
Il y a quelques mois, je postais un billet concernant la manipulation de tableaux de données avec dplyr, concernant plus particulièrement la réalisation de 5 opérations de base sur des tableaux (sélection de colonnes avec select(), filtrage de lignes avec filter, réarrangement des lignes avec arrange, création ou modification de colonnes avec mutate, et synthétisation statistique avec summarise).
Aujourd'hui, je vais aborder un type d'opération différent, à savoir, les jointures de tableaux (i.e., grosso modo, comment "coller" deux tableaux ensemble pour en faire un seul).
Pour ce faire, plutôt que de faire mes propres petits graphiques explicatifs (aussi beaux et roses soient-ils), je vais utiliser ceux fournis par RStudio et (plus particulièrement) Garrett Grolemund dans leur cheatsheet concernant la transformation de données avec dplyr. Merci à eux, donc, d'abord pour avoir créé cette "antisèche" très utile, et ensuite pour m'avoir autorisée à la découper en petits morceaux et la réutiliser à l'envi ?...
Avant toute chose, chargeons donc le package dplyr:
library(dplyr)
Combinaison de deux tableaux
Dans une version très très simple, on peut simplement accoler ensemble deux tableaux, soit en colonnes (avec bind_cols()), soit en lignes (avec bind_rows).
Accolement de deux tableaux, en colonnes:
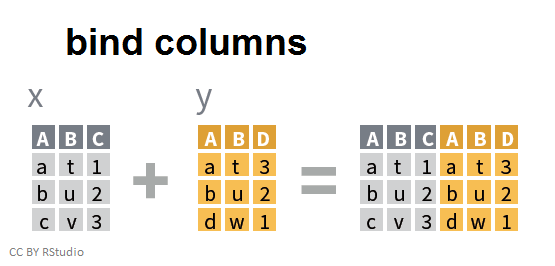
Dans ce premier cas, il est évidemment nécessaire que les individus (et l'ordre dans lequel ils apparaissent dans les deux tables) correspondent.
Avec les deux tables x et y:
bind_cols(x, y)
## A B C A1 B1 D
## 1 a t 1 a t 3
## 2 b u 2 b u 2
## 3 c v 3 d w 1
Les noms de variables de la deuxième table, y, sont ici modifiées pour éviter que plusieurs variables aient le même nom.
Accolement de deux tableaux, en lignes:
Dans ce second cas, il est nécessaire que les variables (et l'ordre dans lequel elles apparaissent) correspondent.
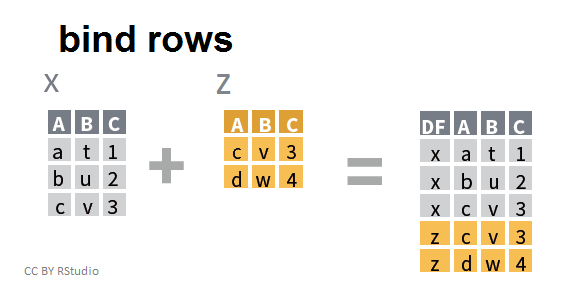
bind_rows(x,z)
## A B C
## 1 a t 1
## 2 b u 2
## 3 c v 3
## 4 c v 3
## 5 d w 4
Si l'on souhaite conserver une trace, dans le tableau final, de l'origine des informations, on peut rajouter un identifiant de tableau de la manière suivante:
bind_rows(x,z,.id="myID")
## myID A B C
## 1 1 a t 1
## 2 1 b u 2
## 3 1 c v 3
## 4 2 c v 3
## 5 2 d w 4
Par défaut, les identifiants seront simplement 1 et 2.
Si vous souhaitez spécifier des identifiants différents (par exemple, "x", et "z" plutôt que 1 et 2), vous pouvez procéder comme suit:
bind_rows(list(x=x,z=z), .id="myID")
## myID A B C
## 1 x a t 1
## 2 x b u 2
## 3 x c v 3
## 4 z c v 3
## 5 z d w 4
Il est également possible d'accoler deux tableaux en lignes en utilisant l'idée d'union, d'intersection et de différence...
