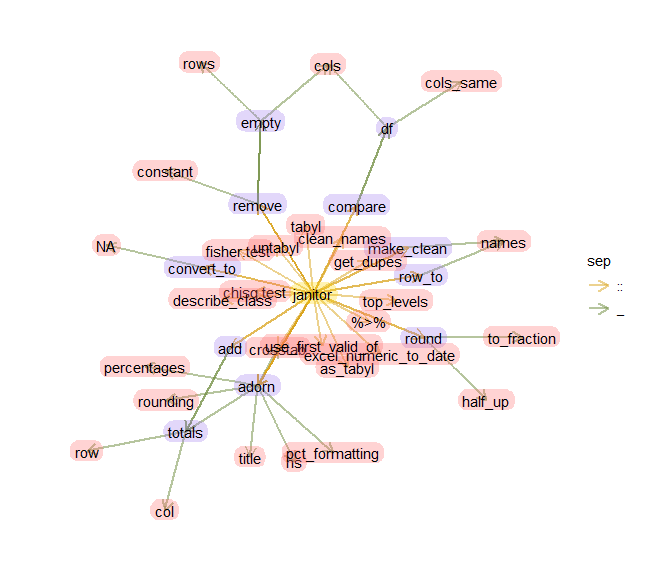
Opérations sur les tables de contingences
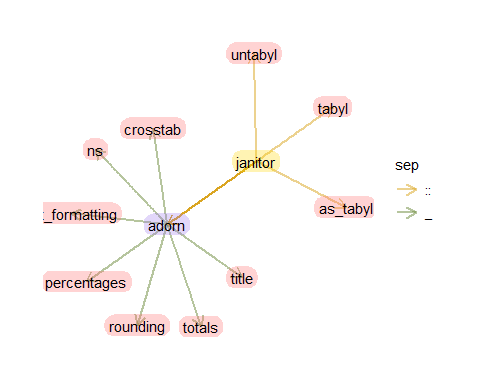
Les éléments apparaissant ci-dessous sont ceux relatifs aux tables de contingence (fonctions tabyl et consorts, fonctions de type adorn_xxx() –adorn_title(),adorn_ns(),adorn_rounding(),etc.-). Les autres fonctions sont toutes celles qui réalisent des opérations sur les données (en général, mais pas seulement, en lien avec le nettoyage de tableaux).
flowrpowr::flowr_package("janitor", element=c("adorn","tabyl"))
La fonction tabyl() est, en quelque sorte, l’équivalent (amélioré) de la fonction table(), qui compte des effectifs par classe. Mais là où table() travaille sur des vecteurs (ou facteurs), tabyl() prend pour premier argument un tableau de données. C’est peut-être un détail pour vous, mais en fait ça veut dire beaucoup: c’est le signe que le package janitor est “pipe-compatible” (et donc “dplyr-compatible”) (puisque le premier argument des fonctions est un jeu de données, on peut enchaîner les opérations à l’aide des “pipes” %>%).
Voyez plutôt:
tabyl(mtcars,cyl) # en appel "classique"
## cyl n percent
## 4 11 0.34375
## 6 7 0.21875
## 8 14 0.43750
mtcars %>%
tabyl(cyl) # en appel "pipé"
## cyl n percent
## 4 11 0.34375
## 6 7 0.21875
## 8 14 0.43750
Remarquez en outre que, pour une variable, tabyl() vous affiche diligemment les proportions (percent) en plus des effectifs (n).
Comme table(), tabyl() sait aussi compter des effectifs croisés:
mtcars %>%
tabyl(cyl,am)
## cyl 0 1
## 4 3 8
## 6 4 3
## 8 12 2
L’ensemble des fonctions adorn_xxx() vise à mettre en forme les tableaux d’effectifs produits par tabyl().
On peut par exemple rajouter une colonne correspondant aux effectifs totaux:
tab=mtcars %>%
tabyl(gear, cyl) %>%
adorn_totals("col")
tab
## gear 4 6 8 Total
## 3 1 2 12 15
## 4 8 4 0 12
## 5 2 1 2 5
On peut afficher les pourcentages plutôt que les effectifs (ici pourcentages par ligne)
tab=tab %>%
adorn_percentages("row")
tab
## gear 4 6 8 Total
## 3 0.06666667 0.1333333 0.8 1
## 4 0.66666667 0.3333333 0.0 1
## 5 0.40000000 0.2000000 0.4 1
On peut limiter le nombre de digits dans l’affichage:
tab=tab %>%
adorn_pct_formatting(digits=2)
tab
## gear 4 6 8 Total
## 3 6.67% 13.33% 80.00% 100.00%
## 4 66.67% 33.33% 0.00% 100.00%
## 5 40.00% 20.00% 40.00% 100.00%
On peut afficher, en plus des pourcentages, les effectifs:
tab=tab %>%
adorn_ns()
tab
## gear 4 6 8 Total
## 3 6.67% (1) 13.33% (2) 80.00% (12) 100.00% (15)
## 4 66.67% (8) 33.33% (4) 0.00% (0) 100.00% (12)
## 5 40.00% (2) 20.00% (1) 40.00% (2) 100.00% (5)
On peut rajouter le nom de la deuxième variable:
tab=tab %>%
adorn_title()
tab
## cyl
## gear 4 6 8 Total
## 3 6.67% (1) 13.33% (2) 80.00% (12) 100.00% (15)
## 4 66.67% (8) 33.33% (4) 0.00% (0) 100.00% (12)
## 5 40.00% (2) 20.00% (1) 40.00% (2) 100.00% (5)
Pour en savoir plus sur les fonctionnalités des “tabyls”, vous pouvez aller voir la vignette fournie par les auteurs de janitor (vous pouvez l’ouvrir en faisant vignette("tabyls") dans votre console une fois que vous avez installé le package).
