
Le pavé dans la mare
Il y a peu de temps je suis tombée sur cet article qui m'a laissée songeuse:
Ioannidis JPA (2005) Why Most Published Research Findings Are False. PLoS Med 2(8):e124. (https://doi.org/10.1371/journal.pmed.0020124 )
Comme son titre l'indique, cet article s'appuie sur des calculs de probabilités pour montrer que lorsqu'un chercheur publie un résultat significatif, il y a en fait de fortes chances pour que ce résultat soit faux.
Passé le premier stade de stupéfaction ("Comment est-ce possible?"), le deuxième stade de découragement ("Las! A quoi bon continuer à chercher?"), le troisième stade de résilience ("Bon ben, puisque c'est comme ça je n'ai qu'à rentrer chez moi!"), j'ai eu envie de comprendre d'où l'auteur tirait cette conclusion (qui, si on l'en croit, aurait de fortes chances d'être fausse, donc!).
J'ai donc tenté de m'approprier son raisonnement à travers une petite mise en situation/bande dessinée (une fois n'est pas coutume, ce billet ne traite pas du tout de R, mais uniquement de statistiques!).
Essayons de comprendre
Imaginons donc un chercheur souhaitant savoir quelle est la couleur d'une micro-bêbête unicellulaire si minuscule qu'il ne peut l'observer directement (même si nous, grâce à nos dons d'omniscience, voyons bien que cette micro-bêbête est rose)

Le chercheur formule une hypothèse quant à la couleur de la micro-bêbête (ici, l'hypothèse serait qu'elle est bleue) et dispose d'une méthode pour tester son hypothèse. Par exemple, il est capable de mesurer une quantité relative de pigment bleu et vérifie si cette quantité augmente quand la quantité de micro-bêbête augmente.