"Intersection" de deux tableaux
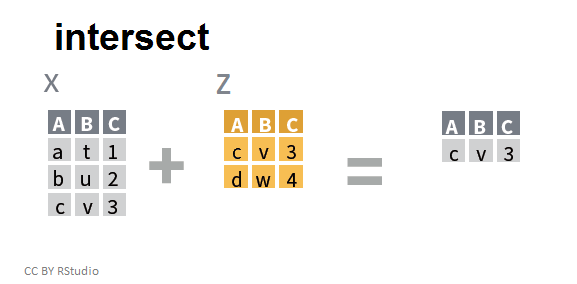
intersect(x,z)
## A B C
## 1 c v 3
Dans le cas d'une intersection, on ne retient que les individus communs aux deux tableaux.
"Union" de deux tableaux
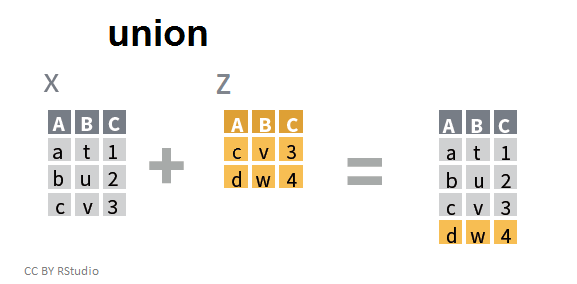
union(x,z)
## A B C
## 1 c v 3
## 2 a t 1
## 3 b u 2
## 4 d w 4
A la différence d'un simple appel à bind_rows(), union() retire les lignes redondantes.
"Différence" de deux tableaux
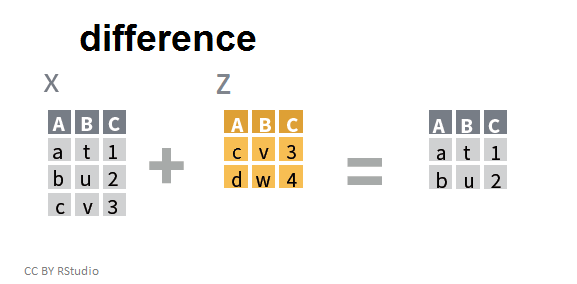
setdiff(x,z)
## A B C
## 1 a t 1
## 2 b u 2
setdiff() ne retient que les lignes qui apparaissent dans le premier tableau et non dans le second.
Jointures
Dans une jointure, on "colle ensemble" des tableaux dont les lignes ne correspondent pas forcément (par exemple, à une information située en ligne 33 du premier tableau, correspond une information située en ligne 158 du deuxième tableau).
On peut distinguer plusieurs types de jointures.
Jointure à gauche
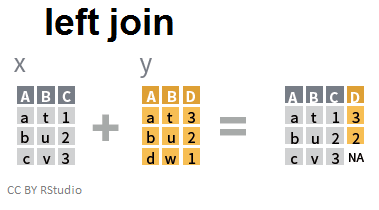
Dans une jointure à gauche, on adjoint aux informations de la table de gauche les informations issues de la table de droite:
left_join(x,y)
## Joining, by = c("A", "B")
## A B C D
## 1 a t 1 3
## 2 b u 2 2
## 3 c v 3 NA
Ainsi, c'est le tableau de gauche qui définit les individus du tableau en sortie (quand bien-même il n'y a pas d'information à leur sujet dans le tableau de droite: remarquez ainsi la donnée manquante dans la colonne D pour le 3ième individu...)
