Bienvenue dans le cours de programmation !
Equipe pédagogique
- Lison Blondeau-Patissier
- Alice Brenon
- Augustin Laouar
- François Schwarzentruber
prénom.nom@ens-lyon.fr en remplaçant ç par c
Ces notes de cours sont écrites au fur et à mesure par François Schwarzentruber.
Remerciement
Je tiens à remercier Michele Pagani pour son soutien, ainsi que les chargés de TP de l'année dernière : Alice Brenon et François Pitois. François a fourni un effet considérable pour réorganiser les feuilles de TP.
Quand ?
- Cours/TP mercredi matin de 10h15-12h15
- TP d'approfondissement, mardi 8h-10h 130/E001
Evaluation
- Un TP noté sur place, créneau habituel du TP, une des semaines
- Projet sur 3 semaines à un moment de l'année
- Examen final la semaine du 12-16 janvier 2026
- Une activité extra par groupe de 2-3. Par exemple :
- Projet Wikipedia (écrire/traduire/illuster des articles)
- Projet rédaction de quizz / création d'un jeu de cartes sur la programmation
- Présentation d'une notion en cours
Pourquoi ce cours ?
Programmer = écrire des programmes qu'un ordinateur peut exécuter.
- Pour vous :
- Vous serez chercheur ou chercheuse :
- Besoin de programmer des prototypes de recherche
- Participer à des développements logiciel de grande envergures (OCaml, Rocq, outils de vérification, librairie de bio-informatique etc.)
- Vous serez enseignant ou enseignante :
- Vous allez programmer des outils pour vos cours
- Vous allez enseigner la programmation
- Dans votre propre formation, vous serez amené à programmer :
- Besoin en programmation système : langage bas niveau, assembleur et C
- Besoin en apprentissage : Python et tensorflow
- Besoin en algorithmique : comprendre les structures de données
- Besoin en logique / KR / bases de données : solveurs, requêtes, etc.
- Besoin en mathématique : calcul formel, simulation numérique, etc.
- Besoin en robotique
- Vous serez chercheur ou chercheuse :
Enjeux
- Besoins
- Spécifique à une machine VS Générique
- Besoin de prototyper (le temps de développement compte)
- Besoin d'avoir un programme sûr (fusées)
- Besoin d'être très facile à utiliser
- Besoin d'être maintenable
- Besoin de travailler à plusieurs
- Besoin d'être facilement déployable
- Outils
- Langages
- Langages de bas-niveau : assembleurs, C, Rust
- Langages impératifs : fais-ci, fais-ça
- Langages fonctionnels : uniquement des applications de fonctions et donc pas d'effets de bord
- Langages logiques
- Langages de requêtes : SQL, SPARQL (pour wikidata)
- Langue naturelle avec des LLMs
- Bibliothèques
- Pour les maths : numpy
- Pour l'apprentissage : tensorflow
- Pour les contraintes : programmation linéaire, SAT, CSP
- Gestionnaire de paquets pour les bibliothèques : cargo en Rust, pip en Python, etc.
- Gestionnaire de versions : git
- Déployement : Docker, Kubernetes
- Vérification de programmes :
- Tests unitaires : pytest
- Model checking : esbmc
- Assistant de preuve : rocq
- Langages
Contenu du cours
This course covers the C programming language ![]() and Python
and Python  .
.
Motivation: why studying C and Python?
Cool to study both
With C and Python we cover various aspects of programming:
| C | Python |
|---|---|
| low-level | high-level |
| memory handled by hand | memory handled automatically |
| statically typed | dynamically typed |
| weak types | strong types |
| compiled language | compiled in byte-code, then interpreted |
| tedious to install librairies | very easy to install librairies, via pip <3 |
Noticeably:
- Possible to do bindings C/Python
- Actually many Python librairies are written in C, C++ etc.
- They are both successful languages
- They are languages used at agrégation d'informatique
Why C?
- C is simple (KISS!)
- With C, you will understand how your computer works
- Important for your system and architecture courses
- C is still used for system development (but not so much!)
- The syntax of C is in many languages
- A way to understand Rust, C++... and actually programming in general (and Tensorflow is coded in C++)
Why Python?
- Python is really really really used everyhere (data science, machine learning, software development, backend, etc.)
- Python has good libraries
- Django: Tutorial
- Python is elegant
- Python steals good features from other languages (Haskell, object-programming languages)
- Python is used in education
- A way to understand OOP, Javascript, other script languages
- Python has a strong community
Good practice
- git
- tests
- bonnes structures
- commentaires (spécifications)
- good variable names, etc.
- encapsulation
- abstraction
Exercices
- Collect few software or libraries you use and look in which languages they have been developped
- Read code of the favorite software
Histoire
- https://fr.wikipedia.org/wiki/Histoire_des_langages_de_programmation
- https://en.wikipedia.org/wiki/Timeline_of_programming_languages
- https://francoisschwarzentruber.github.io/graph_of_programming_languages/
Premières machines
La machine d'Anticythère (avant 87 av. JC) servait à réaliser des calculs d'astronomie :

La 
Premières machines programmables
Le

Note G de

C'est un enfer : les variables s'appellent $$V_1, V_2, V_3, \dots$$ Ne pas faire ça !
1950-1960 : les premières bonnes idées
FORTRAN
FORTRAN (FORmula TRANslator) est un langage pour le calcul scientifique et numérique. Il a été créé en 1957 par John Backus :

Voici un exemple de programme en FORTRAN (première version) :
C AREA OF A TRIANGLE WITH A STANDARD SQUARE ROOT FUNCTION
C INPUT - TAPE READER UNIT 5, INTEGER INPUT
C OUTPUT - LINE PRINTER UNIT 6, REAL OUTPUT
C INPUT ERROR DISPLAY ERROR OUTPUT CODE 1 IN JOB CONTROL LISTING
READ INPUT TAPE 5, 501, IA, IB, IC
501 FORMAT (3I5)
C IA, IB, AND IC MAY NOT BE NEGATIVE OR ZERO
C FURTHERMORE, THE SUM OF TWO SIDES OF A TRIANGLE
C MUST BE GREATER THAN THE THIRD SIDE, SO WE CHECK FOR THAT, TOO
IF (IA) 777, 777, 701
701 IF (IB) 777, 777, 702
702 IF (IC) 777, 777, 703
703 IF (IA+IB-IC) 777, 777, 704
704 IF (IA+IC-IB) 777, 777, 705
705 IF (IB+IC-IA) 777, 777, 799
777 STOP 1
C USING HERON'S FORMULA WE CALCULATE THE
C AREA OF THE TRIANGLE
799 S = FLOATF (IA + IB + IC) / 2.0
AREA = SQRTF( S * (S - FLOATF(IA)) * (S - FLOATF(IB)) *
+ (S - FLOATF(IC)))
WRITE OUTPUT TAPE 6, 601, IA, IB, IC, AREA
601 FORMAT (4H A= ,I5,5H B= ,I5,5H C= ,I5,8H AREA= ,F10.2,
+ 13H SQUARE UNITS)
STOP
END
De bonnes idées :
- instruction pour lire, écrire, des commentaires
- prémisses du
if: ici il est ternaire (saut si négatif, si nul, si positif)
De mauvaises idées :
- que des
GO TO
COBOL
COBOL (COmmon Business Oriented Language) pour des applications de gestion a une syntaxe compréhensible par un humain.
ADD montant TO total-jour total-mois total-annee.
Il a été créé en 1959 par le Short Range Committee, dont Grace Hopper.

De bonnes idées :
-
proche de la langue naturelle (ah si Grace Hopper avait connu les LLMs !)
-
types structurés
01 NomPrenom. 05 Prenom PIC X(20). 05 Nom PIC X(20).
PIC (pour PICTURE) indique le type des données, ici des caractères (X) au nombre de 20.
LISP
En 1960, LISP (LISt Processor) was created by

(defun factorial (n)
(if (= n 1)
1
(* n (factorial (- n 1)))))
Plein de bonnes idées (cf. https://paulgraham.com/diff.html) :
-
Des vrais
if -
Les fonctions sont des objets comme les autres
-
Il n'y a que des pointeurs (comme dans Python, Java, Javascript, etc.)
-
Pas de gestion de la mémoire explicite car il y a un ramasse-miette
-
un type 'symbole'
-
Utilisation du langage lui-même pour représenter des données. C'est du JSON, du XML avant l'heure. D'ailleurs toujours utilisé en planification automatique avec le Planning Domain Definition Language.
(define (problem strips-gripper2) (:domain gripper-strips) (:objects rooma roomb ball1 ball2 left right) (:init (room rooma) (room roomb) (ball ball1) (ball ball2) (gripper left) (gripper right) (at-robby rooma) (free left) (free right) (at ball1 rooma) (at ball2 rooma)) (:goal (at ball1 roomb))) -
Mélange entre programme et données, la fonction
eval
ALGOL
En 1960, ALGOL60 (ALGOL58 existait mais c'était des prémisses) est créé, avec notamment John Backus et Peter Naur, mais aussi John McCarthy et plein d'autres. Le comité s'est réuni à Paris du 11 au 16 janvier 1960.
procedure Absmax(a) Taille:(n, m) Resultat:(y) Indices:(i, k);
value n, m; array a; integer n, m, i, k; real y;
comment Dans la procédure Absmax (a, n, m, y, i, k)
le plus grand élément en valeur absolue de la matrice a de taille
n par m est transféré à y et les indices de cet élément à i et k ;
begin integer p, q;
y := 0; i := k := 1;
for p:=1 step 1 until n do
for q:=1 step 1 until m do
if abs(a[p, q]) > y then
begin
y := abs(a[p, q]);
i := p; k := q;
end
end Absmax
Bonnes idées :
- des blocs
BEGIN,END
John Backus et Peter Naur sont aussi les inventeurs de la Backus–Naur form (BNF). Voici par exemple une grammaire en BNF pour la logique propositionnelle :
$$\phi, \psi, \dots ::= p \mid (\phi \lor \psi) \mid (\lnot \phi)$$
C'est Charles Antony Richard Hoare qui a écrit le premier compilateur pour ALGOL 60.

Charles Antony Richard Hoare est aussi connu :
- l'invention du
tri rapide - la
logique de Hoare
Il a écrit : « Voici un langage très en avance de son temps, il n'a pas seulement été une amélioration de ses prédécesseurs mais aussi une amélioration de presque tous ses successeurs ».

1960-1980
Simula
En 1965, dans “Record Handling", Charles Antony Richard Hoare évoque les prémisses de la programmation orientée objet. Simula 67 (Simple universal language), inventé à Oslo par Ole-Johan Dahl and Kristen Nygaard. Comme surcouche d'Algol 60, est le premier langage conçu pour pouvoir intégrer la programmation orientée objet et la simulation par événements discrets.
Begin
Class Glyph;
Virtual: Procedure print Is Procedure print;;
Begin
End;
Glyph Class Char (c);
Character c;
Begin
Procedure print;
OutChar(c);
End;
Glyph Class Line (elements);
Ref (Glyph) Array elements;
Begin
Procedure print;
Begin
Integer i;
For i:= 1 Step 1 Until UpperBound (elements, 1) Do
elements (i).print;
OutImage;
End;
End;
Ref (Glyph) rg;
Ref (Glyph) Array rgs (1 : 4);
! Main program;
rgs (1):- New Char ('A');
rgs (2):- New Char ('b');
rgs (3):- New Char ('b');
rgs (4):- New Char ('a');
rg:- New Line (rgs);
rg.print;
End;
Langage C
Le langage C est un des premiers langages de programmation système, est développé par Dennis Ritchie et Ken Thompson pour le développement d'Unix aux laboratoires Bell entre 1969 et 1973.
#include <stdio.h>
int main(void)
{
printf("hello, world\n");
return 0;
}
BASIC
1964 - BASIC (Beginner's All-purpose Symbolic Instruction Code) est un langage pour le grand public.
'Voici un petit code fait en BASIC moderne
INPUT "Quel est votre nom"; UserName$ 'On demande le nom de l'utilisateur
PRINT "Bonjour "; UserName$
DO
INPUT "Combien d'étoiles voulez-vous"; NumStars 'On demande le nombre d'étoiles de l'utilisateur
Stars$ = ""
Stars$ = REPEAT$("*", NumStars) '<-ANSI BASIC
'Stars$ = STRING$(NumStars, "*") '<-MS BASIC
PRINT Stars$
DO
INPUT "Voulez-vous plus d'étoiles"; Answer$
LOOP UNTIL Answer$ <> ""
LOOP WHILE UCASE$(LEFT$(Answer$, 1)) = "O"
PRINT "Au revoir ";
FOR A = 1 TO 200
PRINT UserName$; " ";
NEXT A
PRINT
Le typage est implicite, et si les variables dont le nom termine par $ sont des chaînes de caractères.
Smalltalk
Smalltalk (milieu des années 1970) est l'un des premiers langages de programmation à disposer d'un environnement de développement intégré complètement graphique.
| rectangles aPoint|
rectangles := OrderedCollection
with: (Rectangle left: 0 right: 10 top: 100 bottom: 200)
with: (Rectangle left: 10 right: 10 top: 110 bottom: 210).
aPoint := Point x: 20 y: 20.
collisions := rectangles select: [:aRect | aRect containsPoint: aPoint].
PROLOG
Prolog (PROgrammation LOGique), défini en 1972 par Colmerauer, Roussel et Kowalski (en) est le premier langage de programmation logique.
frère_ou_sœur(X,Y) :- parent(Z,X), parent(Z,Y), X \= Y.
parent(X,Y) :- père(X,Y).
parent(X,Y) :- mère(X,Y).
mère(trude, sally).
père(tom, sally).
père(tom, erica).
père(mike, tom).
ML
ML (Meta Language) inventé par Robin Milner en 1973, construit sur un typage statique fort et polymorphe au-dessus de Lisp, pionnier du langage de programmation généraliste fonctionnel.
fun fac (0 : int) : int = 1
| fac (n : int) : int = n * fac (n - 1)
Pascal
Pascal a été créé par Niklaus Emil Wirth en 1970 conçu pour l'enseignement.
program HelloWorld(output);
begin
writeln('Hello World');
readln;
end.
SQL
SQL (Structured Query Language) est un langage pour écrire des requêtes à une base de données. Créé en 1974 par Donald D. Chamberlin et Raymond F. Boyce.
SELECT nom, service
FROM employe
WHERE statut = 'stagiaire'
ORDER BY nom;
1980-1990 : mélanger performance et programmation objet
Ada
En 1983, Ada créé Jean David Ichbiah. C'est un langage impératif et fortement typé avec compilateur certifié.
Il repose sur de la programmation par contrat. Autrement dit, on peut écrire les préconditions et postconditions directement dans le langage.
procedure Put_Line (File : in File_Type; Item : in String)
with Pre => (Is_Open (File)),
Post => (Line (File) = Line (File)’Old + 1);
On peut aussi définir des types "sémantiques" :
subtype Prime is Integer range 2 .. Integer’Last
with Dynamic_Predicate
=> (not (for some N in 2 .. Prime - 1
=> Prime mod N = 0));
C++
C++ est créé en 1983 par Bjarne Stroustrup.

