
Oui, bon, j’avoue, j’ai choisi le titre de ce billet exprès pour que, à sa lecture, vous ayiez ce genre d’image qui vous vienne à l’esprit:
Mais en vrai, je m’apprête à vous parler de quelque chose d’un peu moins « caliente », car

En revanche:

Vous l’aurez compris, je parle ici de « manipuler des strings » pour « manipuler des chaînes de caractères », en français (je vais tout-de-même rester sur « string » pour la suite de l’article parce que, en plus d’être plus drôle, c’est plus court!).
Pourquoi vouloir manipuler des strings
Deux raisons principales possibles:
- parce que vous travaillez sur des textes (romans, articles de presse, articles scientifiques, sites web, tweets, et j’en passe), et que vous voulez faire du text mining sur ces données
- parce que vous avez besoin de nettoyer/récupérer des infos « emprisonnées » dans des chaînes de caractère… Par exemple, vous avez un capteur qui vous crée des fichiers dont le nom est « monsuperfichier_02032017_X330441.22_Y402933.54.txt » et vous voulez récupérer la date (02/03/2017) et les coordonnées (X et Y) correspondant à chacun de ces fichiers. Ou vous avez une colonne de tableau contenant des informations du style « Bruce Wayne, Batman, justicier masqué » et vous voulez faire en sorte que ces informations soient séparés en « Bruce Wayne », « Batman », et « justicier masqué »…