En mettant un peu de bazar dans les tables (autant que possible dans une table de 3 lignes ?),
x_mess=x[c(3,2,1),]
print(x_mess)
## A B C
## 3 c v 3
## 2 b u 2
## 1 a t 1
y_mess=y[c(1,3,2),]
print(y_mess)
## A B D
## 1 a t 3
## 3 d w 1
## 2 b u 2
on voit mieux l'intérêt de la jointure : voyez donc comme elle a bien sur faire le lien entre les deux tables malgré le bazar qu'on y a mis:
left_join(x_mess,y_mess)
## Joining, by = c("A", "B")
## A B C D
## 1 c v 3 NA
## 2 b u 2 2
## 3 a t 1 3
Ici, on n'a pas précisé pas quelle ligne de x allait avec quelle ligne de y: de ce fait, la fonction a simplement supposé que les variables communes aux deux tableaux (ici A et B) permettaient d'identifier les individus et de relier les informations des deux tables.
Il est bien sûr possible (voire recommandé) de préciser explicitement quelles sont les identifiants qui permettent de faire ce lien entre les deux tables, à travers l'argument by:
left_join(x,y, by=c("A","B"))
## A B C D
## 1 a t 1 3
## 2 b u 2 2
## 3 c v 3 NA
Jointure à droite
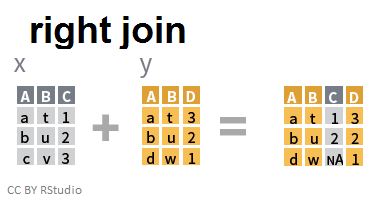
Dans une jointure à droite, on adjoint aux informations de la table de droite les informations issues de la table de gauche.
right_join(x,y,by=c("A","B"))
## A B C D
## 1 a t 1 3
## 2 b u 2 2
## 3 d w NA 1
Ainsi, c'est le tableau de droite qui définit les individus du tableau en sortie (quand bien-même le tableau de gauche ne contiendrait pas d'informations à leur sujet: remarquez ainsi la donnée manquante dans la colonne C pour le 3ième individu... ).
Jointure interne
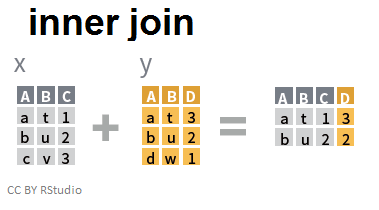
Dans une jointure interne, ne sont conservés que les individus communs aux deux jeux de données:
inner_join(x,y,by=c("A","B"))
## A B C D
## 1 a t 1 3
## 2 b u 2 2
Jointure complète
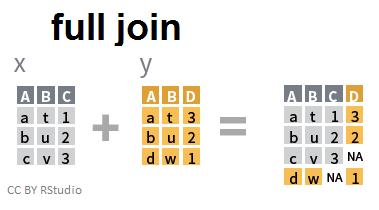
Dans le cas d'une jointure complète, au contraire d'une jointure interne, on conserve l'ensemble des individus décrits par l'un ou l'autre des jeux de données...
full_join(x,y,by=c("A","B"))
## A B C D
## 1 a t 1 3
## 2 b u 2 2
## 3 c v 3 NA
## 4 d w NA 1
Identifiants portant des noms différents
Il arrive qu'une variable identifiant les individus n'ait pas le même nom dans les deux tableaux... Dans ce cas on peut préciser de faire correspondre à une variable du premier tableau, une autre variable du deuxième tableau, de la manière suivante:
# Fait correspondre x$C et y$D:
full_join(x,y,by=c("C"="D"))
## A.x B.x C A.y B.y
## 1 a t 1 d w
## 2 b u 2 b u
## 3 c v 3 a t
22 Comments
Liorel
Le principal truc qui me chagrine avec dplyr, c'est qu'il ne propose aucune fonction qui ne soit pas dans base, Du coup, je préfère passer par un bon vieux cbind ou rbind, ou par un merge : en effet, right join et left join sont plus obscurs pour le débutant que merge(x, y, by.x=..., by.y=..., all.x=..., all.y=...). Right join et left join sont des conventions, tandis que les options de merge sont explicites, et pour citer Guido Van Rossum : Explicit is better than implicit.