Ici, son test n'est pas concluant et il n'est pas en mesure d'affirmer que la micro-bêbête est bleue.
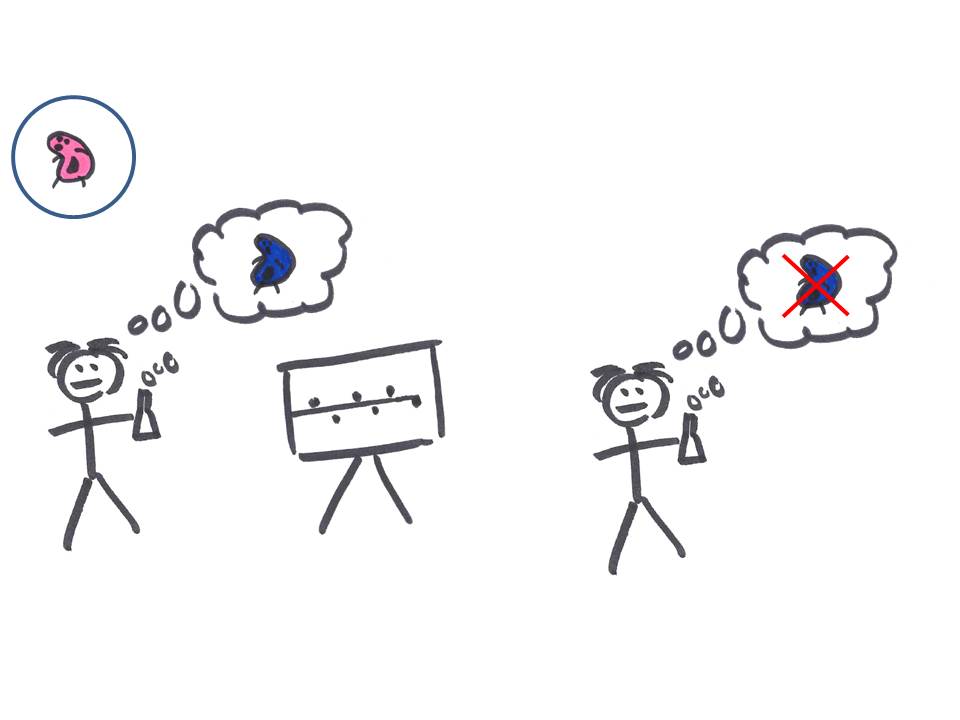
Le chercheur va sans doute tester un certain nombre d'hypothèses de cette manière:
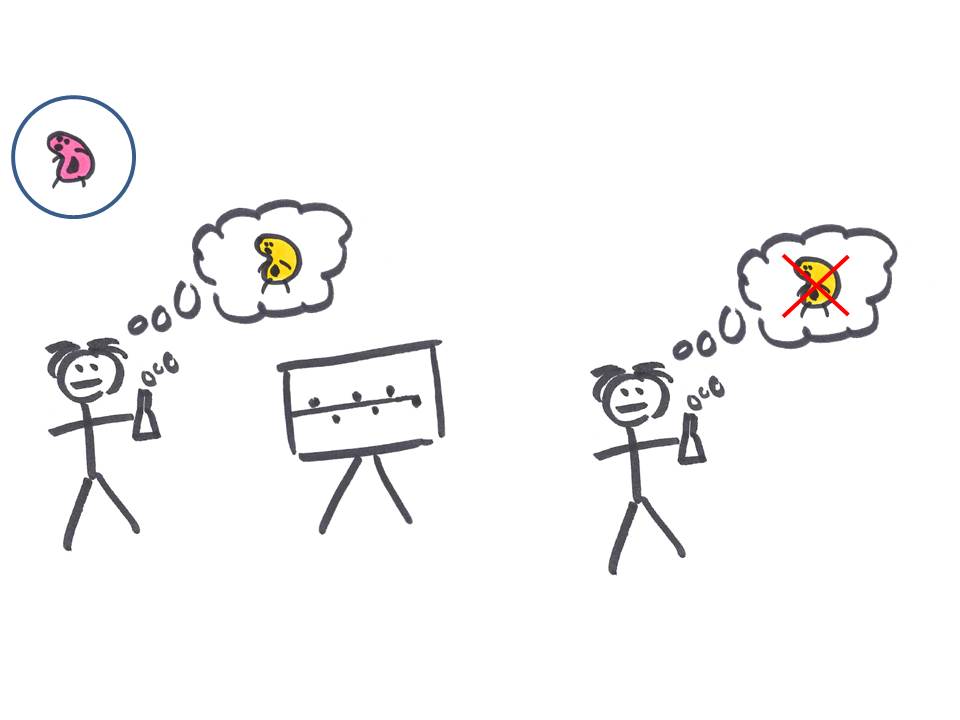
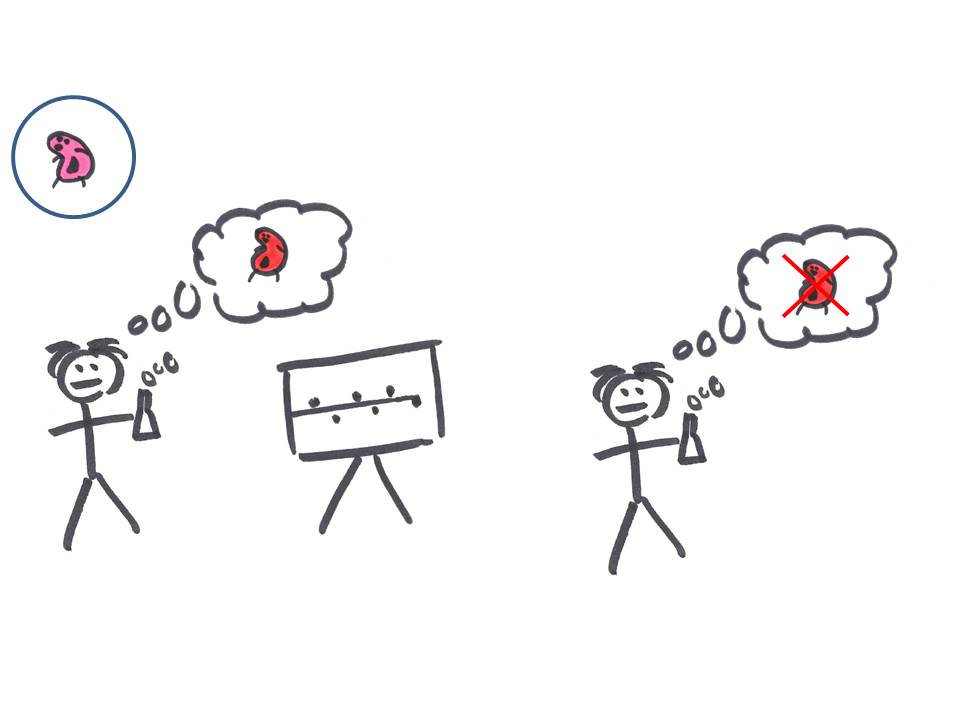
Et avec un peu de chance, il va également tester une hypothèse vraie:
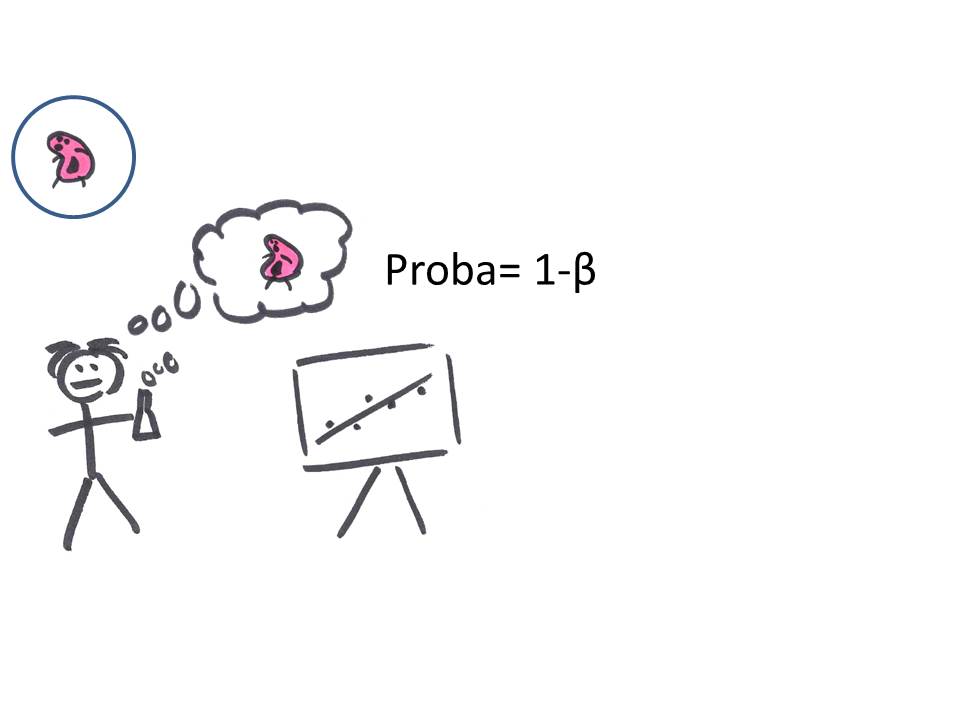
Dans ce cas, il aura une probabilité de 1 − β d'obtenir un résultat significatif, ce qu'il va s'empresser (et c'est bien naturel) de communiquer au monde:

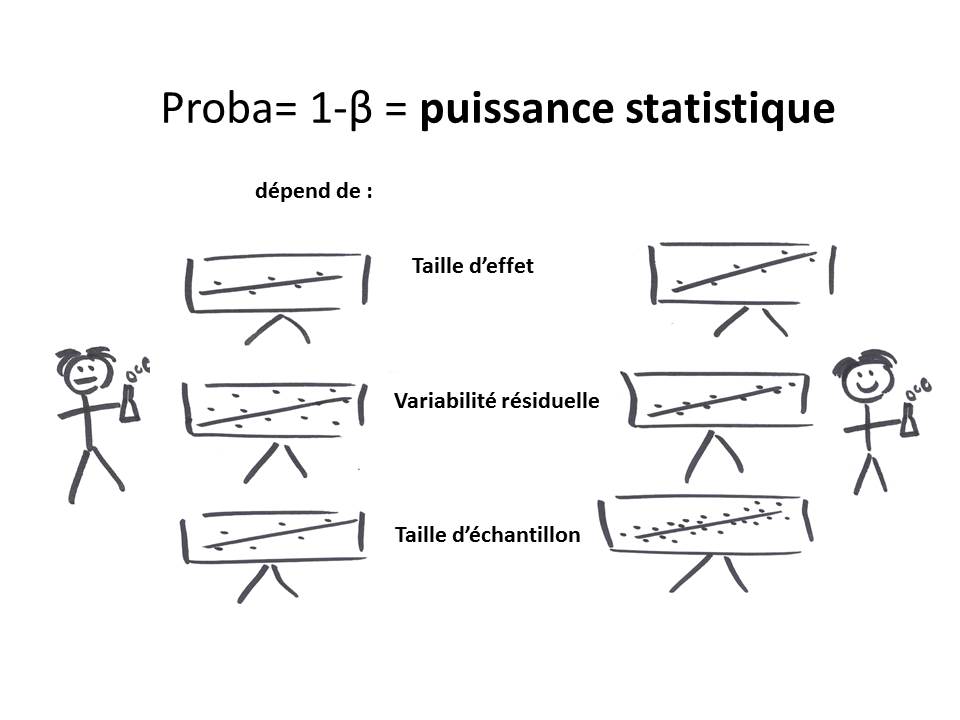
Revenons juste un instant à cette valeur de 1 − β, qui correspond à la probabilité que le test indique un effet significatif si l'effet existe réellement. Cette valeur correspond à la puissance d'un test.