Dans les deux cas, savoir réaliser des opérations basiques (détection de patterns, remplacement de patterns, découpe des strings) va se réveler indispensable… Et pour ce faire, l’usage du package stringr, notamment, est d’une aide précieuse… Les fonctions de ce package sont facilement reconnaissables puisque tous leurs noms commencent par « str_ »…
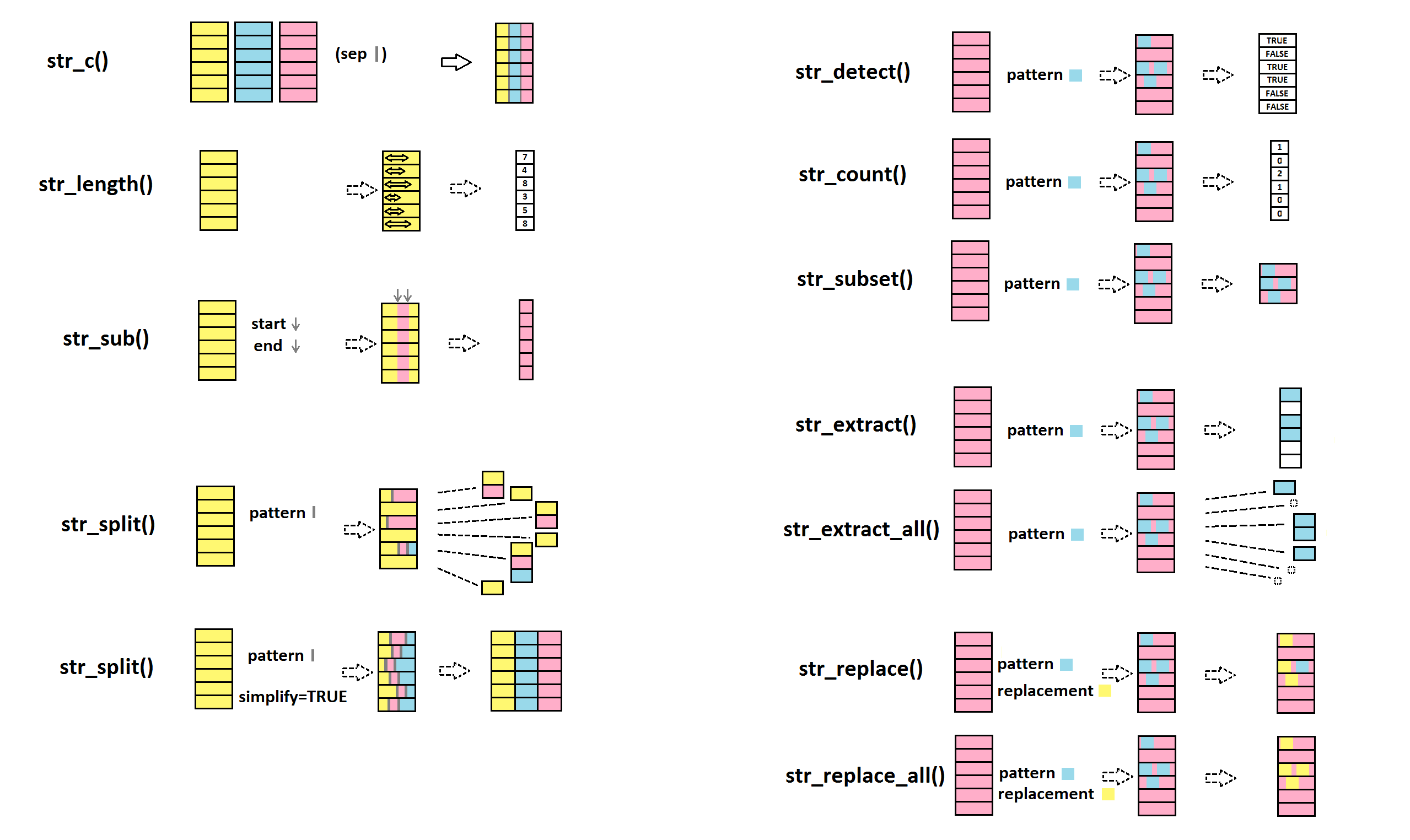
Voici un petite « aide-mémoire » montrant l’utilité de celles que je vais aborder dans ce billet. Je vais bien sûr vous montrer des exemples en lignes de commande plutôt qu’en dessins bigarrés, mais je trouve les dessins utiles pour s’y retrouver (je dois avoir une mémoire visuelle!):
Dans le détail, maintenant:
str_c() combine des strings
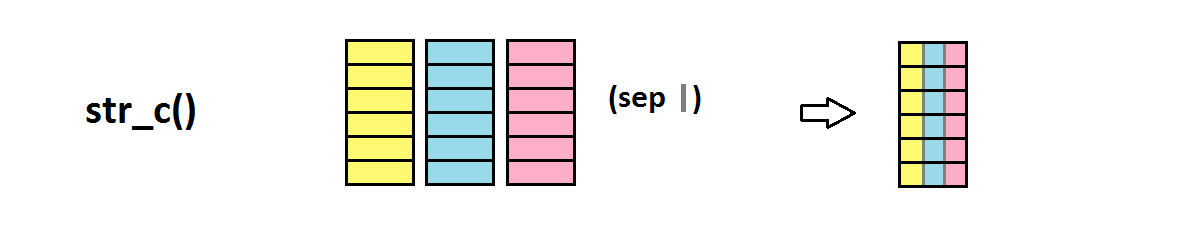
library(stringr)
str_c("abra","ca","dabra")
## [1] "abracadabra"
str_c("Les jeux","de mots laids","sont pour","les gens bêtes", sep=" ")
## [1] "Les jeux de mots laids sont pour les gens bêtes"
str_length() compte le nombre de caractères dans un string