#include<iostream>
int main()
{
std::cout << "Hello, new world!\n";
}
Perl
En 1987, Perl (Practical Extraction and Reporting Language) est créé par Larry Wall. En 2019, Perl 6 s'appelle Raku. L'objectif est de faciliter le reporting dans la console.
#!/usr/bin/env perl
use strict;
use warnings;
my ( $remaining, $total );
$remaining=$total=shift(@ARGV);
STDOUT->autoflush(1);
while ( $remaining ) {
printf ( "Remaining %s/%s \r", $remaining--, $total );
sleep 1;
}
print "\n";
1990-2010 : développer plus vite et... Internet !
1990 - Haskell 1991 - Python 1993 - Lua 1994 - ANSI Common Lisp 1995 - Java 1995 - PHP 1995 - Ruby 1996 - JavaScript 1996 - OCaml 2001 - C#
Python
L'ancêtre de Python est le langage ABC développé au CWI (Centrum voor Wiskunde en Informatica) par Leo Geurts, Lambert Meertens, et Steven Pemberton. Le but était d'être simple à utiliser. Guido van Rossum participe au projet.
HOW TO RETURN words document:
PUT {} IN collection
FOR line IN document:
FOR word IN split line:
IF word not.in collection:
INSERT word IN collection
RETURN collection
Guido van Rossum développe un langage de script à partir de 1989 : il l'appelle Python. En février 1991, Python 0.9.0 est publié.
def words(document):
collection = set()
for line in document:
for word in line.split(" "):
if word not in collection:
collection.add(word)
return collection
2010 : un monde encore plus sûr, ou pas
Go
Go est utilisé pour de la programmation système. Inventé par Google en 2009-2010.
package main
import "fmt"
func main() {
fmt.Println("Hello, world")
}
Rust
En 2010, Rust voit le jour.
#![allow(unused)] fn main() { enum Forme { Point, // une forme peut être un point, sans données attachées. Cercle(f64), // une forme peut être un cercle, caractérisé par son rayon. Rectangle(f64, f64), // une forme peut être un rectangle, caractérisé par les longueurs de deux de ses côtés adjacents. } fn aire(f: Forme) -> f64 { match f { Forme::Point => 0.0, Forme::Cercle(rayon) => rayon * rayon * 3.1415926535897932384626433832795, Forme::Rectangle(cote_a, cote_b) => cote_a * cote_b, } } }
Typescript
TypeScript - version typé fortement de Javascript
Programmation réactive
La programmation Web demande d'assurer l'adéquation entre le contenu de variables du programme et l'affiche. Pour cela, la programmation réactive permet d'écrire
<div>{{x}}</div>
où la page HTML se met à jour automatiquement lorsque le contenu de la variable x change. Il y a plusieurs framework : React, Vue, Svelte.
La langue naturelle ?
Quid de la programmation du futur ? Si on donne ce prompt à un LLM, ça fonctionne :
Convertit moi ce tableau en JSON.
ou alors :
Donne moi un programme qui convertit n'importe quel tableau en JSON.
Planning 2025-2026
-
Mercredi 10/09 : annulé (grève)
-
Mercredi 17/09 : histoire, initiation C, git
-
Mercredi 24/09 : plusieurs fichiers sources, make
-
Mercredi 1/10 : pointeurs
-
Mercredi 8/10 chaînes de caractères et git (branches)
-
Mercredi 15/10 séance annulée (mais début des projets projet prog et pédagogiques)
-
Mercredi 22/10 programmation objet
-
Vacances du 27/10 au 31/10
-
Mardi 4/11 Pas de TP (visite labo). Mercredi 5/11 Pas de cours (visite labo),
-
Les mardis à partir de là : projet
-
Mercredi 12/11 concurrence et parallélisation
-
Mardi 18/11 TP noté
-
Mercredi 19/11 solveurs, itérateurs et autres Pythonneries
-
Mercredi 26/11 RAII, C++
-
Mercredi 3/12 Présentations pédagogiques (amphi B)
-
Mercredi 10/12 Présentations pédagogiques (amphi B)
-
Mercredi 17/12 Soutenances de projets de programmation (10h15-12h15 amphi E et 13h30-15h30 amphi B)
-
Semaine du 05/01 : peut-être une séance de rattrapage
-
Semaine du 12/01 : examen final
Histoire du C

https://www.trytoprogram.com/images/C-programming-history.jpg
{kind=link}
| When | What |
|---|---|
| 1972 | Creation of C by Dennis Ritchie |
| 1973 | Re-implementation of the Unix kernel |
| 1978 C78 | first edition of the book The C Programming Language by Brian Kernighan |
| and Dennis Ritchie and improvements of the language (functions returning struct) | |
| 1989 C89 | First standardization of C, locales (taking into account user's languages) |
| 1999 C99 | inline functions! complex numbers! variable-length arrays! |
| 2011 C11 | generic macros, multi-threading in the standard |
VSCode ou VSCodium
Installer un outil pour formatter correctement du code C
sudo apt-get install clang-format
| Pour faire... | Faire |
|---|---|
| Sélectionner une ligne entière | Ctrl + L |
| Bien formater le fichier | Ctrl + Maj + I |
| Fermer le fichier courant | Ctrl + W |
| Pour renommer une variable/function | F2 |
Initiation au C
Nous allons écrire de petits programmes qui écrivent dans le terminal. Le but est d'apprendre :
- à compiler un seul fichier C (compiler = transformer le programme C texte en fichier exécutable que la machine peut exécuter)
- écrire un programme C basique (sans pointeur)
⌛ Plus tard, on fera des programmes avec plusieurs fichiers, et on verra les pointeurs.
Mon premier programme C
Voici mon premier programme en C :
#include <stdio.h>
int main() {
printf("Bienvenue à l'ENS Lyon/n");
return 0;
}
Vous pouvez mettre ce contenu dans un fichier :
🖹 programme.c
#include <stdio.h>permet d'utiliser des fonctions pour écrire et lire dans la console.

int main()est le début de la définition de la fonction principalemain. Sa définition commence par le type que renvoie la fonction, ici un entierint. La fonction renvoie0quand tout s'est bien passé. Elle renvoie une valeur non nulle pour signaler une erreur.printfpermet d'écrire dans la console.return 0;quitte la fonction et renvoie0.
#include <stdio.h>
#include <stdlib.h>
int main() {
printf("Bienvenue à l'ENS Lyon/n");
return EXIT_SUCCESS;
}
Compilation
Le fichier 🖹 programme.c n'est pas exécutable : il s'agit d'un fichier texte que le processeur ne comprend pas. Pour construire un fichier exécutable par la machine, on utilise un compilateur. Ce processus s'appelle la compilation.

Pour compiler, taper :
gcc programme.c
On obtient un nouveau fichier qui est exécutable :
🖹 programme.c
⚙ a.out
et que l'on peut lancer :
./a.out
Bibliothèque standard
Le langage C est fourni avec la bibliothèque standard. Elle offre des fichiers appelés fichiers d'en-tête ou fichier header. Par exemple, le fichier stdio.h offre les fonctionnalités d'entrées/sortie sur la console. Les fichiers d'en-tête sont normalement disponibles dans le dossier usr/include. Ils contiennent des signatures de fonctions.
⌛ On peut aussi créer des fichiers header nous-même, ou alors utiliser ceux d'une bibliothèque non-standard (comme la bibliothèque raylib pour dessiner à l'écran !).
Voici les fichiers d'en-tête de la bibliothèque standard :
Bibliothèque standard C (C23)
│
├── Entrées / Sorties & Utilitaires
│ ├── <stdio.h> (E/S standard : printf, scanf, fopen…)
│ ├── <stdlib.h> (malloc, exit, atoi, rand…)
│ ├── <string.h> (strlen, strcpy, memcpy…)
│ ├── <time.h> (time, clock, struct tm…)
│ ├── <locale.h> (setlocale, conventions régionales)
│ └── <uchar.h> (Unicode UTF-16/UTF-32)
│
├── Chaînes & Caractères
│ ├── <ctype.h> (isalpha, tolower…)
│ ├── <wchar.h> (wchar_t, fonctions chaînes larges)
│ └── <wctype.h> (classification/conversion wchar_t)
│
├── Mathématiques
│ ├── <math.h> (sin, cos, sqrt…)
│ ├── <complex.h> (nombres complexes)
│ ├── <tgmath.h> (maths génériques type-safe)
│ ├── <float.h> (caractéristiques flottants)
│ └── <fenv.h> (contrôle environnement flottant)
│
├── Types & Limites
│ ├── <stddef.h> (size_t, NULL, ptrdiff_t…)
│ ├── <stdbool.h> (bool, true, false)
│ ├── <stdint.h> (entiers fixes : int32_t…)
│ ├── <inttypes.h> (formatage et macros pour stdint)
│ ├── <limits.h> (INT_MAX, etc.)
│ ├── <stdalign.h> (alignement mémoire, alignof…)
│ ├── <stdnoreturn.h>(_Noreturn)
│ └── <iso646.h> (alias syntaxiques : and, or, not…)
│
├── Gestion d’erreurs & Signaux
│ ├── <assert.h> (assert)
│ ├── <errno.h> (errno, codes d’erreur)
│ ├── <signal.h> (SIGINT, SIGSEGV…)
│ └── <setjmp.h> (setjmp/longjmp)
│
├── Fonctions variadiques
│ └── <stdarg.h> (va_list, va_start, va_arg…)
│
└── Concurrence (C11+)
├── <threads.h> (threads, mutex, cond vars)
└── <stdatomic.h> (atomiques)
Entrées-sorties
stdio.h est le fichier pour de la bibliothèque standard (std) pour les entrées-sorties (io).
Pour utiliser ces fonctions, on écrit :
#include <stdio.h>
Ecrire sur stdout (sortie standard)
La sortie standard est typiquement la console, mais cela peut être un fichier, ou alors une entrée à un autre programme.
putchar('c') écrit le caractère c dans le terminal.
printf est la fonction pour écrire d'un coup des informations plus compliquées ✎ :
printf("Bonjour");
printf("Bonjour\n");
printf("Voici votre identifiant : %d", id);
printf("Voici votre nouveau prénom : %s", prenom);
printf("Voici votre nouveau prénom et votre identifiant : %s %d", prenom, id);
⚠ Ne jamais écrire printf(dataFromTheUser) car l'utilisateur pourrait écrire des %s, %d, voire des %n qui écrivent dans la mémoire. Le comportement peut être inattendu, et c'est faille de sécurité garantie :).
Lire l'entrée stdin (entrée standard)
L'entrée standard est typiquement ce qu'écrit l'utilisateur dans la console, mais cela peut être un fichier, ou alors une sortie d'un autre programme.
La fonction getchar() renvoie le prochain caractère sur l'entrée puis le consomme, c'est-à-dire que la prochaine fois que l'on exécute getchar() on lira le prochain caractère. getchar() renvoie EOF (end of file) si c'est fini.

scanf est la fonction pour lire des informations plus compliquées que l'utilisateur écrit dans la console ou de manière générale dans stdin ⌨ :
int n;
scanf("%d", &n);