Au final, une seule fonction de base (le package base) a été découpée en plusieurs fonctions dans dplyr, et je n'arrive pas à trouver un cas d'utilisation où on gagne réellement du temps à apprendre dplyr plutôt que d'utiliser les fonctions de base. Tu aurais un tel exemple ?
Après c'est peut-être juste moi. Je trouve fréquemment des enthousiastes de dplyr sur internet, rarement des enthousiastes de base. Peut-être que mon background de linuxien, habitué à avoir un programme pour chaque tâche, mais qui la fasse bien et qui comprenne plein d'options pour modifier tel ou tel comportement, ressort ici, alors que d'autres préféreront avoir une fonction différente pour chaque aspect d'une même tâche. On est vraiment dans la psychologie du dev : rien n'est impossible avec tel ou tel package, il n'y a même pas de réponse optimale dans tous les cas de figure, juste des préférences personnelles (d'ailleurs, on pourrait remplacer dplyr et base par LibreOffice Writer/Word et par LaTeX, ou l'inverse, et ce texte resterait juste).
Je profite de ce long commentaire pour pointer un élément beaucoup plus concret : le flux RSS ! Contrairement à ce que pourrait laisser croire mon commentaire, j'apprécie suffisamment ce blog et les conseils souvent utiles que j'y trouve, et j'ai essayé de le mettre dans mon lecteur de flux : plantage et perte de la liste des flux déjà enregistrés. Il semblerait que feedburner fasse planter les clients RSS desktop.
Si je me souviens bien, il y a quelques mois, il n'y avait même pas de RSS : c'est donc déjà bien qu'il y en ait maintenant :). Je ne connais rien à WordPress, mais n'est-il pas capable de générer lui-même un RSS sans passer par feedburner ?
lvaudor
Bonjour!
Merci pour ces commentaires!
dplyr ne permet certes pas de faire des choses qui seraient impossibles avec base, mais il permet de le faire tellement plus aisément que (de mon point de vue) ce serait un peu masochiste de ma part de faire sans une fois qu'on y a goûté (mais chacun ses préférences ;-)!!).
Pour ma part, en tant que formatrice, je suis souvent confrontée au dilemne "Enseigner la méthode de base pour que les élèves puissent à terme s'en sortir dans toutes les situations" vs "Enseigner le tidyverse pour que les élèves puissent s'en sortir là maintenant". Eh bien, ce serait peut-être différent si je m'adressais à un autre type de public (plus geek, plus linuxien, davantage habitué à la ligne de commande et à la programmation), mais en l'état actuel des choses, je pense que la plupart des gens que je forme sortiraient extrêmement frustrés et découragés si j'optais pour cette première option "à la dure". Et vraisemblablement, ils se (re)tourneraient vers d'autres logiciels (comme Excel)...
En revanche, je vous l'accorde, les fonctions de jointure dplyr ne sont pas forcément plus intéressantes qu'un simple "merge" de base. J'ai malgré cela choisi d'aborder ces fonctions dans un post car j'utilise dplyr pour les autres manips de tableau, et parce que j'utilise la cheatsheet dplyr/tidyr en formation qui présente ces opérations de manière très pédagogue.
Pour ce qui est du flux RSS, c'est la première fois qu'on me signale ce problème... Je vais voir ce que je peux faire!
aurelien
comme exemple : la difference de performance and base::merge et dplyr::*_join est phenomémale, plus de 40X
http://zevross.com/blog/2014/04/30/mini-post-for-large-tables-in-r-dplyrs-function-inner_join-is-much-faster-than-merge/
lvaudor
Ah! merci Aurélien pour cet exemple, et pour le lien! Je n'ai encore jamais été obligée de faire des jointures sur des tables très volumineuses, donc je n'avais pas pu apprécier cette différence...
shu
Bonjour et Merci pour ce post très clair.