str_length("anticonstitutionnellement")
## [1] 25
str_sub() extrait les caractères de la chaîne, de l’emplacement start à l’emplacement end

str_sub("youpiyaya",start=1,end=5)
## [1] "youpi"
str_sub("youpiyaya",start=-4)
## [1] "yaya"
str_sub("youpiyaya",start=4)
## [1] "piyaya"
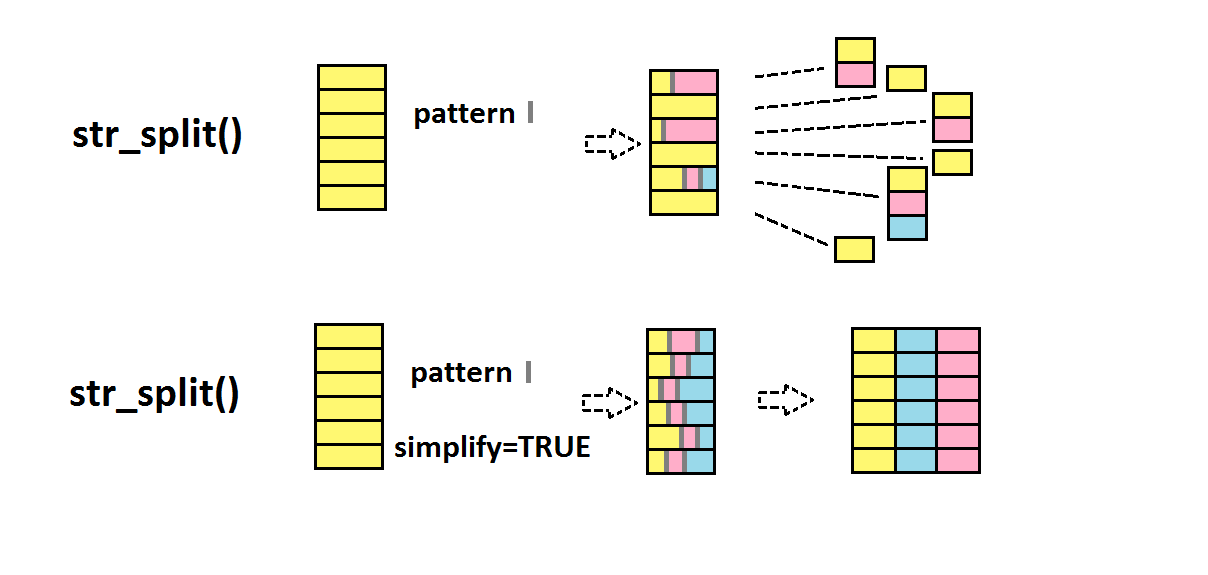
str_split() découpe les strings partout où un pattern (ou motif) est présent
str_split(c("beau_gros_chat",
"joli_chien",
"vilain_petit_canard"),
"_")
## [[1]]
## [1] "beau" "gros" "chat"
##
## [[2]]
## [1] "joli" "chien"
##
## [[3]]
## [1] "vilain" "petit" "canard"
Le pattern (ici « _ ») peut être présent un nombre variable de fois, donc les éléments en sortie ne sont pas forcément de la même taille. C’est pourquoi cette fonction renvoie une liste.
En revanche, si l’on sait que tous les éléments de l’input seront découpés en autant de morceaux, alors on peut demander une sortie sous forme de matrice, plus pratique à manipuler par la suite, à l’aide de l’argument simplify=TRUE.
str_split(c("beau_gros_chat",
"joli_petit_chien",
"vilain_petit_canard"),
"_",
simplify=TRUE)
## [,1] [,2] [,3]
## [1,] "beau" "gros" "chat"
## [2,] "joli" "petit" "chien"
## [3,] "vilain" "petit" "canard"
str_detect() détecte un pattern

str_detect(c("Quarante","carottes","crues",
"croient","que","croquer",
"crée","des","crampes."),
pattern="cr")
## [1] FALSE FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUE
str_count() compte les occurrences d’un pattern

str_count(c("L'âne","Trotro","trotte","à une allure","traitreusement","tranquille"),
pattern="tr")
## [1] 0 1 1 0 2 1
str_subset() crée un subset du vecteur où le pattern est présent