On peut aussi lire plusieurs variables d'un coup.
int n, m;
scanf("%d", &n, &m);
La fonction scanf renvoie le nombre de variables qui ont été affectées correctement.
int n, m;
int nbLus = scanf("%d %d", &n, &m);
Spécification de formats
| Spécificateur | Type attendu | Exemple | Résultat affiché |
|---|---|---|---|
%d ou %i | int (entier signé) | printf("%d", -42); | -42 |
%u | unsigned int | printf("%u", 42); | 42 |
%o | entier non signé (octal) | printf("%o", 42); | 52 |
%x | entier non signé (hexadécimal min.) | printf("%x", 42); | 2a |
%X | entier non signé (hexadécimal maj.) | printf("%X", 42); | 2A |
%c | char (caractère) | printf("%c", 'A'); | A |
%s | chaîne (char*) | printf("%s", "Hello"); | Hello |
%f | float ou double (décimal) | printf("%f", 3.14); | 3.140000 |
%.2f | float ou double (précision) | printf("%.2f", 3.14); | 3.14 |
%e / %E | float ou double (scientifique) | printf("%e", 1234.0); | 1.234000e+03 |
%g / %G | float ou double (auto %f ou %e) | printf("%g", 1234.0); | 1234 |
%p | pointeur (void*) | printf("%p", ptr); | 0x7ffee2bff6c0 |
%% | affiche % | printf("50%%"); | 50% |
Quelques éléments du langage C
Une déclaration de variable est un morceau de code qui renseigne le type d'une variable. Par exemple :
int x;
Il y a pleins de types primitifs : int, long, unsigned int, char, bool (avec #include <stdbool.h>).
Une instruction est un morceau du programme qui ne renvoie rien. Par exemple, printf("aïe");
Une expression est un morceau du programme qui renvoie une valeur. Par exemple 1+2. Mais aussi x = 42 qui renvoie... 42.
Incrémentation
Considérons l'instruction (qui est aussi une expression)
x = 42;
- Both expressions
x++and++xincrementx. - The value of the expression
x++is 42. - The value of expression
++xis 43.
L'instruction (qui est aussi une expression) suivante
x += 3;
ajoute 3 à x.
Boucle for
for(int i = 0; i < n; i++)
...
for(int i = 0; i < n; i++) {
...
}
En fait, la boucle for en C est puissante. Elle a l'expressivité des boucles while :
for(expr1; expr2; expr3) {
...
}
est équivalent à
expr1;
while(expr2) {
...
expr3;
}
La fonction main
Un programme C contient toujours une fonction main qui est la fonction appelée quand on exécute le programme :
#include <stdlib.h>
int main() {
...
return EXIT_SUCCESS;
}
On verra plus tard une signature plus compliquée pour main car on peut gérer des arguments donnés au programme.
Utilisation du compilateur
gcc -Wall -pedantic -ainsi -std=c99 programme.c -o programme
| Options | Meaning |
|---|---|
| -Wall | enables all compiler's warning messages |
| -Wextra | still a bit more warnings |
| -pedantic | enables all compiler's warning messages |
| -ansi | turns off gcc features that are not in the ANSI C |
| -std=c99 | ANSI C99 |
| -std=c11 | ANSI C99 |
| -o programme | tells that the output is the file programme |
Exercices
Triangle d'étoiles
Ecrire un programme qui prend demande à l'utilisateur/rice un nombre entier n puis affiche un triangle d'étoiles sur n lignes. Par exemple si n vaut 5, on affiche :
*
**
***
****
*****
Pyramide
Même chose avec une pyramide :
*
***
*****
*******
Nombre de caractères dans le texte sur stdin
En utilisant getchar(), écrire un programme nombreligne.c qui lit stdin et sur donne le nombre de lignes dans l'entrée.
Par exemple sur
./nombreligne < textExemple.txt
il donne le nombre de lignes dans le fichier texte textExemple.txt.
- Pareil avec le nombre de lignes
- Pareil avec le nombre de mots
Occurrences de caractères
Dans cet exercice, vous aurez besoin d'un tableau d'entiers de taille 26 déclaré avec int A[26];. On accède au i-ème élément du tableau A avec A[i]. On rappelle que chaque caractère est un nombre entre 0 et 255, codé sur 8 bits. Si c est un char, on peut écrire c - 'a' pour faire la différence entre le code de c et celui de la lettre 'a'.
Ecrire un programme qui lit stdin et qui affiche un histogramme du nombre des occurrences des lettres (on ignore les autres caractères, les chiffres, etc.) comme :
a ***
b ******
c **
d *
e ************
z ***
Variables
La portée (scope) d'une variable est la portion de code dans laquelle la variable peut être utilisée.
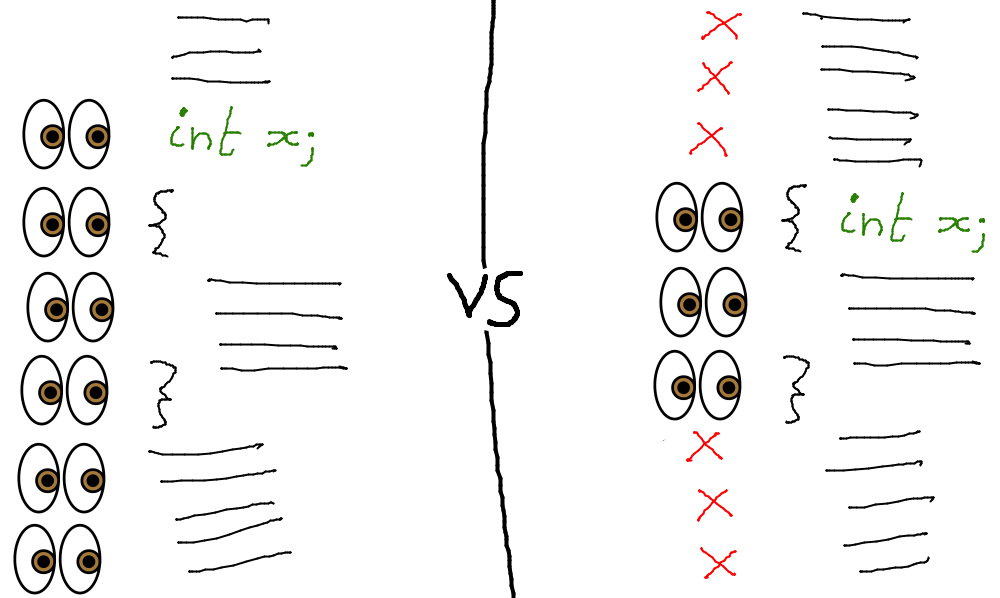
La durée de vie (life-time) d'une variable est la durée d'existence d'une variable.
| Scope | Life-time | |
|---|---|---|
| Global variables | All | Always |
| Variables in functions | Function | Function |
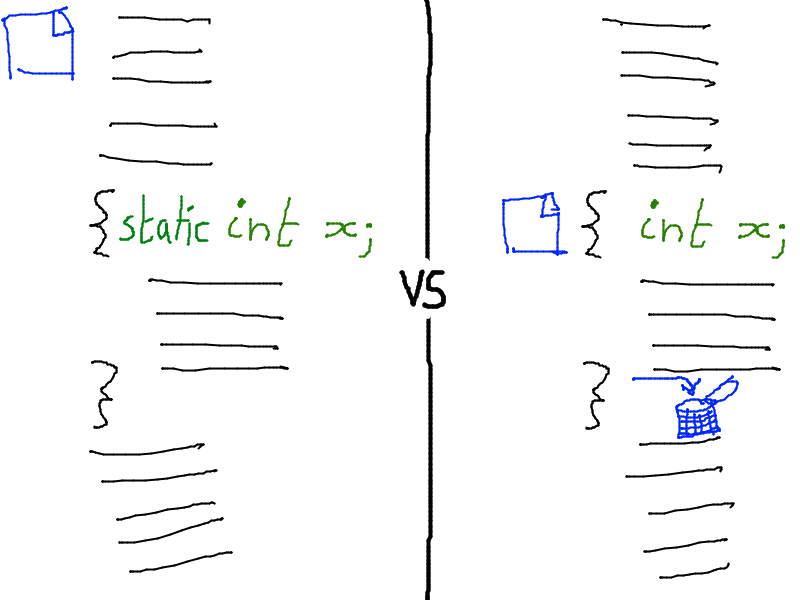
| Static variables in functions | Function | Always |
Les variables statiques peuvent servir pour :
- faire un compteur et cacher le contenu du compteur en dehors
- faire une fonction pour le drag drop avec la souris (on stocke/cache la position précédente de la souris)
Mémoire
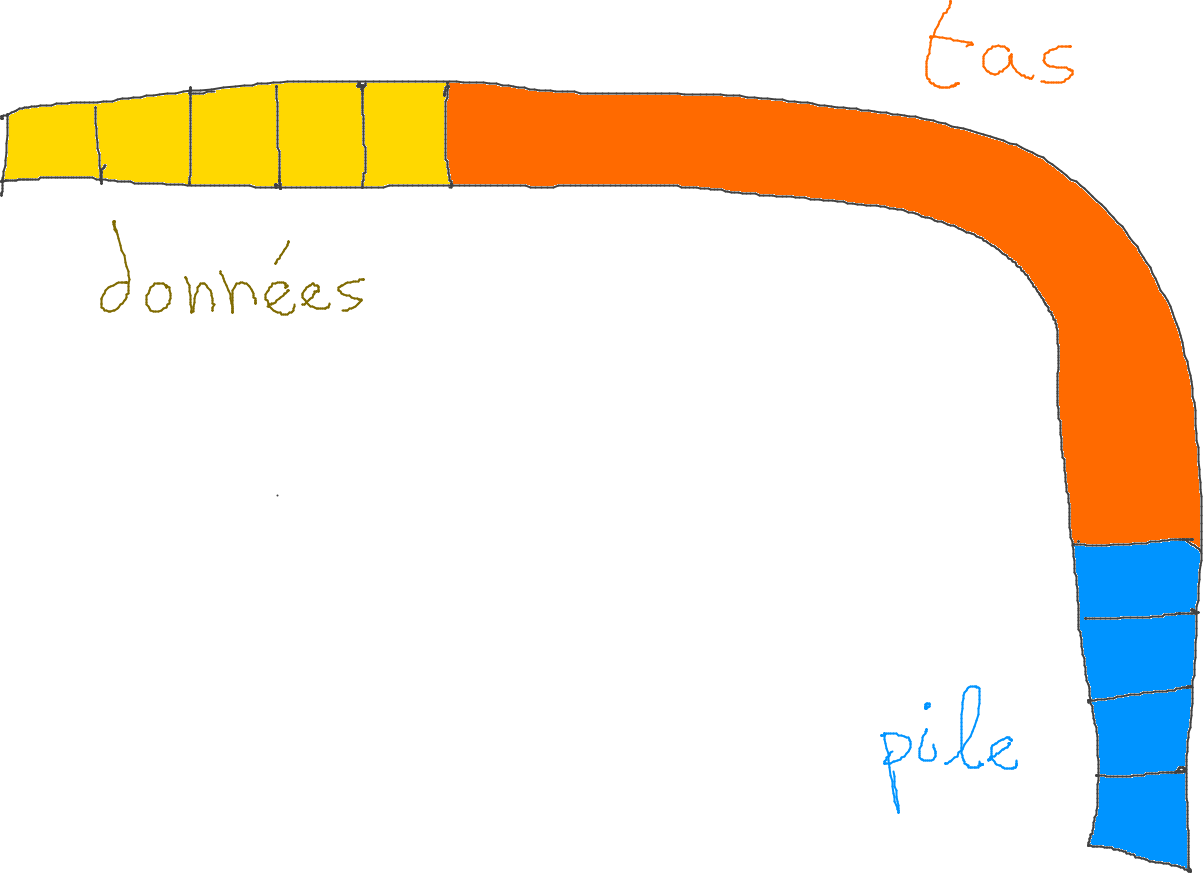
La mémoire allouée pour un programme est divisée en trois parties :
- Segment de données. On y trouve les variables globales et les variables statiques.
- Pile d'appels. On y trouve les variables locales à une fonction. Les tableaux locaux sont stockées sur la pile aussi.
- Le tas mémoire. C'est pour y mettre des données dont on ne connait pas à l'avance la taille, ou dont la taille peut modifiée au cours du programme (structure de données comme des tableaux redimensionnables, des listes chaînées, etc.).
Typage en C
Le type en C sert à dire combien d'octets prend une variable.
La fonction sizeof renvoie combien d'octets sont utilisé pour stocker un certain type / une certaine variable.
| sizeof(truc) | utilise ... octets |
|---|---|
| sizeof(char) | 1 |
| sizeof(int) | 4 |
int x;
printf("%d\n", sizeof(x));
int A[5];
printf("%d\n", sizeof(A));
Conversion implicite
1 + 2.3f
Casting
int i = 2;
int j = 3;
float quotient = 2/3;
Oh non, quotient vaut 0. Mais on peut caster :
quotient = ((float) 2) / 3
Le C est de bas niveau...
Voici un site où on peut compiler du code C et voir le résultat en assembleur :
https://godbolt.org/
Exercices
Génération de labyrinthes
Proposer un algorithme aléatoire pour générer un labyrinthe comme
XXXXXXXXXXXXXXX
X X X X
X XXX X X X XXX
X X X X X X
X X XXXXX XXX X
X X X X X
X X X X XXXXX X
X X X X X X X
X XXX X X X X X
X X X X X X
X X XXX X XXX X
X X X X X X
X XXXXXXX X X X
X X X
XXXXXXXXXXXXXXX
Il s'agit de produire un tableau A 2D de taille n x m où n et m sont des entiers impairs avec :
- A[i, j] =
'X'ou' ' - A[0, j], A[i, 0], A[n-1, j], A[i, m-1] contiennent
'X'; - A[i, j] =
'X'lorsque i et j sont pairs - A[i, j] =
' 'lorsque i et j sont impairs - Le graphe G est un arbre, où G est le graphe non orienté (V, E) où V sont les couples (i, j) dans {1, 3, .., n-2} x {1, 3, ..., m-2} et E contient les arêtes {(i, j), (i', j')} avec :
- i' == i+2 et j'== j et A[i+1, j] ==
' ' - ou i' == i et j' == j+1 et A[i, j+1] ==
' '
Prochaine séance
Nous allons utiliser la bibliothèque raylib pour pouvoir afficher des dessins (rectangles, points, lignes, etc.) à l'écran :).
- Jeu vidéo comme
agar.io - Afficher une fractale comme celle de mandelbrot
- Promenade aléatoire
- Appartenance d'un point à un polygone ?
- parcours de Graham
Pour aller plus loin
- https://emscripten.org/ Pour développer des programmes qui tournent sur le Web
- https://cs50.readthedocs.io/style/c/
- https://www.gnu.org/prep/standards/html_node/Writing-C.html#Writing-C
- Fonctions de base en langage C sur wikiversité
- Du matériel sur la génération de labyrinthes
Types primitifs
Entiers non signés
Les types entiers non signés (comme unsigned int, unsigned long, unsigned char etc.) sur n bits permettent de stocker des valeurs entières entre 0 et
| Type | Nombre de bits |
|---|---|
int | 32 |
char | 8 |
short | 16 |
long | 32 ou 64 |
long long | 64 |
- Quelles sont les valeurs possibles pour un
unsigned char?Entre \(0\) et \(2^{8}-1\) autrement ditentre 0 et 255.
Entiers signés
Les types entiers signés (comme int, long, char etc.) sur n bits permettent de stocker des valeurs entières entre char qui est souvent non signé, mais pas toujours.
-
Quelles sont les valeurs possibles pour un
signed char?Entre \(-2^{7}\) et \(2^{7}-1\) autrement dit entreEntre -128 et 127. -
Quelles sont les valeurs possibles pour un
char?Généralement, entre \(0\) et \(2^{8}-1\) autrement dit entreEntre 0 et 255. En effet, charest non signé par défaut. -
Pour quelle raison
charest-il non signé par défaut ?Pour faire le lien avec les caractères ASCII (nombres entre 0 et 127) puis ISO-8859-1 qui associe des caractères comme é, è etc. à des nombres entre 128 et 255. Il y a d'autres codages comme Windows-1252.
Représentations
Octale
En ajoutant le symbole 0, on écrit un nombre entier en représentation octale :
02322
- Combien vaut
051?5×8 + 1 = 41 (quarante et un).
hexadécimale
Avec 0x, pareil mais c'est en hexadécimal :
0x4D2.
- Combien vaut
051?5×16 + 1 = 81 (quatre-vingt un).
Nombres flottants
Il n'y a pas de nombres flottants non signés.
| Type | Nombre de bits | Exemples |
|---|---|---|
float | 32 | 12.34F |
double | 64 | 12.34, 12.e-4 |
long double | 80 ou 128 | 12.34L |