J'ai une question, je n'arrive pas a voir avec quelle fonction je peux effectuer la fusion suivante :
Base 1 :
ID Couleur
1 Orange 10
1 Orange 12
1 Vert 8
1 Bleu 6
2 Jaune 10
2 Violet 8
3 Vert 8
3 Bleu 10
Base 2 :
1 Petites Billes
2 Grosses Billes
3 Calots
Je souhaiterais avoir une seule base comme celle ci :
1 Petites Billes Orange Orange Vert Bleu 10 12 8 6
2 Grosses Billes Jaune Violet 10 8
3 Calots Vert Bleu 8 10
Merci d'avance pour votre aide.
lvaudor
Bonjour,
Dans votre "tableau" final il n'y a pas le même nombre d'infos par ligne (donc en l'état ce n'est pas un tableau, ou alors il manque des séparateurs de colonne pour que je puisse voir si vous avez réuni plusieurs infos en une même colonne)...
Du coup je ne comprends pas bien ce que vous voulez faire? Si vous faites une jointure du type
left_join(Base1,Base2,by="ID")
vous obtiendrez 8 lignes avec 4 variables ID, Couleur, Taille et Nom. Si partant de là vous voulez "changer la forme" de votre tableau j(c'est-à-dire changer ce que vous considérez comme individu vs ce que vous considérez comme variable) je vous conseille d'aller voir les fonctions du package tidyr (notamment la fonction "spread", qui pourrait peut-être s'approcher de ce que vous voulez faire).
shu
Merci pour votre réponse rapide.
En fait l'étape avec 8 lignes et 4 variables est dans un premier temps pas mal.
Je souhaiterais juste à la fin avoir un fichier avec une ligne un ID, donc dans cet exemple seulement 3 lignes.
Le nombre de Colonnes du tableau final dépend donc du nombre de répétitions de l'ID dans la base 1.
En l occurence dans cet exemple comme l'ID est répété au maximum 4 fois, les variables et taillle sont répétées 4 fois .
ID | COULEUR1 | COULEUR2 | COULEUR3 | COULEUR4 | TAILLE1 | TAILLE2 | TAILLE3 | TAILLE4| NOM
1 | Petites Billes | Orange | Orange | Vert | Bleu | 10 | 12 | 8 | 6
2 | Grosses Billes | Jaune | Violet | NA | NA | 10 | 8 | NA | NA
3 | Calots | Vert | Bleu | NA | NA | 8 | 10 | NA | NA
Merci d'avance pour votre aide.
1 Petites Billes Orange Orange Vert Bleu 10 12 8 6
2 Grosses Billes Jaune Violet 10 8
3 Calots Vert Bleu 8 10
lvaudor
Alors je confirme: allez voir ce que la fonction spread du package tidyr peut faire pour vous...
shu
Très bien je vais essayer, merci beaucoup
Thibaut Terrettaz
Bonjour, je cherche partout, mais je n'arrive pas à trouver la syntaxe correct ou la bonne solution.
J'ai deux bases de données . Tous les id sont différents entre les deux. Certaines variables sont les mêmes mais pas toutes.
Quand j'utilise full_join(a,b,by="id"), j'ai le même résultat que merge(a, b, by="id", all.x = TRUE, all.y = TRUE).
C'est à dire que j'ai toutes les données. Cependant, j'aimerais que les colonnes communes dans les deux bases n'apparaissent qu'une fois.
Maintenant, j'ai par exemple, genre.x et genre.y. J'aimerais seulement avoir genre.
Comment puis-je faire?
Un grand merci, si quelqu'un me répond et trouve une solution.
Meilleures salutations
Thibaut Terrettaz
En fait, il me semble que c'était très simple, il fallait seulement écrire comme ça full_join(a,b).
Merci quand-même à vous!
Camille
Bonjour je cherche à faire exactement la même chose que vous mais la solution que vous avez trouvé pour votre jeu de donné ne fonctionne pas pour moi... Ca a le même effet que full_join (a,b, by = NULL) et ça ne rajoute pas les colonnes de b qui sont différentes de a
Est-ce que vous pouvez m'aider ?