La puissance d'un test résulte, grosso modo, d'une combinaison de plusieurs facteurs, et notamment de:
- la taille d'effet (est-ce que la quantité de micro-bêbête influence beaucoup la quantité de pigment ou non)
- la variabilité résiduelle (est-ce que les données varient beaucoup autour de la loi liant quantité de micro-bêbête et quantité de pigment)
- la taille d'échantillon (i.e. sur combien de mesures on s'appuie pour notre test)
Bien qu'elle soit très compliquée à estimer, on peut néanmoins dire que plus la taille d'effet est grande, plus la variabilité résiduelle est faible, plus la taille d'échantillon est grande, et plus l'on va avoir une puissance statistique élevée...
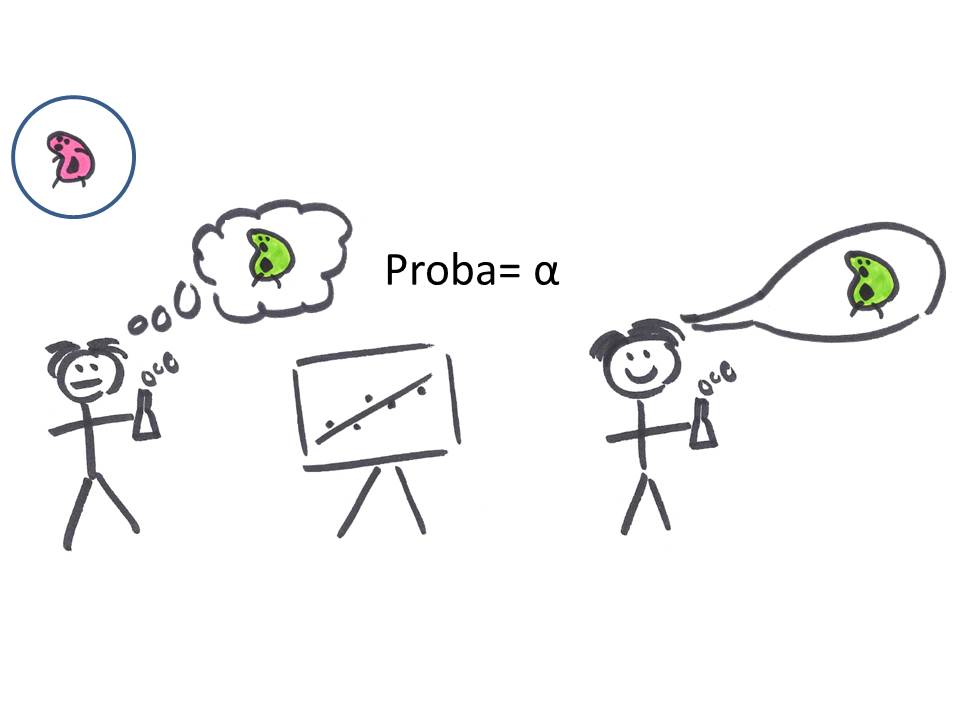
Malheureusement, il est aussi possible que le chercheur teste une hypothèse fausse et obtienne un résultat malgré tout significatif.
Ce risque d'erreur correspond au fameux α (souvent, α = 0.05) des tests statistiques. En effet, quand on fait un test d'hypothèse au seuil α = 0.05 on accepte un niveau de risque de 5% de trouver un effet alors qu'il n'y en a pas.
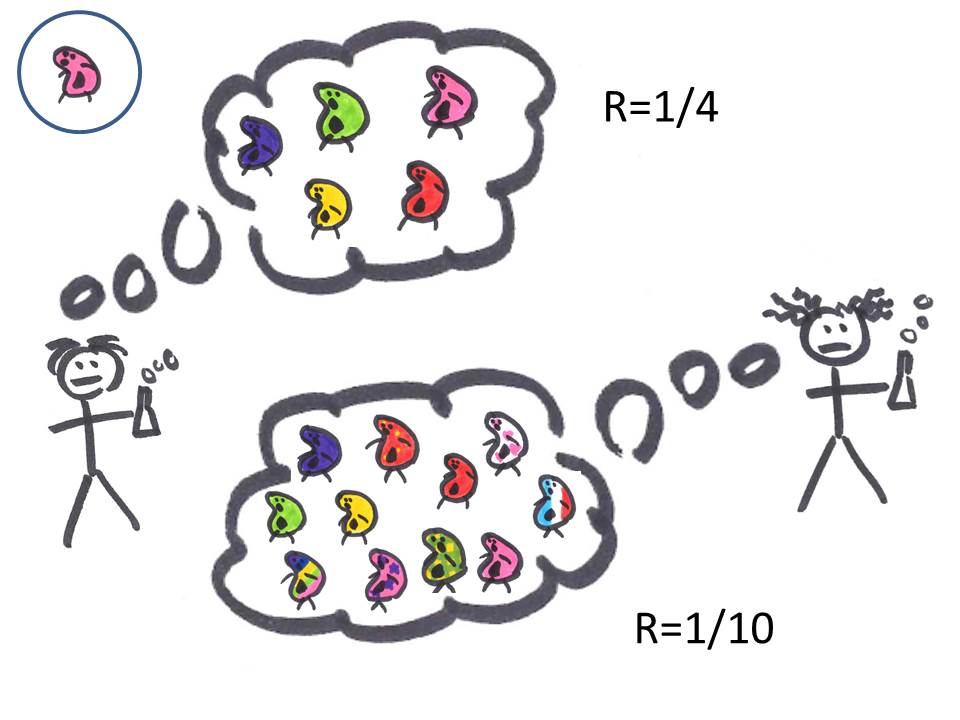
Considérons maintenant deux scientifiques, un bien raisonnable (et bien peigné), qui ne teste qu'un petit nombre d'hypothèses, et un scientifique un peu plus foufou, qui envisage un nombre d'hypothèses plus important (dont certaines sembleront même farfelues même aux non-spécialistes des micro-bêbêtes).