Conversions
Implicites
On convertit de int à float
float x = 1;
Explicites avec cast
L'inverse, convertir n'est pas automatique, il faut "caster" :
float x = ((float) 2) / 3;
- Comment vaut
2/3?0 car /sur des entiers est la division euclidienne en C. - Comment vaut
((float) 2) / 3?0.666666... car /sur des floats est la division euclidienne en C.
Le shell
Pourquoi ?
- Parce que les interfaces graphiques n'offrent pas autant d'automatisation du terminal
- Impossible de donner des arguments à un programme avec une interface graphique
- Parce que même des petits ordinateurs ont un terminal
- Parce que communiquer avec un ordinateur distant c'est plus simple en terminal
Invite de commande
L'invite de commande ressemble à ça :
nomdemachine:endroitoùonest$
En image :
💻:📌$
où 💻 est le nom de la machine et 📌 est le chemin où aller.
Par exemple petitchat:~/Documents/rapports.
où ~ désigne le répertoire home.
Basic commands
| To do... | write |
|---|---|
Going in the directory <oùaller> | cd <oùaller> |
| Going to the home directory | cd ~ |
| List the files | ls and better ls -l |
| Create a directory | mkdir <name> |
| Remove/delete sth | rm <what> |
| Search inside a file | grep whatIwantToSearchInsideTheFile FileName |
cd= change directorypwd= print working directory
Où sont mes programmes ?
Quand vous tapez python, gcc, ou autres dans le terminal, ça lance le programme. Mais où est le programme ? Il n'est pourtant pas dans le répertoire courant ! Pour savoir où se trouve un programme :
which python
Variable PATH
En fait, il y a une variable dite d'environnement qui s'appelle PATH et qui stocke les chemins où il faut regarder pour trouver un programme.
On peut afficher le contenu de la variable PATH :
echo $PATH
Modification de PATH
Pour vos besoins personnels, vous pouvez modifier le fichier ~/.profile qui peut modifier la variable PATH pour rajouter un nouveau chemin.
Une fois modifié, pour que le bash lise le fichier, on fait :
source ~/.profile
Le manuel
man echo
man ls
Redirection = reading/writing data from files
By default
By default, a program is just taking its input in the terminal (stdin) and outputs in the terminal (stdout).
Input from a file
./monprogramme < inputTextFile.txt

./monprogramme < inputTextFile.txt > outputTextFile.txt

On peut aussi utiliser >> pour ajouter des données à un fichier (s'il existe, sinon ça le crée) alors que > écrase le contenu.
./monprogramme < inputTextFile.txt >> outputTextFile.txt

Tube : enchaîner des programmes

ls -l | grep key | less
- list of the files, one per line
- then we keep the lines containing the word "key"
- then we show the result in a scrolling page with
less
Gestion des droits des fichiers sous UNIX
Connaître les droits d'un fichier
Avec ls -l, on connaît les droits des fichiers dans le répartoire courant. Avec ls -l fichier.txt, on connaît les droits du fichier fichier.txt.
Une ligne comme
-rwxr-xr-x 1 fschwarz logica 25648 Oct 13 13:56 a.out
se lit comme :
| Type de fichier | Droit du propriétaire 👩 | Droit du groupe 🏠 | Droit des autres 🐱🐶 | Nom du propriétaire 👩 | Nom du groupe 🏠 |
|---|---|---|---|---|---|
- | r w x | r - x | r - x | fschwarz | logica |
où
rsignifie que l'on peut lire le fichier 👁wsignifique que l'on peut écrire 🖊xsignifie que l'on peut exécuter ⚙
Le type de fichier peut être :
| Symbole | Type de fichier | Exemple |
|---|---|---|
| - | Fichier régulier (normal) | fichier.txt |
| d | Dossier (directory) | /home/user/ |
| l | Lien symbolique | raccourci -> /etc/passwd |
| c | Périphérique caractère (e.g. terminal) | /dev/tty |
| b | Périphérique bloc (e.g. disque dur) | /dev/sda |
| p | Pipe nommé (FIFO) | /tmp/ma_fifo |
| s | Socket | /var/run/docker.sock |
Changer les droits
chmod
Concaténer des fichiers
cat file1.txt file2.txt file3.txt
affiche le contenu de file1.txt, file2.txt et file3.txt sur la sortie standard.
La commande
cat file1.txt file2.txt file3.txt > combinedfile.txt
redirige la sortie standard et l'écrit dans le fichier combinedfile.txt. Autrement, on a effectué la concaténation des trois fichiers.
Rechercher
Find
On cherche des fichiers avec leur nom.
find oùchercher -maxdepth 2 -name 'nomdufichieroupattern'
find ~/teaching -name 'td*.pdf'
grep (Globally search a Regular Expression and Print)
grep "patternToSearchForInsideFiles" filenameOrPatternOfFileName
grep "Python" notes.txt
- Chercher récursivement dans les sous-dossiers :
grep -r "abricot" * - Ignorer la casse :
grep -i "abricot" panierdefruits.txt - Compter le nombre d'abricots :
grep -c "abricot" panierdefruits.txt - Obtenir les lignes qui ne contiennent pas un pattern :
grep -v "abricot" panierdefruits.txt - Chercher exactement les lignes :
grep -x "abricot" panierdefruits.txt
Exemples
Modifier la brillance de l'écran
Voici un programme qui cherche le fichier brightness, puis tente d'écrire 3 à l'intérieur.
$ sudo find -L /sys/class/backlight -maxdepth 2 -name '*brightness*'
/sys/class/backlight/intel_backlight/brightness
$ cd /sys/class/backlight/intel_backlight/
$ echo 3 > brightness
Ca ne fonctionne pas pour des raisons de droit.
$ sudo echo 3 > brightness
Le problème est que sudo ne donne des droits que sur des programmes et > est exécuté par le shell. Pour déléguer la redirection (l'ouverture du fichier brightness) au root, on peut utiliser le programme tee.
$ echo 3 > sudo tee brightness
Racourcis clavier
| Pour faire.... | Faire |
|---|---|
| Aller au début de ligne | Ctrl + A |
| Aller à la fin de ligne | Ctrl + E |
| Supprimer tout ce qu'il y a après le curseur | Ctrl + K |
| Pour coller ce qu'il y avait | Ctrl + Y |
| Pour enlever la commande courante | Ctrl + C |
| Rechercher une commande qu'on a écrite il y a longtemps | Ctrl + R |
Références
- https://missing.csail.mit.edu/2020/course-shell/
- https://www.geeksforgeeks.org/linux-unix/
Initiation à Git
Git est un gestionnaire de versions. Il permet de sauvegarder différentes versions d'un code. Git est beaucoup plus puissant que ce que l'on va voir là. Commençons par simple.
⌛ Git permet d'avoir des branches pour gérer plusieurs versions d'un logiciel en parallèle, par exemple pour ajouter des nouvelles fonctionnalités. On verra ça plus tard.
Pourquoi ?
Eviter un enfer de fichiers
On peut éviter de se mélanger les pinceaux 🖌🖌🖌 dans les versions de fichier :
🖹 programme.c
🖹 programme (v2).c
🖹 programme (v3).c
🖹 programme (v3 essai avec DFS).c
🖹 programme (v3 essai avec BFS).c
A plusieurs, on éviter de s'envoyer des mails et de se tromper dans la version du fichier, ou de modifier à la main des parties d'un fichier. On veut éviter de devoir manuellement intégrer des modifications de différentes personnes.
🖹 programme.c
🖹 programme (v2).c
🖹 programme (v3 par Patrick).c
🖹 programme (v3 par Julia).c
🖹 dijkstra.c
🖹 dijkstra (v2 par Julia).c
🖹 dijkstra (v3 correction mineure par Jenny).c
🖹 dijkstra (v3 par Julia).c
🖹 dijkstra (v3 par Julia) Copie de sécurité.c
Travailler de manière isolé
Vous travaillez à plusieurs, mais tu es en train d'ajouter une fonctionalité, et tu ne veux pas perturber le travail des autres.
Pour cela, git offre un mécanisme de branches. ⌛ On verra ces notions un autre jour !
Aspects sociaux
- Le projet peut être rendu visible pour d'autres personnes qui peuvent rejoindre le projet.
- On peut reporter des bugs et des propositions de nouvelles idées sur la plate-forme commune sans devoir s'envoyer des mails.
Aspects historiques
On peut faire de l'archéologie logicielle.
- Quelle était la raison de cette ligne de code ? Qui l'a écrit ? Quand ?
- Sur quelle partie du logiciel a travaillé Patrick ?
- Depuis quand les tests unitaires sur
dijkstrane fonctionne plus ?
Pourquoi un outil décentralisé ?
L'outil git est décentralisé. C'est bien car on peut travailler dans le train, quand il n'y a pas de réseau. On peut faire des commits (c'est-à-dire estampiller des modifications) sans connexion Internet.
Serveur distant
Ici, on utilisera https://gitlab.aliens-lyon.fr/. C'est là-bas que sera vos dépôts (appelé projets dans gitlab). Un dépôt est un ensemble de code source avec tout son historique de versions.
Créer une clé
Le plus simple pour se connecter à un dépôt (et éviter de taper un mot de passe toutes les 5 secondes et demi) est d'utiliser une clé SSH. Pour en créer, tapez cette commande :
ssh-keygen -t rsa -b 4096
Elle génère deux fichiers :
- une clef privée
id_rsa(ne jamais donner/montrer ce fichier !) - une clef publique
id_rsa.pub
Dans github, gitlab, copier la clef publique (attention, pas la clef privée !). Dans gitlab Aliens c'est ici : https://gitlab.aliens-lyon.fr/-/user_settings/ssh_keys.
Créer un dépôt
Depuis https://gitlab.aliens-lyon.fr/projects/new, vous pouvez créer un dépôt.
Récupérer le contenu sur votre ordinateur
La récupération d'un dépôt distant sur votre ordi s'appelle clone. Dans la page web de votre projet (i.e. dépôt), copier l'URL :
Si vous avez une clef SSH, votre vie est plus simple : pas besoin de taper un mot de passe à chaque fois. Avec HTTPS, il faudra taper un mot de passe à chaque commande.
Sur votre ordinateur dans le dossier de votre choix, taper :
git clone [url]
Exemple :
git clone git@github.com:tableaunoir/tableaunoir.git
Créer un dépôt local
On peut aussi créer un dépôt entièrement en local. Pour créer un dépôt vide depuis rien du tout et connecté à rien du tout sur Internet :
git init <nomduprojet>
Exemple :
git init superlogiciel
Mon premier commit
La vie d'un logiciel est une pièce de théâtre où les fichiers sont des acteurs. Un commit est une estampille, des données "tamponnées", prise en photos de certains fichiers du projet. Souvent ça correspond à une étape dans la création d'un logiciel :
- génération d'un labyrinthe
- déplacement de la balle implémentée
- correction du bug de déplacement du vaisseau

