
Pour analyser une variable binaire (dont les valeurs seraient VRAI/FAUX, 0/1, ou encore OUI/NON) en fonction d'une variable explicative quantitative, on peut utiliser une régression logistique.
Considérons par exemple les données suivantes, où x est l'âge de 40 personnes, et y la variable indiquant s'ils ont acheté un album de death metal au cours des 5 dernières années (1 si "oui", 0 si "non")
Graphiquement, on constate que vraisemblablement, plus les personnes sont âgées, moins elle achètent de death metal.
plot(x,y)
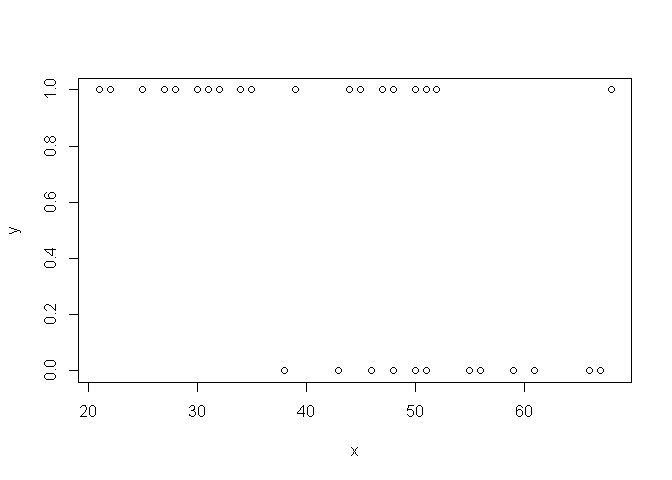
Vérifions cela à l'aide d'un modèle...
La régression logistique est un cas particulier de Modèle Linéaire Généralisé (GLM).
Avec un modèle de régression linéaire classique, on considère le modèle suivant:
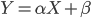
On prédit donc l'espérance de Y de la manière suivante :
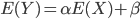
Ici, du fait de la distribution binaire de Y, les relations ci-dessus ne peuvent pas s'appliquer. Pour "généraliser" le modèle linéaire, on considère donc que
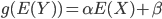
où g est une fonction de lien.
En l'occurence, pour une régression logistique, la fonction de lien correspond à la fonction logit:
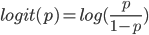
Notez que cette fonction logit transforme une valeur (p) comprise entre 0 et 1 (comme une probabilité par exemple) en une valeur comprise entre − ∞ et + ∞.
Voici comment réaliser la régression logistique sous R:
myreg=glm(y~x, family=binomial(link=logit))
summary(myreg)
##
## Call:
## glm(formula = y ~ x, family = binomial(link = logit))
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.8686 -0.7764 0.3801 0.8814 2.0253
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 5.9462 1.9599 3.034 0.00241 **
## x -0.1156 0.0397 -2.912 0.00360 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 52.925 on 39 degrees of freedom
## Residual deviance: 39.617 on 38 degrees of freedom
## AIC: 43.617
##
## Number of Fisher Scoring iterations: 5
On obtient donc le modèle suivant:
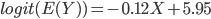
et l'on constate que l'influence (négative) de l'âge sur l'achat d'albums de death metal est bien significative au seuil de 5%.
Si l'on représente cette relation entre logit(E(Y) et X, on retrouve bien une relation linéaire. En revanche, l'échelle des ordonnées n'est pas aisée à interpréter... On procède donc à une transformation inverse de la relation:
logit_ypredit=-0.12*x+5.95
ypredit=exp(logit_ypredit)/(1+ exp(logit_ypredit)) # transfo inverse de logit
plot(x,y)
points(x,ypredit, col="red")
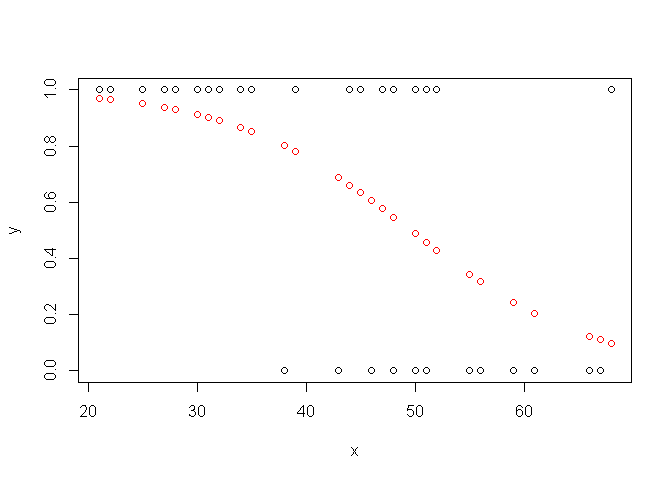
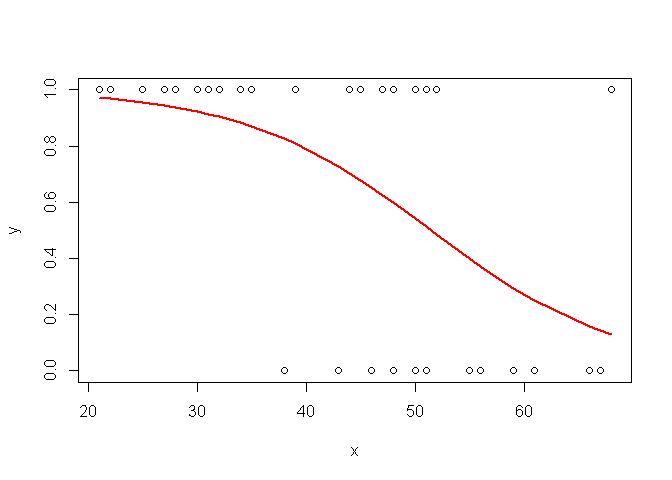
Pour tracer la courbe:
plot(x,y)
o=order(x)
points(x[o],ypredit[o], col="red", type="l", lwd=2)
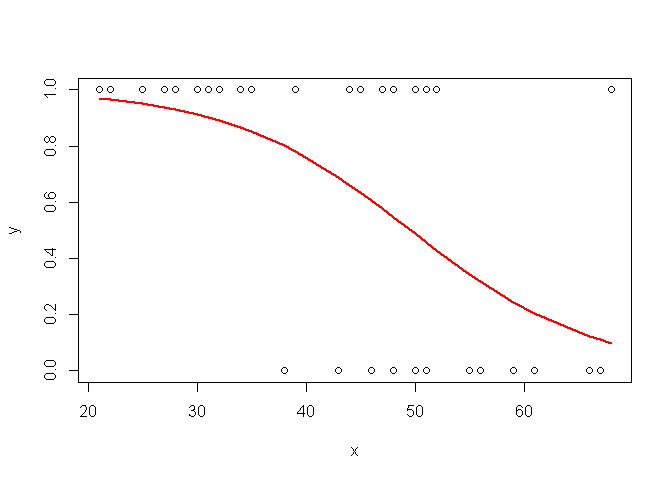
Enfin, pour se simplifier la vie, il est aussi possible de récupérer les valeurs prédites de y directement :
plot(x,y)
myreg=glm(y~x, family=binomial(link=logit))
ypredit=myreg$fitted
o=order(x)
points(x[o],ypredit[o], col="red", type="l", lwd=2)
18 Comments
Alice
Merci, votre presentation est très pédagogique
AGANDAN Nadège
Merci pour ce document.
Nihorimbere Michel Chritophe
Merci de ce document aussi riche qu'instuictif.
KOBLA Anne Stéphanie
Merci. c'est raiment très facile à comprendre et à appliquer
Guillaume