Nettoyage de tableaux de données
Je ne vais pas aborder l’ensemble des autres fonctions de janitor, mais, pour aller à l’essentiel, disons que ces fonctions réalisent quelques tâches “de routine” pour nettoyer les tableaux de données. Par exemple:
flowrpowr::flowr_package("janitor",element=c("compare|remove|clean|^round"))
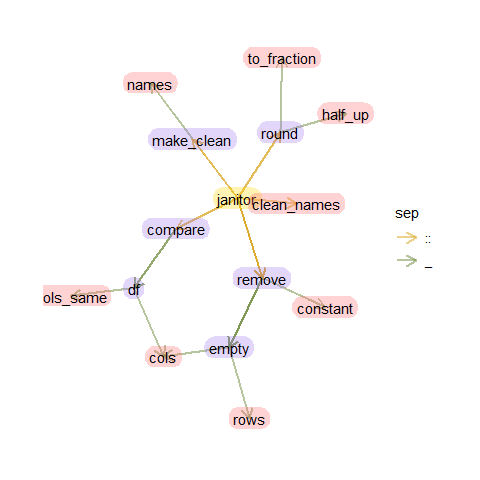
-
les fonctions
remove_xxx()retirent les colonnes qui contiennent une valeur constante (remove_constant()), ou les colonnes ou lignes complètement vides (remove_empty_cols(),remove_empty_rows()) -
les fonctions
compare_df_cols...()comparent les colonnes de deux tableaux (compare_df_cols()) et déterminent si, en l’état ils peuvent être “recollés” en semble par une opération de typebind_rows()ourbind()(compare_df_cols_same())
-les fonctions round_xxx() constituent des améliorations de la fonction round() consistant à arrondir de manière systématique vers le haut les valeurs (round_half_up()) ou à arrondir à une fraction près (round_to_fraction())
- les fonctions
...clean_names()permettent de nettoyer des noms (make_clean_names()) et notamment les noms de colonnes des tableaux (clean_names()). C’est, je pense, cette fonctionclean_names()que j’utilise le plus fréquemment dans le packagejanitor. Si vous aussi vous êtes amenés à travailler avec des tableaux dont les noms de colonnes sont à coucher dehors, vous comprendrez pourquoi… Admirez plutôt:
tib=tibble("TempérDegCelsius"=NA,
"précipit (mm/24h)"=NA,
"succès_prob(%)"=NA,
"Fiabilité.Estim"=NA)
tib
## # A tibble: 1 x 4
## TempérDegCelsius `précipit (mm/24h)` `succès_prob(%)` Fiabilité.Estim
## <lgl> <lgl> <lgl> <lgl>
## 1 NA NA NA NA
tib %>% clean_names()
## # A tibble: 1 x 4
## temper_deg_celsius precipit_mm_24h succes_prob_percent fiabilite_estim
## <lgl> <lgl> <lgl> <lgl>
## 1 NA NA NA NA
A partir de noms de colonnes très hétérogènes et comprenant un certain nombre de caractères spéciaux, la fonction clean_names() produit des noms homogènes et commodes à utiliser dans R. Par défaut, la casse est de type “serpent” (case="snake"): tous les mots sont écrits en minuscule, séparés par un underscore _. Alternativement, et si telle est votre habitude, vous pouvez demander à ce que vos noms de variables soient en casse “petit chameau”, “grand chameau” ou “serpent criard”, etc., etc. (j’adore ces dénominations :-)…).
tib %>% clean_names(case="small_camel")
## # A tibble: 1 x 4
## temperDegCelsius precipitMm24H succesProbPercent fiabiliteEstim
## <lgl> <lgl> <lgl> <lgl>
## 1 NA NA NA NA
tib %>% clean_names(case="big_camel")
## # A tibble: 1 x 4
## TemperDegCelsius PrecipitMm24H SuccesProbPercent FiabiliteEstim
## <lgl> <lgl> <lgl> <lgl>
## 1 NA NA NA NA
tib %>% clean_names(case="screaming_snake")
## # A tibble: 1 x 4
## TEMPER_DEG_CELSIUS PRECIPIT_MM_24H SUCCES_PROB_PERCENT FIABILITE_ESTIM
## <lgl> <lgl> <lgl> <lgl>
## 1 NA NA NA NA
Citation
Merci de citer ce billet de la manière suivante:
## Vaudor L (2020). "Janitor: nettoie-moi cette table (et qu'elle brille!)." _R-atique: Analyse de données avec R_. <URL: http://perso.ens-lyon.fr/lise.vaudor/janitor-nettoie-moi-cette-table-et-que-ca-brille/>.
## @Misc{vaudor_janitor,
## author = {Lise Vaudor},
## title = {Janitor: nettoie-moi cette table (et qu'elle brille!)},
## month = {jun},
## year = {2020},
## journal = {R-atique: Analyse de données avec R},
## type = {blog},
## url = {http://perso.ens-lyon.fr/lise.vaudor/janitor-nettoie-moi-cette-table-et-que-ca-brille/},
## }