Fichiers non versionnés, jamais
Les fichiers d'un dossier ne sont pas tous versionnés, i.e. incorporés à un commit ! Par exemple, il est hors de question de versionner des fichiers temporaires ou des fichiers exécutables :
🖹 infos.log
🖹 fichiertemporaire.aux
🖹 monprogramme.exe
Eux ne participent jamais à la pièce de théâtre. Ils sont untracked.
Au contraire, il faut versionner les fichiers sources par exemple :
🖹 balle.c
🖹 vaisseau.h
🖹 vaisseau.c
Pour dire que des fichiers doivent être maintenus et versionné au prochain commit, on les ajoute à la scène (et du même coup au projet) :
git add <fichier>
Exemple :
git add *.tex
git add dijkstra.c
Pour commiter (estampiller / prendre en photos) les fichiers explicitement ajoutés, i.e. les fichiers sur scène :
git commit -m "message"
Pour commiter les fichiers modifiés qui ont déjà été versionné un jour :
git commit -am "message"
Là on prend carrément en photo tous les acteurs de la pièce de théâtre.
Définitions.
- untracked signifie que les fichiers ne sont pas versionnés du tout. Ce ne sont même pas des acteurs de la pièce de théâtre.
- staging area/tracked/index (mis en scène) parle des fichiers qui vont être versionnés quand on fait un commit. Ce sont les acteurs sur scène.
- not staged parle des fichiers qui sont a priori versionnés mais dont on a pas explicitement dit qu'ils allaient être versionnés au prochain commit. Ce sont les acteurs de la pièce, mais ils ne sont pas sur scène en ce moment.
Suppression et renommage de fichiers
Pour renommer un fichier :
git mv [nom-fichier-courant] [nouveau-nom]
Pour supprimer un fichier :
git rm [fichier]
Pour supprimer un fichier du dépôt mais pas du système de fichier (i.e. un fichier du projet arrête de l'être. Un acteur est viré !) :
git rm --cached [fichier]
Gérer le serveur distant
Pour télécharger les données du serveur vers mon ordinateur :
git pull
Pour poster nos modifications sur le serveur :
git push
Obtenir des informations sur le dépôt
Lister les nouveaux fichiers et à commiter :
git status
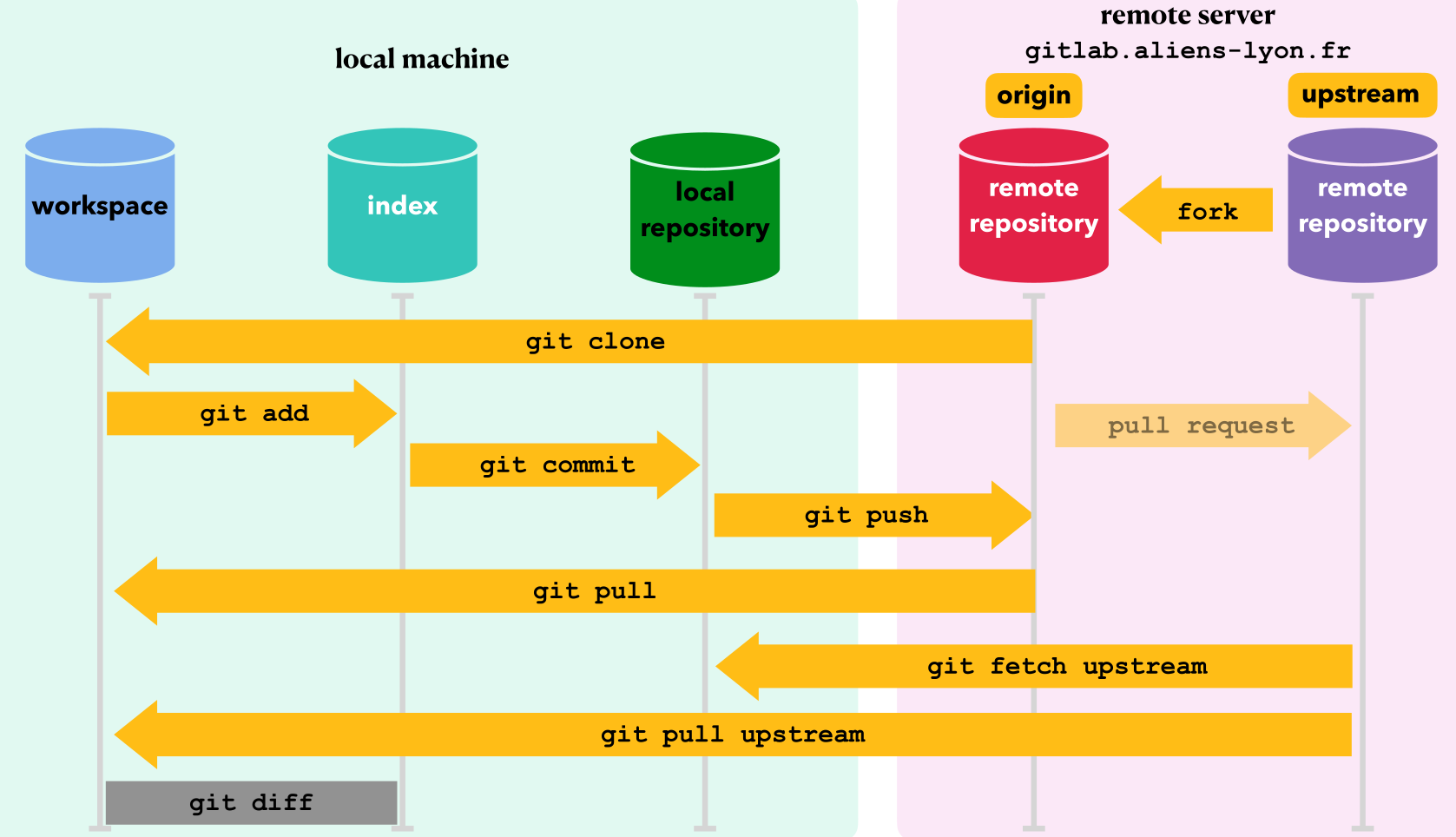
Idée générale
Commandes principales
| Pour faire ça | Il faut taper ça |
|---|---|
| Pour récupérer du code du serveur XXXX | git clone XXXXX |
Pour dire que le fichier dijkstra.c doit être versionné | git add dijkstra.c |
| Pour estampiller mes fichiers | git commit -a -m "algorithme Dijkstra" |
| Pour mettre mes modifications sur le serveur | git push |
| Pour récupérer les modifications des autres depuis le serveur | git pull |
Quiz
- Quelle est la différence entre upstream et origin ?
- Quelles est la différence entre workspace, index et local repository ?
- A-t-on besoin d'une connexion Internet pour faire un
git commit?
Tableaux
Un tableau consiste en des cases contigus dans la mémoire.
int A[4];
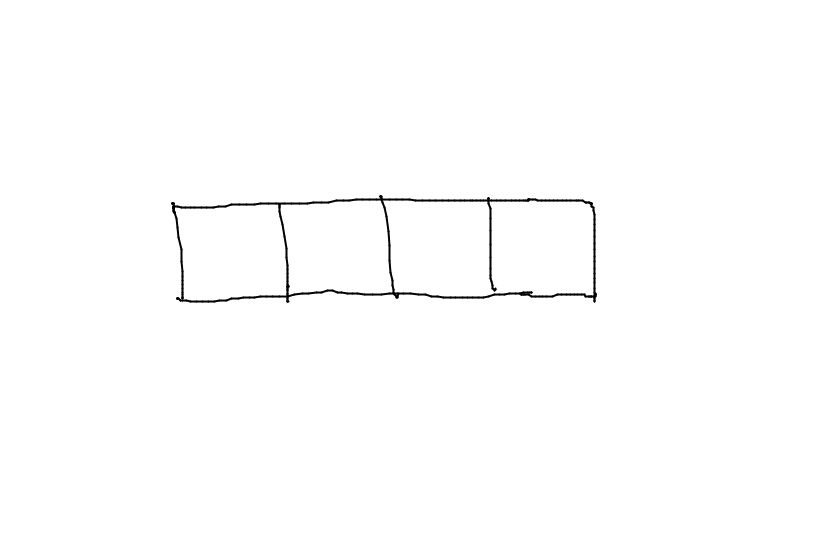
On peut initialiser un tableau directement comme ça :
int A[4] = {1, 2, 3, 5};
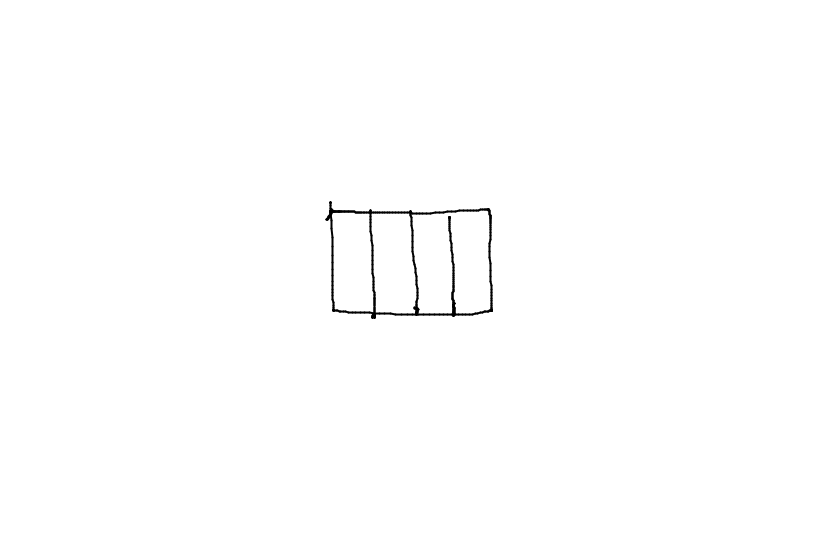
C'est le type qui détermine le nombre d'octets d'une case mémoire :
char A[4];
Ils peuvent être multidimensionels.
int A[4][3];
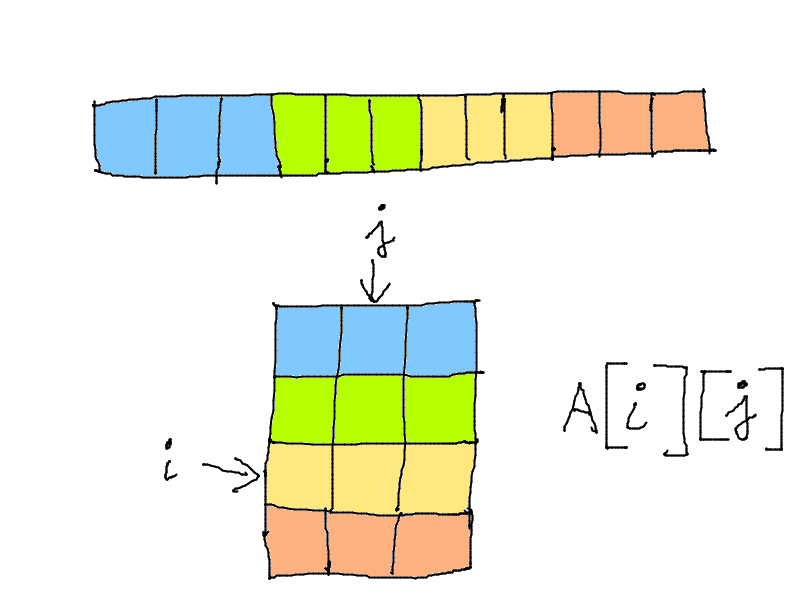
Tableau de taille non connue à la compilation
Depuis C99, on peut définir des tableaux de taille non connue à l'avance, à la compilation.
void f(int n) {
int A[n+5];
...
}
Attention cependant, cette fonctionnalité n'est pas autorisée en C++. La raison : une incompatibilité avec les templates car A[1], A[2], A[3], A[4], etc. sont tous des types différents.
Tableaux globaux
Les tableaux globaux doivent avoir une taille fixée à la compilation. Ils sont stockés dans le segment de données.
Tableaux locaux à une fonction
Ils sont stockés dans la pile (et pas dans le tas).
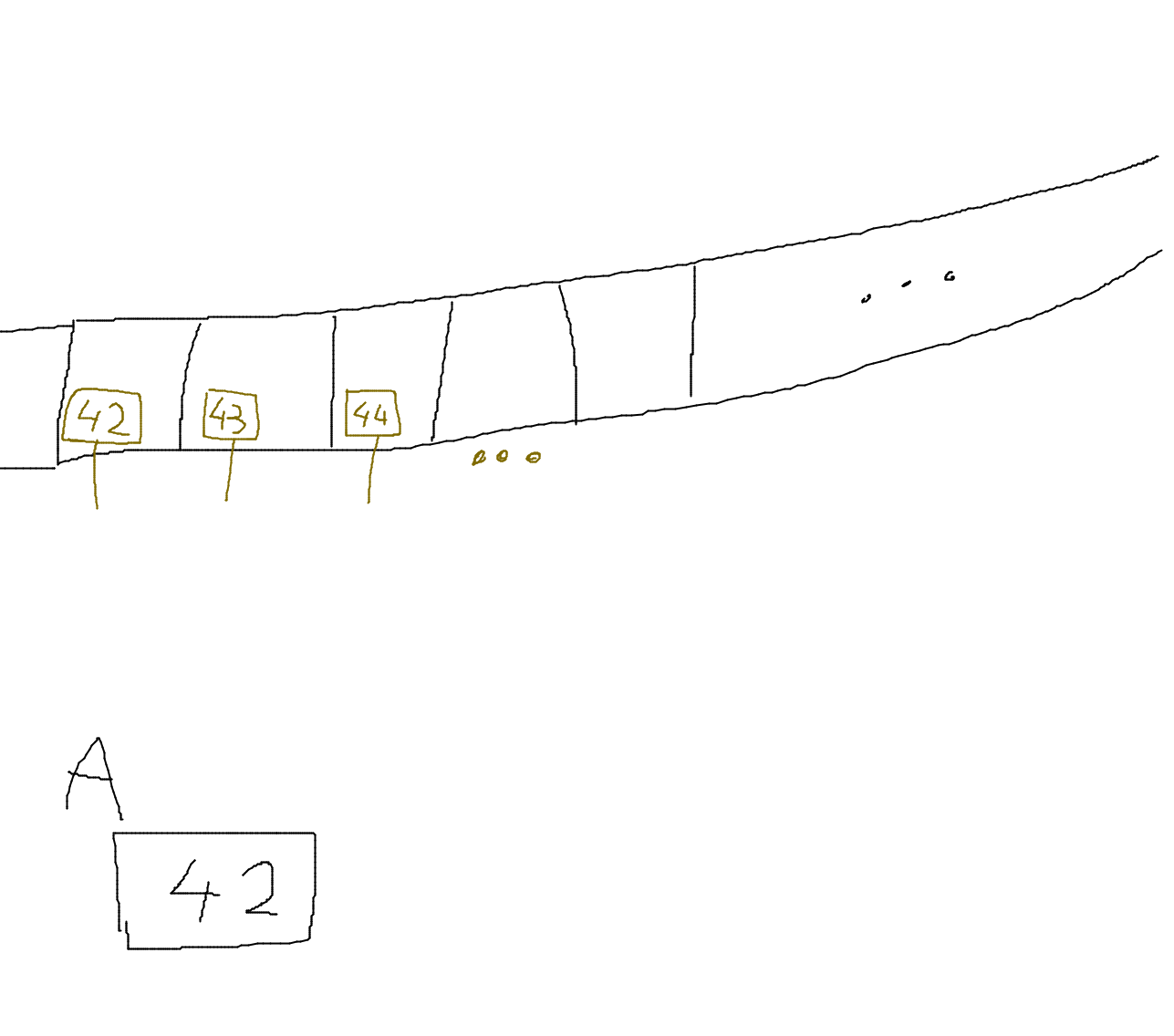
Tableau 1D en paramètre
Quand on passe un tableau en paramètres, on donne un pointeur, c'est-à-dire l'adresse mémoire du tableau. Autrement dit, quand on empile le paramètre, on empile juste son adresse, et pas touuuuuuuuuuut le tableau.
void f(char A[300000]) {
...
}
En particulier, si on fait :
void f(char A[300000]) {
printf("%d\n", sizeof(A));
}
Ca imprime 8 et pas 300000.
Ces trois signatures sont équivalentes :
void f(char p[3]);
void f(char p[]);
void f(char* p);
Tableau 2D en paramètre
On peut passer un tableau 2D en paramètre.
void f(char p[4][3])
Par contre, ce n'est pas équivalent à
void f(char p[])
void f(char* p)
Forcément, vu que l'on a pas l'information sur la taille.
On ne peut pas non plus écrire :
void f(char p[][])
car la machine ne sait pas comment interpréter le tableau 2D.
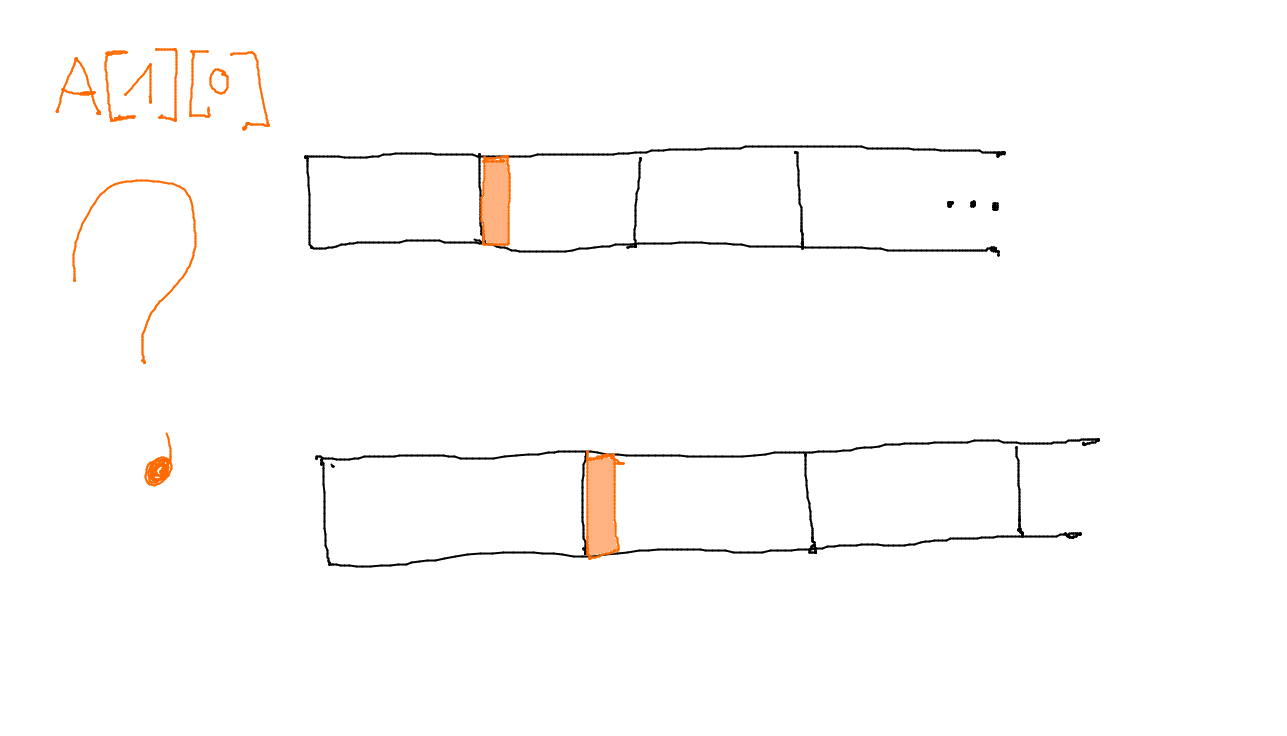
Par contre, on peut omettre la taille selon la première coordonnée et écrire :
void f(char p[][3])
En effet, on a l'information suffisante dans le corps de la fonction pour savoir comment utiliser p, même si on ne connaît la borne pour le premier indice. Mais c'est à l'humain de faire attention.
Impossible de renvoyer un tableau
int[] createArrayButNotPossible()
{
int A[3] = {1, 2, 5};
return A;
}
Le code suivant compile... mais renvoie une adresse vers une zone mémoire qui n'est plus allouée :
int* createArrayButNotPossible()
{
int A[3] = {1, 2, 5};
return A;
}
Aller plus loin
-
For 2D arrays: see here
-
Peut-on allouer un tableau dynamiquement dans le tas qui est multidimensionel ?
Struct
Un struct permet de regrouper plusieurs informations dans un bloc. Par exemple, un point sur l'écran regroupe deux informations : l'abscisse et l'ordonnée.
struct Point
{
int x;
int y;
};
Initialisation
Nouveauté ;) C99 ! On peut initialiser en une ligne un struct :
struct Point point = {2, 1};
ou alors en nommant les champs :
struct Point point = {.x = 2, .y = 1};
On peut aussi assigner un struct plus tard mais il faut caster (i.e. mentionner le type entre parenthèses) :
point = (struct Point) {.x = 2, .y = 1};
Accès aux champs
On accède aux champs avec un point (!). Par exemple pour l'abcisse de notre point point on écrit :
point.x
Et pour récupérer son ordonnée :
point.y
Accès aux champs d'un struct pointé
Quand on a un pointeur p vers un struct Point, on a un raccourci d'écriture :
(*p).x
s'écrit
p->x
C'est plus lisible.
Enum
Un enum est un type avec un domaine fini, dont les éléments sont listés. Par exemple, un jour de la semaine est parmi lundi, mardi, mercredi, jeudi, vendredi, samedi ou dimanche :
enum weekday {Mon, Tue, Wed, Thur, Fri, Sat, Sun};
On déclare une variable comme ça, par exemple disant que mon jour favori est le dimanche :
enum weekday favoriteDay = Sun;
Voici un autre exemple de type enum pour les couleurs des cartes :
enum cardsuit {CLUBS, HEARTS, SPADES, DIAMONDS};
Union
Un type union permet de lire/écrire dans la même portion mémoire mais avec des champs différents. Considérons :
union mask
{
unsigned char n[4];
unsigned long fulldata;
};
En déclarant
union mask m = {.fulldata = 1025};
on a une variable m sur 4 octets dont les bits sont :
00000000 00000000 00000010 00000001
Avec m.fulldata, on lit 00000000 00000000 00000010 00000001 en entier que l'on interprète comme 1025, alors que m.n[i] permet de lire chaque octets.
- Que vaut
m.n[0]?On lit 00000000, donc il vaut 0.
Que vaut m.n[1] ?
00000000, donc il vaut 0.
Que vaut m.n[2] ?
00000010, donc il vaut 2.
Que vaut m.n[3] ?
00000001, donc il vaut 1.
Donner un nom à un type
Le mot-clé typedef permet de donner un nom personalisé à un type existant.
typedef struct Point
{
int x;
int y;
} tPoint;
Ainsi, au lieu de faire struct Point p;, on peut écrire tout simplement tPoint p;.
typedef unsigned int distance;
distance d = 3;
Bref, l'utilisation de typedef est :