Dans le premier cas, le ratio R (nombre d'hypothèses vraies/nombre d'hypothèses fausses) est de 1/4, tandis qu'il est de 1/10 dans le deuxième.
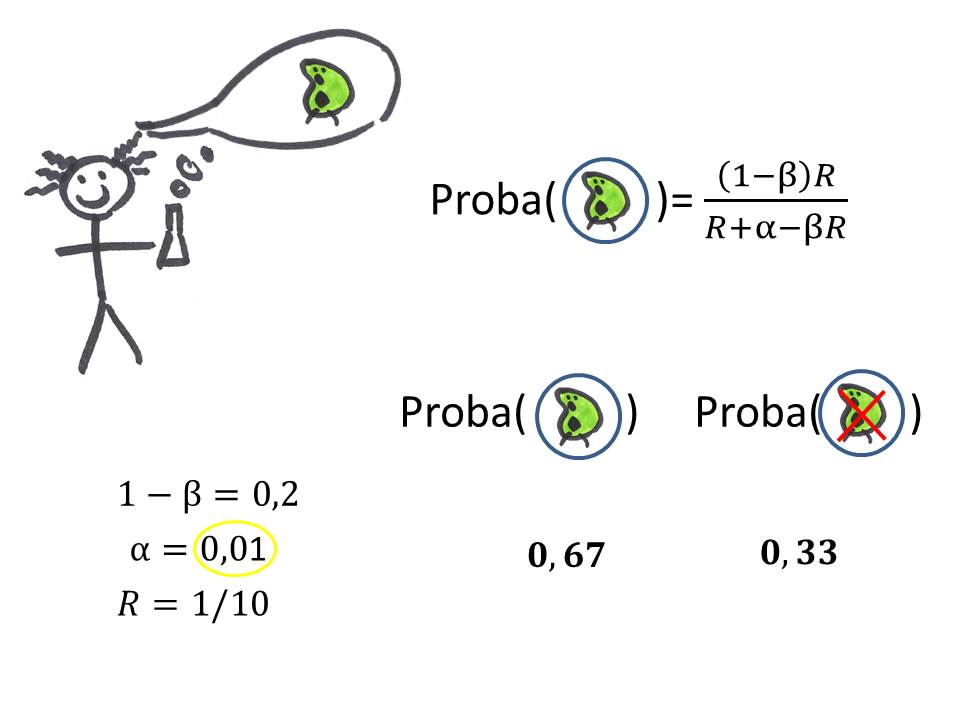
Eh bien, il est en fait possible de calculer la probabilité qu'un résultat de recherche significatif soit effectivement vrai à partir de α, β, et R, en passant par le calcul de probabilités décrit dans le tableau ci-dessous (tiré de l'article Ioannidis, 2005):
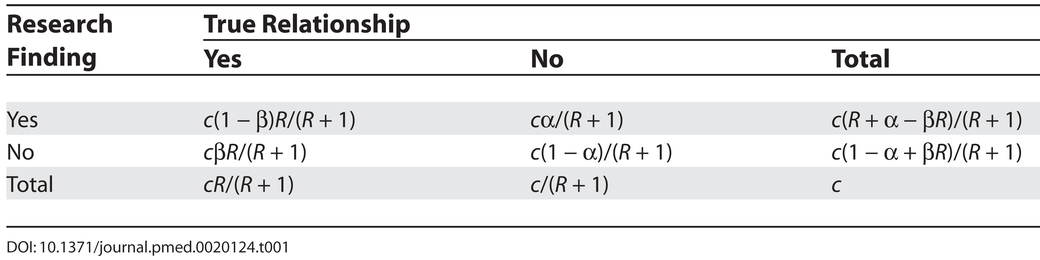
Ainsi, si
- la puissance du test est de 0.5 (i.e. au vu de la variabilité des données, de la taille d'effet et de la taille d'échantillon on estime que si l'hypothèse est correcte on aura environ une chance sur deux d'avoir un résultat significatif),
- le risque d'erreur de type I, α, est fixé à 5%,
- le ratio R est de 1/4, i.e. on a testé un nombre raisonnable d'hypothèses
alors on a 71% de chances qu'un résultat significatif corresponde effectivement à la couleur réelle, soit (tout de même) 29% de chances que le résultat fièrement communiqué au monde soit faux.
