
 Aurélien Garivier
Aurélien Garivier
Web-Mining - Apprentissage statistique
PROJET machine-learning
Equipe encadrante: Stéphan Clémençon et Aurélien Garivier
Description du projet.
Il s'agit d'aborder la problématique de la publicité en ligne, et
plus précisément celle du ciblage des annonces proposées aux visiteurs d'un
site internet, au moyen de techniques d'apprentissage statistique. Le projet s'appuie sur un jeu de données, réplicant fidèlement une
campagne gérée par une des sociétés leader du marché, et comprenant 20
millions d'enregistrements relatifs à des "clics" de visiteurs sur des
contenus qui leur ont été proposés sur un site web donné, sur une période
de neuf mois pendant laquelle 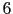 "options" (contenus possibles) étaient proposées.
"options" (contenus possibles) étaient proposées.
Chaque enregistrement comprend 120 attributs relatifs au visiteur (géographique, nombre de passages sur une page particulière du site,
heure, jour, etc...), l'identifiant de l'option (entre 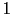 et ), et
une variable binaire indiquant s'il a cliqué ou pas. Votre objectif global est de développer un algorithme qui se voit proposer, à chaque
itération, un lot de six paires visiteur/option; il doit choisir l'une d'entre elles : l'algorithme observe alors, pour cette paire seulement,
si le visiteur a ou non cliqué. Il s'agit de maximiser le nombre total de clics observés.
et ), et
une variable binaire indiquant s'il a cliqué ou pas. Votre objectif global est de développer un algorithme qui se voit proposer, à chaque
itération, un lot de six paires visiteur/option; il doit choisir l'une d'entre elles : l'algorithme observe alors, pour cette paire seulement,
si le visiteur a ou non cliqué. Il s'agit de maximiser le nombre total de clics observés.
Détails techniques.
L'algorithme sera écrit dans le langage JAVA, sous la forme d'une classe ClickPredictor semblable à celle fournie en exemple (choisissant, à chaque instant, une paire au hasard) dans le package mis à votre disposition ici (que vous devrez commencer par décompresser).
Le fichier ClickPredictor.java (le seul que vous devrez modifier) est situé dans le répertoire algo/explo/agent.
Outre un constructeur et un opérateur de copie, la classe ClickPredictor
doit posséder :
- une méthode public int choose(Batch b) qui, étant donné
un batch de paires "visiteur/option", renvoie votre choix parmi celles-ci;
- une méthode public void learn(Arm a, Integer reward) qui
prend en argument le précédent choix d'une paire "visiteur/option"
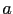 et
la récompense correspondante, et qui vous permet de mettre à jour votre
procédure de choix.
et
la récompense correspondante, et qui vous permet de mettre à jour votre
procédure de choix.
L'évaluation se fait alors sur 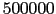 lots de 6 paires.
Pour vous permettre de vous faire une idée des données,
lots de 6 paires.
Pour vous permettre de vous faire une idée des données, 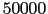 enregistrements sont distribués avec le simulateur.
Vous pouvez compiler votre algorithme en lançant, dans le répertoire racine du projet, la commande ant algo, et vous pouvez l'évaluer
sur les données dont vous disposez en lançant (toujours dans le répertoire racine du projet) la commande ant run.
enregistrements sont distribués avec le simulateur.
Vous pouvez compiler votre algorithme en lançant, dans le répertoire racine du projet, la commande ant algo, et vous pouvez l'évaluer
sur les données dont vous disposez en lançant (toujours dans le répertoire racine du projet) la commande ant run.
Votre algorithme ne
pourra utiliser qu'un seul "thread" et devra être suffisamment rapide :
une limite de temps de calcul est imposée pour chaque itération; si elle
est dépassée sans que la méthode choose n'ait renvoyé de
réponse, celle-ci sera interrompue et un choix aléatoire sera effectué.
Un fichier ClickPredictor.java pourra nous être envoyé régulièrement par
e-mail : nous nous chargerons de l'évaluer, et le nombre de clics obtenu
vous sera communiqué.
Vous pourrez commencer dès les premiers jours; au fur et à mesure de
l'avancement du cours, vous pourrez utiliser les méthodes présentées pour modifier ou améliorer votre algorithme prédictif.
Ajout le 28/10/2011: un 50000 enregistrements supplémentaires (compressés) pour l'apprentissage, à mettre dans le répertoire data. Vous disposez désormais au total d'un trentième des données.
Comment travailler?
Si l'objectif de ce projet est simple à comprendre, l'élaboration d'une
solution satisfaisante n'est pas si aisée : elle met en jeu différents aspects de l'apprentissage statistique, difficiles à combiner.
Un tel problème reste aujourd'hui un sujet de recherche actif.
Il conviendra donc, pour l'aborder efficacement, de procéder de façon progressive, avec méthode et humilité.
Vous vous attacherez à segmenter le problème en différentes tâches plus
simples, et/ou à vous fixer des objectifs intermédiaires que vous
puissiez résoudre en fonction de l'avancement du cours.
Vous pourrez, en particulier, travailler avec des modèles dont la
validité ne sera peut-être pas pleinement satisfaisante au vu de la nature des données.
Il vous faudra en tous cas savoir formuler des (sous-) problèmes que les
cours/TP vous permettent d'aborder, et savoir mettre en oeuvre des solutions algorithmiques.
Ce projet sera l'occasion de montrer votre aptitude à travailler de
façon autonome autour d'un problème de "machine-learning" : vous devrez être capables d'approfondir certains points
vus en cours grâce à la lecture de documents mis en références ou bien
que vous trouverez vous-même.
En ce qui concerne la programmation informatique, vous devrez montrer votre capacité à pouvoir utiliser rapidement des outils nouveaux.
Vous devrez par ailleurs être capables d'organiser efficacement le
travail en groupe, en vous appuyant sur les connaissances et sur les
qualités de chacun. Certains d'entre vous sont peut-être
moins familiers que d'autres avec le langage JAVA, certains auront éventuellement plus de facilités à comprendre certaines notions vues en cours. Le groupe doit être
capable de mettre la somme de ses compétences en adéquation avec
l'objectif, et vous devrez trouver une bonne articulation entre la
théorie et la mise en oeuvre pratique.
Il est possible que vous soyez amenés à répartir les travail en sous-équipes spécialisées
sur des tâches particulières : à vous d'organiser la
coordination inter-groupe entre exploration, synthèse et retour
d'expérience.
Vous rédigerez de façon progressive un rapport
expliquant vos tentatives, réussites, échecs et
interrogations. Au delà du score obtenu par votre algorithme final,
c'est surtout votre capacité à mettre en oeuvre une démarche scientifique/technique er votre esprit d'initiative qui seront
évalués.