Champs de bits
Alors là, c'est très bas niveau. Dans l'exemple qui suit, on a un point où l'abcisse est codé sur 4 bits, l'ordonnée sur 3 bits, auquel on ajoute 1 bit pour savoir si le point est sélectionné ou non.
typedef struct Point
{
int x: 4;
int y: 3;
int selected: 1;
} point_t;
A priori, vous pouvez oublier les champs de bits ; on ne va pas les utiliser je pense.
Exemples plus compliqués
Vendeur.se de livres, mugs et Tshirt, vous tenez une base de données des objets dans votre magasin. Voici un enum pour le type d'objets (un livre, un mug ou un T-shirt) :
enum itemType {Book, Mug, Shirt};
On pourrait définit un struct pour stocker le prix, le type d'objets puis les informations de l'objet :
#define TITLE_LEN 30
#define AUTHOR_LEN 20
#define DESIGN_LEN 20
struct item_crazy
{
double price;
enum itemType type;
char booktitle[TITLE_LEN + 1];
int book_num_pages;
char design[DESIGN_LEN + 1];
int shirt_color;
int shirt_size;
};
Mais c'est dommage car il y aura toujours des champs que l'on utilisera pas. Par exemple, pour un livre, on utilisera booktitle et book_num_pages, mais pas design, shirt_color, shirt_size.
La solution est d'utiliser un union pour réutiliser la même portion de mémoire :
struct item
{
double price;
enum itemType type;
union
{
struct
{
char title[TITLE_LEN + 1];
int num_pages;
} book;
struct
{
char design[DESIGN_LEN + 1];
} mug;
struct
{
char design[DESIGN_LEN + 1];
int color;
int size;
} shirt;
} item;
};
Pour l'initialisation, on peut faire comme ça (merci le C99) :
struct Item item = {.price = 10.0, .type = Shirt, .item = {.shirt = {.design = "miaou", .color = 0, .size = 2}}};
ou alors affecter chaque champ séparemment :
item.price = 10.0;
item.type = Shirt;
strcpy(item.item.shirt.design, "miaou");
item.item.shirt.color = 0;
item.item.shirt.size = 2;
Switch case
switch case est une construction de conditionnelle sur la valeur d'une expression, ici item.type. On peut donc effectuer différentes actions selon le type d'objet à promouvoir.
switch (item.type)
{
case Book:
printf("The book %s is available!\n", item.item.book.title);
break;
case Shirt:
printf("Shirt with %s of size %d available!\n", item.item.shirt.design, item.item.shirt.size);
break;
case Mug:
printf("Mug with %s available!\n", item.item.mug.design);
break;
default:
exit(-1);
}
Pourquoi mettre des break ?
switch(i) {
case 0: case 1: dothejob(); break();
case 2: doanotherthing(); break();
default: doDefault();
}
Pour aller plus loin : Rust
Rust est un langage beaucoup plus sûr. On peut y définir directement des enum qui sont aggrémentés des données. On fait ensuite du pattern matching pour effectuer la bonne action selon le type de l'objet.
enum Item { Book(f64, String, i64), Mug(f64, String), Shirt(f64, String, i32, i32) } fn main() { let item = Item::Shirt(10.0, "miaou".to_string(), 0, 2); match item { Item::Book(price, title, nb_pages) => &println!("The book {} is available!", title), Item::Mug(price, design) => &println!("Mug with {} available!", design), Item::Shirt(price, design, color, size) => &println!("Shirt with {} of size {} available!", design, size), }; }
En tout cas, le C contrairement au Rust montre mieux comment les objets sont représentés en mémoire. C'est tout l'intérêt pédagogique du C, même si c'est lourdingue à programmer...
Bibliothèque raylib
raylib est une bibliothèque pour dessiner et plus généralement développer des jeux vidéos en C. Elle offre des fonctions pour dessiner des rectangles, des cercles, des lignes, etc.
Installation
- cloner le dépôt (or
git clone --depth 1 https://github.com/raysan5/raylib.git raylib) - lire
https://github.com/raysan5/raylib/wiki/Working-on-GNU-Linux - aller dans
raylib/src - installer les librairies qu'utilisent raylib :
- exécuter
sudo apt install libx11-dev libxcursor-dev libxrandr-dev libxinerama-dev libxi-dev libgl-dev
- exécuter
- exécuter
make PLATFORM=PLATFORM_DESKTOP. Un fichier.aa été généré. Il s'agit d'une librairie statique (statique dans le sens où elle contient du code qui va être ajouté à vos exécutables qui utilisentraylib). - Faire
sudo make install. Cela va copier la librairie statique.adans le bon dossier oùgccva chercher les librairies (généralement/usr/local)
Ecrire un programme qui utilise raylib
Ecrire un fichier main.c contenant :
#include <stdio.h>
#include <raylib.h>
int main()
{
InitWindow(640, 480, "Test membership of a point in a polygon");
SetTargetFPS(20);
while (!WindowShouldClose())
{
BeginDrawing();
EndDrawing();
}
CloseWindow();
return 0;
}
Puis compiler votre fichier main.c avec gcc main.c -lraylib -lGL -lm -lpthread -ldl -lrt -lX11.
Les -l permettent de renseigner des librairies externes à utiliser.
Point dans un polygone
Nous allons programmer un petit projet qui teste si un point est dans un polygone. Ici, on appelle projet un ensemble de fichiers sources et header qui vont servir à produire un exécutable.
Voir Wikipedia
- Entrée : A un tableau de n points du plan décrivant un polygone simple, et p un point du plan
- Sortie : oui si p est à l'intérieur du polygone décrit par A
Nous allons implémenter l'algorithme 112 de Shimrat.
Compilation
En gros, la compilation est le processus qui prend un ou plusieurs fichiers sources et produit un exécutable. En fait, comme on le verra, c'est une synecdoque particularisante (figure de style où on parle du tout en utilisant un terme pour une partie seulement). Pour éviter cette figure de style malheureuse, on peut parler de génération d'un exécutable (build en anglais).
Préprocessing
En C, les mots-clés commençant par un # correspondent à un traitement de préprocessing. Par exemple #define X 32 remplace les occurrences de X par 32.
#define X 32
int main() {
int a = X + 2;
int b = X;
}
devient
int main() {
int a = 32 + 2;
int b = 32;
}int x
La ligne #include "bloup.h" insère le contenu du fichier bloup.h :
#include "bloup.h"
int main() {
bloup_create();
bloup_inform(3);
}
devient
void bloup_create();
void bloup_inform(int x);
void bloup_extract(int x, int y);
void bloup_free();
int main() {
bloup_create();
bloup_inform(3);
}
Pour n'exécuter QUE le préprocesseur, il faut utiliser l'option -E :
gcc -E main.c -o mainresultat.c
Compiler le projet en un coup
Voici une commande pour construire un exécutable :
gcc myotherCfile.c main.c -o main -Wall