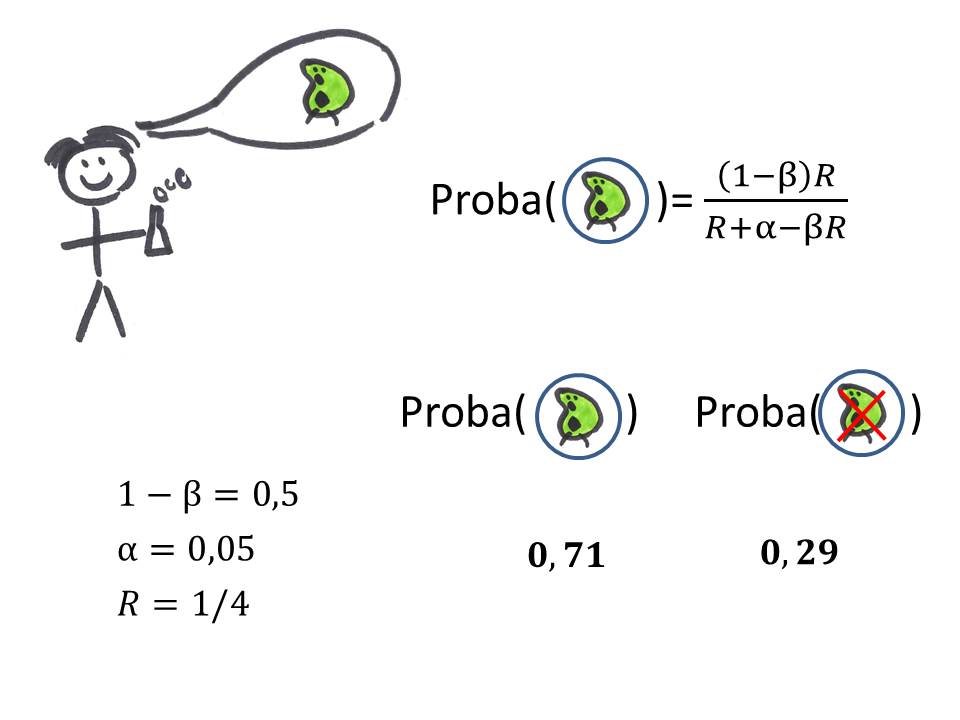
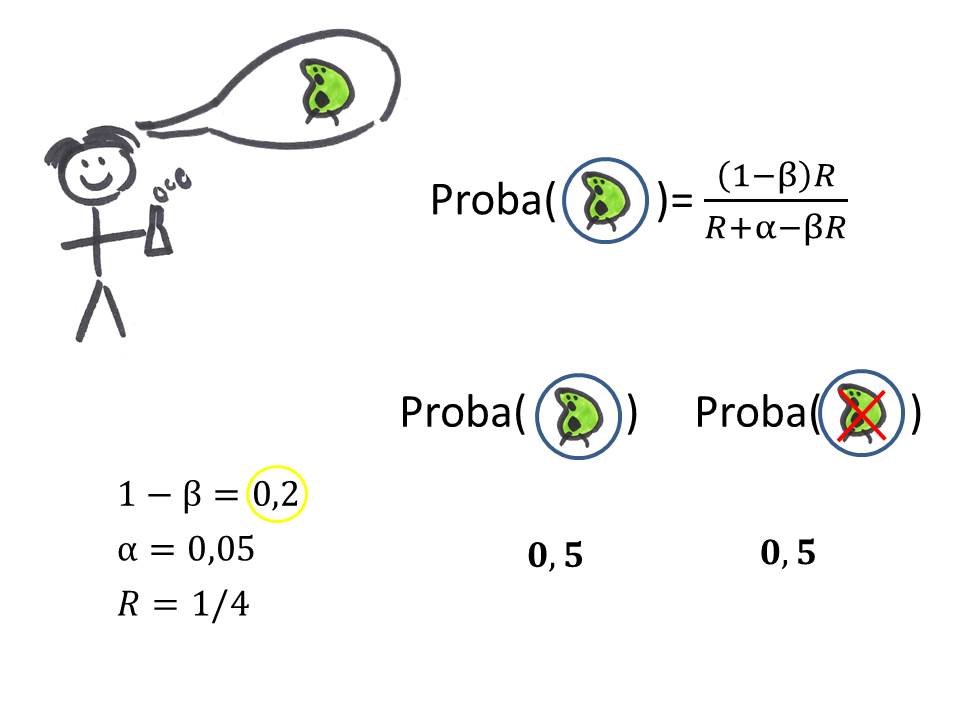
Par ailleurs, si la puissance du test était plus faible -ici, 0.2- (par exemple parce que votre taille d'échantillon est faible et vos mesures très variables), alors cette probabilité descendrait à 50% (on aurait autant de chances que le résultat annoncé soit faux qu'il soit vrai. Ouch).