str_subset(c("Quarante","carottes","crues",
"croient","que","croquer",
"crée","des","crampes."),
pattern="cr")
## [1] "crues" "croient" "croquer" "crée" "crampes."
str_extract() extrait le pattern (là où il est présent)
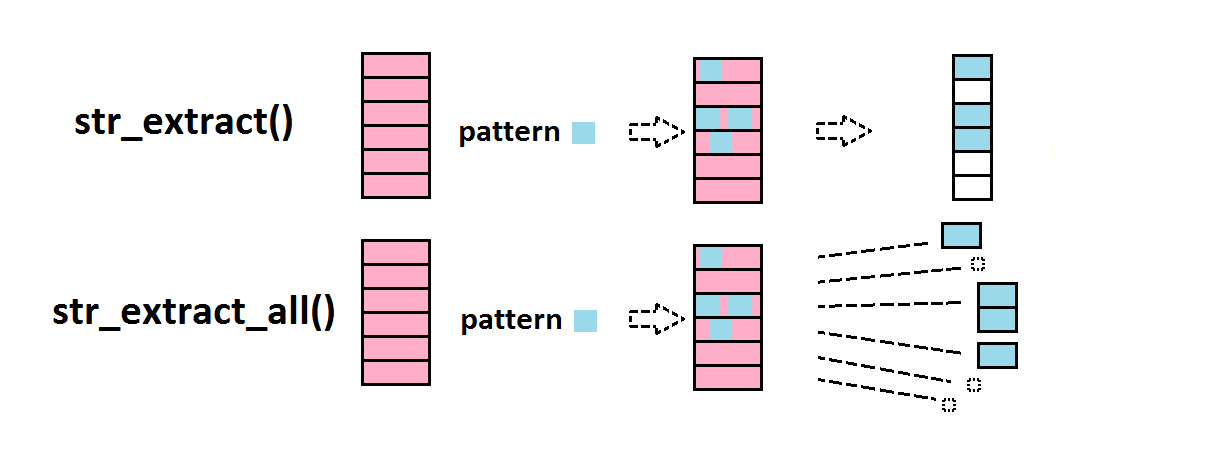
str_extract(c("L'âne","Trotro","trotte","à une allure","traitreusement","tranquille"),
pattern="tr")
## [1] NA "tr" "tr" NA "tr" "tr"
Notez la différence entre str_extract() et str_extract_all():
str_extract_all(c("L'âne","Trotro","trotte","à une allure","traitreusement","tranquille"),
pattern="tr")
## [[1]]
## character(0)
##
## [[2]]
## [1] "tr"
##
## [[3]]
## [1] "tr"
##
## [[4]]
## character(0)
##
## [[5]]
## [1] "tr" "tr"
##
## [[6]]
## [1] "tr"
Si un pattern est présent plusieurs fois dans un des éléments du vecteur en input, alors il correspondra à plusieurs éléments dans l’output (ainsi l’output correspond non pas à un vecteur de même taille que l’input, mais à une liste).
str_replace() remplace le pattern par un autre motif
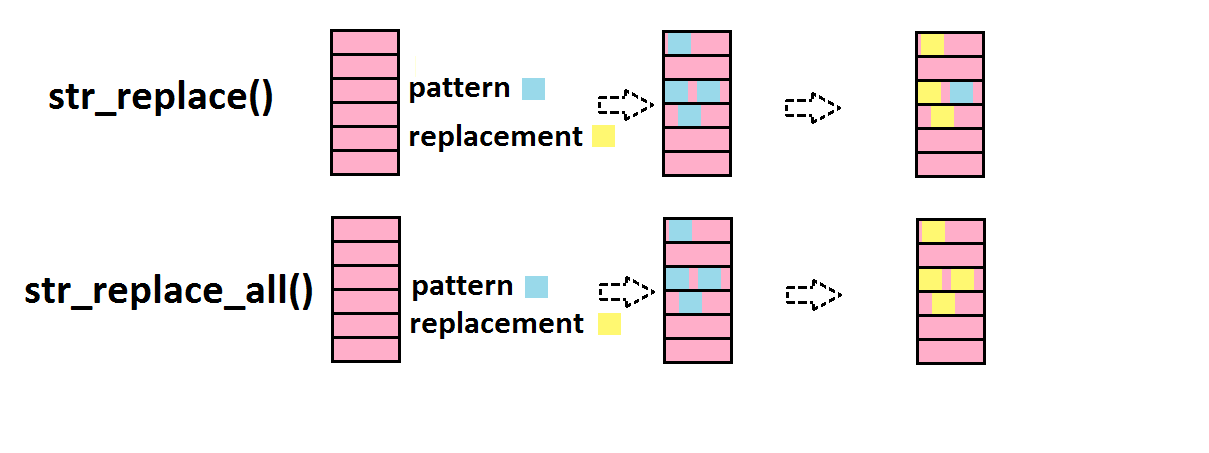
str_replace("All we hear is Radio ga ga Radio goo goo Radio ga ga",
pattern="goo",
replacement="ga")
## [1] "All we hear is Radio ga ga Radio ga goo Radio ga ga"
str_replace_all("All we hear is Radio ga ga Radio goo goo Radio ga ga",
pattern="goo",
replacement="ga")
## [1] "All we hear is Radio ga ga Radio ga ga Radio ga ga"
Là encore, notez la différence entre str_replace() et str_replace_all()!!
3 Comments
Guillaume
Encore un article super clair, détaillé, imagé et complet, le tout avec une jolie finesse d’esprit, merci beaucoup !
lvaudor
Merci 🙂
Siamsoft
Tres bien . Bravo!