où le flag -o veut dire output.
- Quel défaut y-a-t-il de compiler tout ?
Compiler un projet fichier par fichier
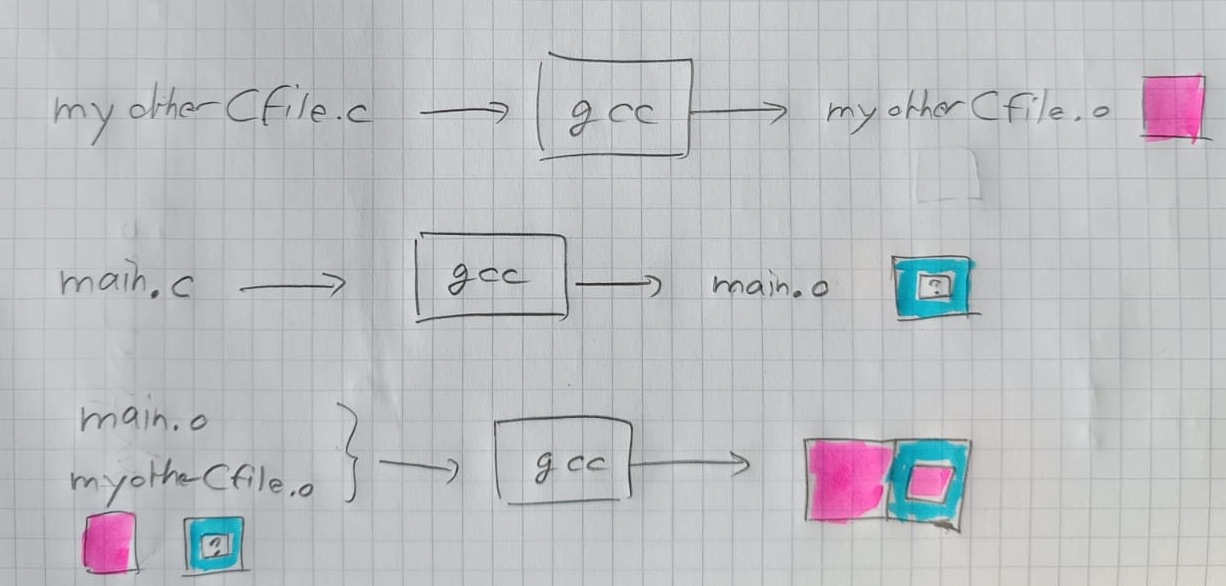
En fait, on peut compiler chaque fichier source séparemment puis tout lier à la fin :
gcc -c -o myotherCfile.o myotherCfile.c
gcc -c -o main.o main.c
gcc -o main main.o myotherCfile.o
où le flag -c signifie que l'on ne fait compiler mais pas lier.
Comme le montre l'image ci-dessous :
- la compilation consiste à transformer un fichier source .c en fichier objet (du code machine) .o mais en laissant des "trous" pour les fonctions qui sont définis dans d'autres modules.
- la liaison vient remplir les trous avec le code machine manquant.
Chaîne de compilation
C Source Code
|
v
+----------------+
| Preprocessor |
+----------------+
|
v
+----------------+
| Compiler |
+----------------+
|
v
+----------------+
| Linker |
+----------------+
|
v
Executable
Makefile
Pourquoi a-t-on besoin d'un outil pour compiler automatiquement ?
Make est un outil créé en 1976
Compiler avec Makefile ( version naïve)
- Créer un fichier
Makefile. - Y écrire :
all:
gcc myotherCfile.c main.c -o main -Wall
Dans le terminal, on tape make pour construire le projet. Le nom all s'appelle une cible.
Attention, la ligne d'après contient un tab (et pas 4 espaces !) suivi de la commande à exécuter pour construire le projet.
Compiler intelligente avec Makefile
Avec un Makefile, on peut avoir plusieurs cible.
all: main
main: main.o myotherCfile.o
gcc -o main main.o myotherCfile.o
main.o: main.c
gcc -c -o main.o main.c
myotherCfile.o: myotherCfile.c
gcc -c -o myotherCfile.o myotherCfile.c
clean:
rm *.o main
Compilation et liaison
La cible main a besoin d'avoir déjà effectué le travail pour les cibles main.o et myotherCfile.o, et consiste à effectuer gcc -o main main.o myotherCfile.o.
-
Où est-ce qu'a lieu la liaison dans le Makefile ci-dessus ?
Dans la cible main. -
Qu'est ce que fait
gcc -c -o main.o main.c?
main.c en main.o en laissant des trous pour les fonctions déclarées mais non définies.
Variables dans un MakeFile
On peut définir des constantes dans un MakeFile. Par exemple, on définit la constante CC qui donne le nom du compilateur.
Pour avoir le contenu de la constante on écrit $(CC). Ecrire CC ça écrit juste CC ; nous on veut le contenu.
CC=gcc
all: main
main: main.o myotherCfile.o
$(CC) -o main main.o myotherCfile.o
main.o: main.c
$(CC) -c -o main.o main.c
myotherCfile.o: myotherCfile.c
$(CC) -c -o myotherCfile.o myotherCfile.c
clean:
rm *.o main
Pattern
Voici trois règles qui ont le même pattern :
myotherCfile.o: myotherCfile.c
$(CC) -c -o myotherCfile.o myotherCfile.c
bloup.o: bloup.c
$(CC) -c -o bloup.o bloup.c
miaou.o: miaou.c
$(CC) -c -o miaou.o miaou.c
Au lieu de cela, on peut écrire :
%.o: %.c
$(CC) -c -o $@ $^
- Le
%signifienimportequelnomdefichier. $@= le nom de la règlenimportequelnomdefichier.o$^= la prémisse, icinimportequelnomdefichier.c
| nom de la règle: | prémisse |
|---|---|
$@ | $^ |
Lister les fichiers
La commande principale pourrait être :
main: main.o myotherCfile.o bloup.o miaou.o
$(CC) -o main main.o myotherCfile.o bloup.o miaou.o
Pour réaliser cela, on a besoin de lister les .o. Or, on ne les connait pas encore. Mais on sait qu'il y a en un par fichier source .c. On peut lister les fichiers sources avec la commande wildcard :
SOURCES=$(wildcard *.c)
La fonction wildcard prend un argument qui est une expression régulière de fichiers et elle produit la liste des fichiers qui correspondent à l'expression régulière. Le terme wildcard signifie, dans un jeu de cartes, une carte qui remplace n'importe quel autre (typiquement le joker). En informatique, cela désigne ici tous les fichiers qui matchent avec *.c. Dans l'exemple, la constante SOURCES vaut main.c myotherCfile.c bloup.c miaou.c.
Pour obtenir la liste des .o correspondantes, on fait une substitution :
main.c myotherCfile.c bloup.c miaou.c
🡇
main.o myotherCfile.o bloup.o miaou.o
Pour cela on écrit :
OBJECTS=$(SOURCES:.c=.o)
Et maintenant, la règle principale qui était :
main: main.o myotherCfile.o bloup.o miaou.o
$(CC) -o main main.o myotherCfile.o bloup.o miaou.o
devient
main: $(OBJECTS)
$(CC) -o main $^
Organisation en dossiers
Le must est d'organiser son projet avec différents dossiers :
- un dossier
headerqui contient les fichiers header - un dossier
srcqui contient les fichiers .c - un (futur) dossier
buildqui contient les fichier .o créés à la compilation
Ainsi voici un exemple de fichier Makefile qui gère ça :
CC=gcc
SOURCES=$(wildcard src/*.c)
OBJECTS=$(patsubst src/%.c,build/%.o,$(SOURCES))
main.exe: $(OBJECTS)
$(CC) $^ -lraylib -lGL -lm -lpthread -ldl -lrt -lX11 -o main.exe
build/%.o: src/%.c build
$(CC) -Iheader -c -o $@ $<
build:
mkdir build
.PHONY:clean run
clean:
-rm -r build
-rm ./main.exe
run: main.exe
./main.exe
La fonction patsubst permet de réaliser une substitution d'un pattern. Ici :
src/main.c src/myotherCfile.c src/bloup.c src/miaou.c
🡇
build/main.o build/myotherCfile.o build/bloup.o build/miaou.o
Le flag -Iheader indique qu'il faut cherche dans le dossier header pour les #include (-I).
Le symbole $< correspond à la première partie d'une prémisse. Ici : src/%.c build on prend src/%.c (par exemple src/main.c).
La directive .PHONY permet de dire qu'une règle ne correspond pas à un fichier. La directive clean par exemple devrait s'exécuter même si un fichier clean existe ! Ca n'a rien à voir !
Le tiret - avant rm permet d'ignorer l'erreur si le répertoire build n'existe pas, ou si l'exécutable n'existe pas.
Aller plus loin
On peut faire des boucles et autres en Makefile... bref...
Créer une documentation à partir des commentaires
doxygen est un outil pour générer de la documentation à partir de sources C, C++, Python etc. correctement commentés.
Installation de doxygen
L'outil est disponible dans les paquets Linux traditionnels :
sudo dnf install doxygen
Bien commenter
Au début de chaque fichier, il faut quelque chose comme :
/**
* \file main.c
* \brief Programme de tests.
* \author Franck.H
* \version 0.1
* \date 11 septembre 2007
*
* Programme de test pour l'objet de gestion des chaines de caractères Str_t.
*
*/
Pour les fonctions, on commente comme ça :
/**
* \fn static Str_t * str_new (const char * sz)
* \brief Fonction de création d'une nouvelle instance d'un objet Str_t.
*
* \param sz Chaine à stocker dans l'objet Str_t, ne peut être NULL.
* \return Instance nouvellement allouée d'un objet de type Str_t ou NULL.
*/
Utilisation de doxygen
Dans le répertoire d'un projet, on lance doxygen -g pour créer un fichier doxyfile qui est le fichier de configuration de la documentation.
On lance alors doxygen pour générer la documentation.
Histoire des pointeurs
ALGOL
ALGOL-60 n'avait pas de pointeurs explicites mais avait passage par valeurs VS passage par références VS passage par nom.
En ALGOL-60, par défaut = par référence
procedure Swap(x, y);
integer x, y;
begin integer t;
t := x;
x := y;
y := t;
end
i = 1;
A[1] := 3;
A[2] := 2;
A[3] := 5;
Swap(i, A[i]);
- Par référence, A =
1 2 5etivaut 3.
Le passage par référence est disponible en Pascal avec var :
procedure Swap(var A, B: Integer);
var
Temp: Integer;
begin
Temp := A;
A := B;
B := Temp;
end;
Le passage par référence n'existe pas en C (on utilise des pointeurs), mais existe en C++ avec des références.
Par valeur
procedure Swap(x, y);
value x, y;
integer x, y;
begin integer t;
t := x;
x := y;
y := t;
end
i = 1;
A[1] := 3;
A[2] := 2;
A[3] := 5;
Swap(i, A[i]);
- Par valeur, rien ne change : A =
3 2 5etivaut 1.
En C, tout est passé par valeur.
Par nom
procedure Swap(x, y);
name x, y;
integer x, y;
begin integer t;
t := x;
x := y;
y := t;
end
i = 1;
A[1] := 3;
A[2] := 2;
A[3] := 5;
Swap(i, A[i]);
- Par nom, A =
1 2 1etivaut 3.
Le passage par nom est une catastrophe... Il a été abandonné dans d'autres langages.
https://www.cs.csustan.edu/~mmartin/teaching/CS4100S11/lectures/Algol_Part4.pdf </!-->
Premiers languages avec pointeurs