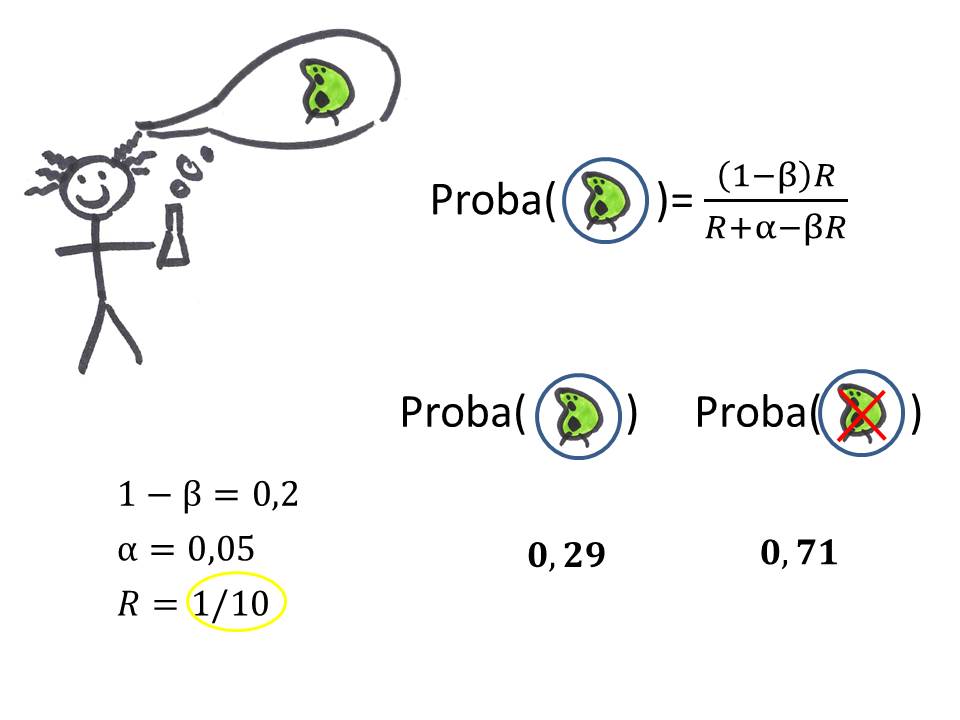
Si en plus on a testé tout un tas d'hypothèses pour sortir un résultat significatif (comme notre scientifique mal peigné et son R=1/10), alors on n'a que 29% de chances que le résultat annoncé comme significatif soit vrai!
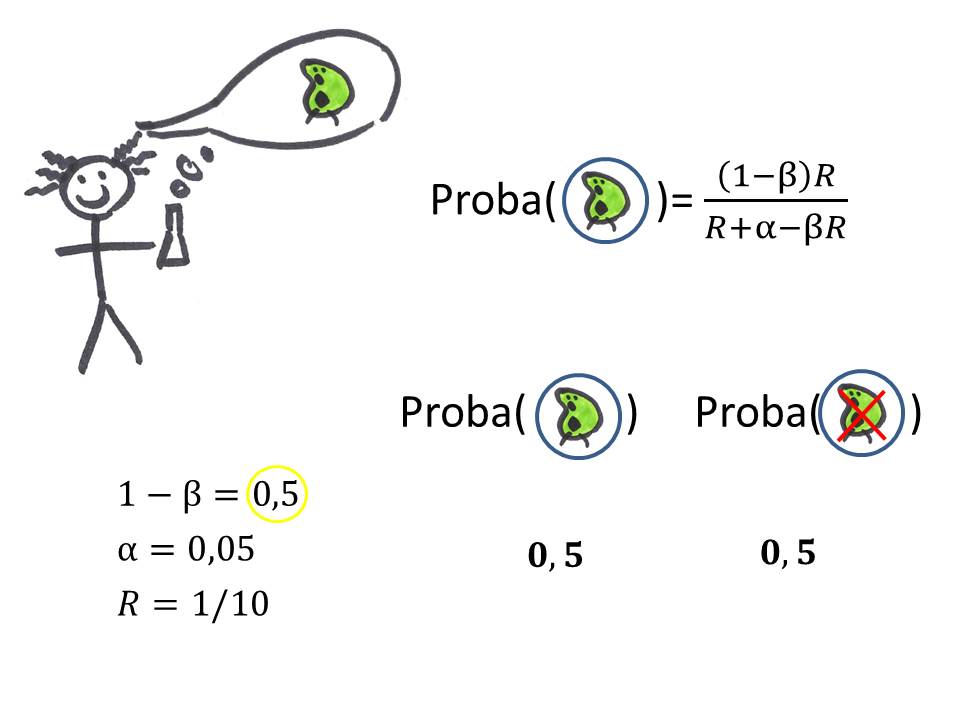
Si notre scientifique mal peigné compense ses hypothèses excentriques par un travail acharné et réussit ainsi à obtenir une puissance statistique de 0.5, il réussit à augmenter ses chances que le résultat qu'il annonce est vrai à 50% (pas non plus de quoi pavaner, mais c'est déjà mieux!).