Leandre
Bonjour,
Quelqu'un sait par hasard comment sortir les lignes non-duppliquées avec la fonction merge de R?
lvaudor
Je crois que la fonction inner_join() de dplyr ferait ce que vous souhaitez!...
MN
bonjour,
j'utilise dplyr notamment pour joindre des tables c'est très efficaces, par contre je n'arrive pas à utiliser filter et select correctement. la plupart du temps j'ai ce message ,quelle que soit la table (dataframe) utilisée.....
que je mette le nom de la table dans un pipe ou dans la parenthèse ça ne marche pas, qu'est ce que j'oublie ?
filter(Tablabo,type_granulo=="apresdec")
Error in filter.default(Tablabo, type_granulo == "apresdec") :
l'argument "x" est manquant, avec aucune valeur par défaut
select(Tablabo,Pt,Parcelle,type_granulo,CsurN) %>%
+ filter(type_granulo=="apresdec")
Error in filter.default(., type_granulo == "apresdec") :
l'argument "x" est manquant, avec aucune valeur par défaut
select fonctionne ici
select(Tablabo,Pt,Parcelle,type_granulo,CsurN)
Pt Parcelle type_granulo CsurN
200457438 P1 LP sansdec 8.43
200457439 P2 TE sansdec 9.09
200457661 P3 TO apresdec 9.13
200457440 P4 TE sansdec 8.62
200457414 P5 ZM sansdec 8.62
mais pas là....
Tablabo %>% select(Tablabo,Pt,Parcelle,type_granulo,CsurN)
Erreur : `Tablabo` must evaluate to column positions or names, not a list
Call `rlang::last_error()` to see a backtrace
merci d'avance si vous avez une idée
lvaudor
A priori c'est assez incompréhensible pour filter()... sauf s'il s'agit d'une fonction filter() provenant d'un autre package (raster par exemple). Pour être sûr que la fonction filter utilisée soit la bonne vous pouvez écrire dplyr::filter() au lieu de filter()...
Pierre
Bonjour,
je souhaitais savoir s'il y avait une commande simple pour faire une jointure entre deux tables avec le même ID et qu'en sortie on est toutes les infos de la première table mais seulement une ou une partie d'info de la seconde., histoire de ne pas ramener 200 variables pour rien.
Merci si vous avez des idées.
lvaudor
Bonjour, si je comprends bien votre question alors il faudrait simplement sélectionner les variables de la deuxième table que vous voulez conserver AVANT de réaliser la jointure.
xxx_join(tib_1, tib_2 %>% select(variables))
laplanca
Bonjour j'ai deux fichiers auxquels je souhaite appliquer un rbind. Ils ont le même nombre de colonnes, les mêmes noms de colonnes et cela ne fonctionne pas je ne comprend pas pourquoi. Les variables n'ont pas tjrs le même format est ce que cela peut venir de ça? Actuellement j'ai ce message d'erreur qui n'a aucun sens pour moi : Error in charToDate(x) : la chaîne de caractères n'est pas dans un format standard non ambigu
lvaudor
Bonjour,
Effectivement ça ressemble à un problème dans le typage des colonnes. Vraisemblablement un des fichiers au moins contient une date dans un format qui n'est pas standard...
Manu
Bonjour,
existe t-il une fonction (ou méthode) permettant de modifier/corriger uniquement certaines lignes d'une colonne, à partir des lignes d'une autre table, en indiquant la jointure entre les deux tables (équivalent de "UPDATE (...) SET (...) WHERE" dans SQL), mais sans ajouter de colonnes, simplement en corrigeant certaines valeurs de la colonne d'origine... (je ne sais pas si c'est bien clair, je cherche depuis un moment...)
lvaudor
Bonjour!
Je pense qu'il faudrait chercher du côté de l'usage de case_when() dans dplyr (bien qu'il ne s'agisse pas à proprement parler d'une "jointure conditionnelle", la fonction permet de modifier une colonne *pour certaines lignes* définies par une condition sur la colonne elle-même ou une autre colonne)...