Bonjour, merci pour tes présentations. Mais j'ai une question: j'ai des proportions de maladie (exprimées en %) qui vont de 0 à 100%. Je pensais faire une anova, mais ce n'est vraiment pas adapté. Du coup, en faisant un peu de recherche, et un GLM ferait l'affaire, en particulier un GLM binomial ou quasibinomial. Sauf que dans mon cas, je n'ai pas une possibilité d'échec ou de succès comme pour un binomial classique. Visiblement, il faut que je ruse car je travaille directement sur des proportions (et non sur des effectifs à partir desquels on calcule une proportion). Mais là je suis paumé...
On m'a également conseillé de transformer mes données via la fonction logit pour transformer une variable bornée en variable non bornée mais cela ne m'aide pas plus.
Et autre chose, en poussant encore mes recherches une régression beta semblerait plus adaptée pour pourcentages incluant des valeurs minimale et maximale (0 et des 1). J’ai trouvé les packages zoib et gamlss qui seraient plus adaptés.Mais je ne suis vraiment pas sûr. Je ne cherche juste qu'a savoir les effets de mes facteurs sur ma variable maladie exprimée en %. C'est quand même bien galère!
As-tu déjà été confrontée à ce genre d'analyse ?
lvaudor
Bonjour Guillaume,
Alors je n'ai encore jamais fait de régression pour expliquer une variable variant entre 0 et 1, mais effectivement une des options possibles serait de faire une régression linéaire classique sur des données logit-transformées (tu peux suivre le billet pour tout ce qui est transformation et back-transformation de tes valeurs prédites, de manière à afficher tes valeurs de variables dans leur espace d'origine...). Sinon effectivement une régression beta serait parfaite. Malheureusement je ne connais pas les packages que tu mentionnes donc je ne peux pas te conseiller...
Guillaume
Bonjour et merci de ta réponse! Je vais tenter le truc... Je ne comprends juste pas pourquoi je ne peux pas faire un GLM classique binomial ou quasi binomial!
Quentin R
Très bonne présentation
Merci beaucoup !
Gloria
J'aimerais savoir s'il est possible de faire les régressions logistique avec plusieurs variables explicatives dans Rstudio comme on le fait dans stata
lvaudor
Oui! Pour cela il faut remplacer la formule Y~X par la formule Y~X1+X2 (où Y est votre variable réponse et X1 et X2 sont vos variables explicatives). Par contre en terme de représentation ce sera plus compliqué car il faudra trouver comment représenter "trois dimensions" à la fois (X1, X2 et Y).
mat
Comment changer de modalités de référence dans une régréssion logistique sur R?
lvaudor
Bonjour,
Alors cela fait un moment que je n'ai plus utilisé la fonction glm mais il me semble qu'il faut changer l'"ordre" des modalités dans le facteur lui-même (avec la fonction relevel() par exemple) car je ne crois pas que la fonction glm permette de modifier la modalité de référence (il prendra par défaut la première ou la dernière -je ne sais plus- modalité du facteur).
mat
Pourriez-vous m'expliquer quelle est la formule permettant de faire les Odd Ratio sur R? Merci
lvaudor
Bonjour,
Je vous invite à aller voir cet article https://statistique-et-logiciel-r.com/calculer-et-rapporter-les-odds-ratio-sans-se-fatiguer/, très complet, sur le sujet!!
Quentin F
Merci pour cette présentation ! <3
Eloi A
+1
GuiSi
Du coup , E[Y] = alpha* E[X] + beta plutot non? par linéarité de l'esperance. Ou alors il y'a quelque chose que je n'ai pas compris (et donc potentiellement mal expliqué)
lvaudor
Bonjour,
Vous avez raison, j'ai corrigé! Merci