Il peut aussi décider d'être plus strict sur son risque d'erreur α en le diminuant à (par exemple), 1%, et ainsi augmenter ses chances que tout résultat significatif soit effectivement vrai avec une probablité de 67%.
La morale de l'histoire
On peut voir plusieurs leçons à cette "démonstration"... La première, comme le titre de ce billet l'indique, et que c'est une très mauvaise idée de de torturer ses données jusqu'à ce qu'elles parlent (tester des corrélations entre tout un tas de variables, transformées de tout un tas de manières, jusqu'à obtenir un résultat significatif que l'on pourra publier!), car alors on a de fortes chances de publier un résultat qui est en fait faux.
On peut en fait comprendre ce problème comme résultant de plusieurs caractéristiques (aux effets quelque peu pervers) de la recherche scientifique telle qu'on la pratique de nos jours.
Une des ces caractéristiques est l'importance extrême accordée à la p-value en recherche quantitative. Dans certains domaines, une p-value<5% semble être un Graal, garant à la fois la "scientificité" d'une étude et de son apport à un domaine. Or d'une part il existe d'autres manières de faire de la science et d'analyser ses données que l'inférence statistique fréquentiste classique et ses tests d'hypothèse (oui oui, c'est une statisticienne qui dit ça). D'autre part, la "philosophie" des tests d'hypothèse est parfois mal comprise, et est appliquée comme une recette de cuisine là où un peu de recul et de nuance serait nécessaire (la notion de puissance statistique, notamment, mériterait un peu plus d'attention qu'on ne lui en accorde généralement, comme on l'a vu précédemment).
Une autre cause à ce problème est le "biais" correspondant au fait que l'on publie plus volontiers (ou plus facilement) un résultat significatif qu'un résultat qui ne l'est pas. Or l'incapacité à confirmer l'existence d'un effet, pourvu que la puissance statistique du test soit suffisante, devrait elle aussi être considérée comme un résultat (et non pas simplement être mise sous le tapis comme impubliable ou impossible à mettre en valeur)...
8 Comments
Ginoute
C'est d'une pédagogie époustouflante, c'est le premier article que j'ai entièrement compris. Je suis sous le choc !
lvaudor
Hihi merci Ginoute!
Eh oui, c'est parce que d'habitude mes billets sont très R-centrés, alors qu'ici je me suis essayée à quelque chose de plus "épistémologique".
(je conçois que ce que j'écris ne fasse pas toujours mouche pour ceux qui ne travaillent pas avec R... Merci à toi de faire partie de mes plus fidèles lectrices, malgré cela!!).
Antoine Messiah
Excellent article, qui nous renvoie au problème (maintenant vieux d'au moins un-demi siècle, me semble-t-il) du biais de publication, de la création d'un journal spécial "résultats négatifs", et effectivement du culte du "petit p" au détriment de la mesure de la taille de l'effet -- alors qu'en terme de prise de décision, c'est cette dernière notion qui compte, autrement dit qui fait qu'un résultat statistiquement significatif devient significatif tout court.
Olivier Schaan
Enfin une réponse censée... Oui un résultat négatif a autant d'importance qu'un positif ! En outre un résultat négatif publié éviterait de réitérer des hypothèses déjà testées; gain de temps et d'argent. Sans parler de biais qui découle de la recherche que de résultats positifs.
Julien H
Excellent, tu vas finir par en tirer un bouquin de tes billets de blog !
lvaudor
🙂
Mara
C'est magnifique!
lvaudor
Hihi! Merci Mara! 🙂