Kateryna L. Yushchenko (URSS) est créditée comme la créatrice des pointeurs en 1955 quand elle a conçu Address Programming Language (Адресна мова програмування). On trouve peu d'informations sur ce langage.
 Harold Lawson (USA) est crédité comme créateur des pointeurs en 1964 pour le langage PL/I (Programming Language One).
Un exemple de code ici : https://www.ibm.com/docs/en/zos/2.4.0?topic=services-pli-example-building-linked-list. On y déclarait un pointeur
Harold Lawson (USA) est crédité comme créateur des pointeurs en 1964 pour le langage PL/I (Programming Language One).
Un exemple de code ici : https://www.ibm.com/docs/en/zos/2.4.0?topic=services-pli-example-building-linked-list. On y déclarait un pointeur P comme suit :
DCL P POINTER;
Cf. https://www.ibm.com/docs/en/zos/3.1.0?topic=services-ceegtstget-heap-storage l'allocation mémoire fonctionne comme suit :
CALL CEEGTST ( HEAPID, NBYTES, ADDRSS, FC );
où CEEGTST est le nom du service pour allouer de la mémoire sur un tas. Il y a plusieurs tas : on donne l'ID du tas où on veut allouer dans HEADID. Le paramètre NBYTES indique le nombre d'octets. Le paramètre ADDRSS est modifié avec l'adresse vers la zone allouée. FC reçoit lui le feedback code (est-ce que l'allocation a réussi ? etc.).
Pointeur nul : erreur à 1 000 000 000$
C. A. R. Hoare a dit en 2009 :
I call it my billion-dollar mistake. It was the invention of the null reference in 1965. At that time, I was designing the first comprehensive type system for references in an object oriented language (ALGOL W). My goal was to ensure that all use of references should be absolutely safe, with checking performed automatically by the compiler. But I couldn't resist the temptation to put in a null reference, simply because it was so easy to implement. This has led to innumerable errors, vulnerabilities, and system crashes, which have probably caused a billion dollars of pain and damage in the last forty years.
- Blog à lire : https://lucid.co/techblog/2015/08/31/the-worst-mistake-of-computer-science
- Exposé : https://www.infoq.com/presentations/Null-References-The-Billion-Dollar-Mistake-Tony-Hoare/
Pointeurs
Motivation
Effets de bord
struct human {
int x;
int y;
int souffle;
};
void deplacerDroite(struct human a) {
a.x++;
a.souffle++;
}
struct human player;
void game_loop() {
...
if(isKeyRight())
deplacerDroite(player);
...
}
Que pensez-vous du programme ci-dessus ?
player n'est pas modifée quand on appuie sur la flèche de droite. Le contenu de player est copié quand on appelle deplacerDroite donc seul l'argument a, qui est une copie de player est modifié.
Structures de données
Pour l'instant, on connaît toujours la taille des valeurs de retour des fonctions, la taille des données manipulée. Donc sans pointeur :
- pas de tableau dynamique de taille variable
- pas d'arbres binaires de recherche
- pas de table de hachage
Solution : un pointeur
Un pointeur est une variable contenant une adresse mémoire.
void deplacerDroite(struct human *a) {
(*a).x++;
(*a).souffle++;
}
deplacerDroite(&player);
| Adresse | Données |
|---|---|
adresse | *adresse |
&data | data |
On a déjà vu cette solution pour les tableaux car on ne pouvait de toute façon pas faire autrement. Un tableau se dégrade en pointeur quand il est passé en argument :
void fillArray(int A[10]) {
...
}
est la même chose que
void fillArray(int A[]) {
...
}
qui est la même chose que
void fillArray(int *A) {
...
}
Exercice métaphorique
-
Si
xest une maison, qu'est ce que&x?L'adresse postale de x -
Si
xest un livre dans une bibliothèque, qu'est ce que&x?Sa côte qui donne sa localisation (pièce, étagère, etc.) -
Si
xest une page dans un livre, qu'est ce que&x?Le numéro de la page. -
Si
xest une variable déclaré parint x;, qu'est ce que&x?L'adresse mémoire où on trouve l'entier x.
-
Si
aest une adresse postale, qu'est ce que*a?La maison, le garage, l'hôpital, l'ENS, etc. qui se trouve à l'adresse a -
Si
aest la côte d'un livre dans une bibliothèque, qu'est ce que*a?Le livre en question dont la côte est a -
Si
aest une numéro de page d'un livre, qu'est ce que*a?Le contenu de la page numéro a -
Si
aest un pointeur sur un entier, déclaré parint *a;, qu'est ce que*a?*adésigne l'entier que l'on peut lire à l'adresse mémoirea.
Déclaration
Déclarer un entier
int a;
a est une variable contenant un entier.

Déclarer un pointeur sur un entier
int *p;
p est une variable contenant une adresse mémoire, à partir de laquelle on interprète le contenu comme un entier noté *p.
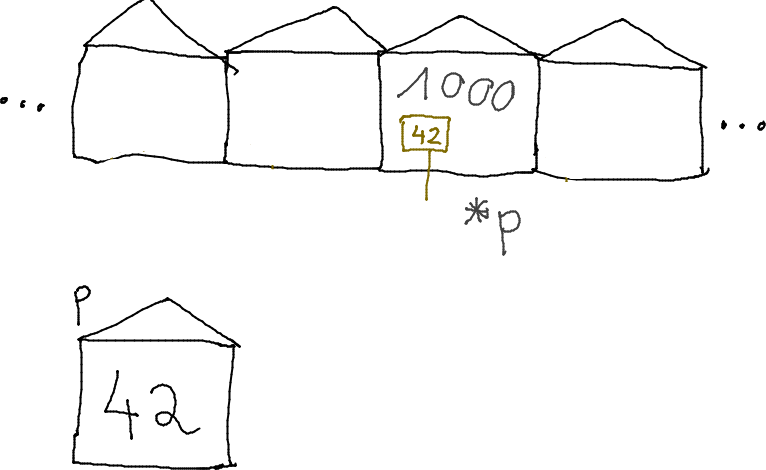
Combien de bits prend p en mémoire ?
Combien d'octets prend p en mémoire ?
Exercices
int x = 42;
int y;
y = x;
y++;
Que vaut x ? y = x réalise une affectation de la valeur de x dans y. C'est une copie. A la fin, y vaut 43 mais x vaut toujours 42.
int x = 42;
int *y;
y = &x;
(*y)++;
Que vaut x ? y = &x réalise une affectation de l'adresse de x dans y. A la fin, *y, qui n'est autre que x vaut 43. Bref, x vaut 43.
Placement de l'étoile
On peut écrire
int* p;
et
int *p;
Malheureusement, il vaut mieux écrire attacher l'étoile au nom de la variable. Par exemple :
int *p, i; // OUI
ou de manière équivalente
int* p, i; // NON car on pourrait croire que p et i sont de même type
déclare p comme un pointeur sur un int alors i est vraiment un int. Mieux encore, évitez les déclarations sur une seule ligne et écrivez :
int *p; // TRES CLAIR
int i; // TRES CLAIR
Typage
Toutes les variables suivantes sont des pointeurs :
int *p1;
float *p2;
struct point *p3;
...
Quelles est la taille de p1 ? de p2, de p3 ?
Il y aussi le type générique
void*
qui veut dire pointeur sur n'importe quoi.
void *p;
Cela veut dire pointeur vers n'importe quoi, et c'est à nous de savoir ce qu'il y a derrière. Le type void nous empêche d'interpréter les données pointées. Pour cela, on introduit une nouvelle variable :
void f(void *p)
{
int* pInt = p;
/*
j'utilise ici pInt qui est un pointeur sur un entier
*/
}
ou alors on caste :
void f(void *p)
{
int x = *((int*) p) + 1;
/*
j'utilise ici pInt qui est un pointeur sur un entier
*/
}
Scoop, quel est la taille d'un void* ?
Pointeur nul
Il y a une valeur particulière NULL (qui vaut 0). Elle signifie que le pointeur pointe sur rien. Le comportement normal d'un pointeur est implicitement d'un type optionel :
- soit il n'y a pas de données (et on pointe vers
NULL) - soit on pointe vers une donnée
Supposons que p est le pointeur nul, combien d'octets faut-il pour stocker p ?
Pointeurs (suite)
Vous pouvez vous amusez à allouer et déallouer de la mémoire et jouer avec des pointeurs ici : https://github.com/francoisschwarzentruber/memory
Rappel de l'organisation de la mémoire
- Qu'est ce qu'il y a dans la zone des données ?
- Qu'est ce qu'il y a dans la pile ?
Allocation mémoire
On peut allouer des octets sur le tas avec la fonction malloc. C'est un peu comme si on achetait de la mémoire. On indique le nombre d'octets, par exemple 4 :
malloc(4);
malloc(4) renvoie :
- soit un pointeur vers la zone allouée de 4 octets (i.e. l'adresse mémoire du début de la zone allouée)
- soit
NULLen cas d'échec
int* p = malloc(4);
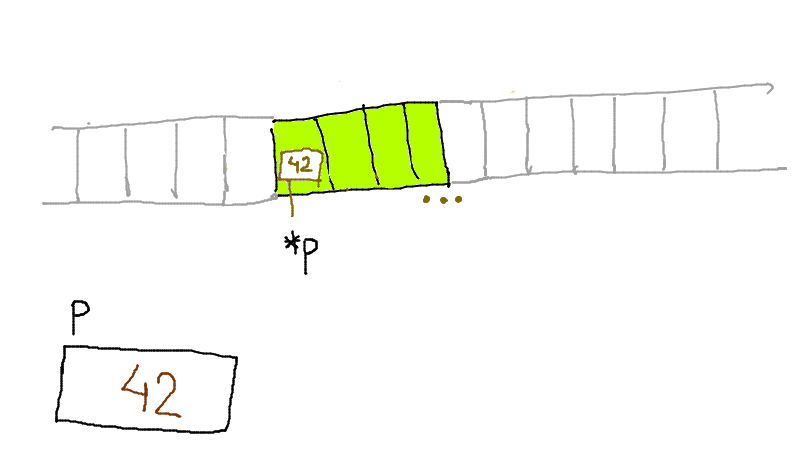
- Que contient
*p?
- Où est stocker
*pavec le malloc ci-dessus ?
Dans le tas.
- Que contient
p?
- Où est stocker
pavec le malloc ci-dessus ?
Dans la pile. On peut imaginer :
int main()
{
int* p = malloc(4);
...
}
p est une variable locale comme les autres, sauf qu'elle contient une adresse mémoire.
Amélioration de l'appel
En fait on écrit plutôt
int* p = malloc(sizeof(int));
Encore mieux :
int *p = malloc(sizeof(*p));
- Pourquoi est-ce mieux ?
Car si on change le type de p par exemple :
struct point *p = malloc(sizeof(*p));
ça fonctionne toujours bien !
Accès à la valeur pointée
int* p = malloc(sizeof(*p));
print("%d\n", *p);
- Que pensez-vous du programme suivant ?
int* p = malloc(4);
print("%d\n", *p);
Ca fonctionne, même si c'est maladroit de laisser un 4 volant comme ça.
- Que pensez-vous du programme suivant ?
int* p;
print("%d\n", *p);
C'est le mal. L'adresse mémoire p vaut une valeur non connue. On va donc lire *p alors que la zone mémoire n'a pas été allouée. D'abord, tu achètes, ensuite tu utilises.
- Que pensez-vous du programme suivant ?
int* p = 1452;
print("%d\n", *p);
- Que pensez-vous du programme suivant ?
int* p = malloc(3);
print("%d\n", *p);
Outre qu'il ne faut pas écrire 3 comme ça, ça ne va pas. On achète 3 octets mais il en faut 4. Là, le dernier octet n'a pas été acheté.
- Que pensez-vous du programme suivant ?
int* p = malloc(10);
print("%d\n", *p);
Outre qu'il ne faut pas écrire 10 comme ça, ça fonctionne. On peut lire les 4 premiers octets et l'interpréter comme un entier *p.
Pour les struct
On écrit p->x au lieu de (*p).x.
Bonne utilisation de malloc
En fait, malloc peut échouer s'il n'y a plus assez de mémoire. Dans ce cas, malloc renvoie NULL. Il faut faire :
int *p;
if(p = malloc(sizeof(int)))
{
printf("Out of memory!\n");
exit(EXIT_FAILURE);
}
Vous pouvez par exemple écrire :
void* xmalloc(size_t nbytes) {
void* p = malloc(nbytes);
if(!p)
{
printf("Out of memory!\n");
exit(EXIT_FAILURE);
}
return p;
}
Bon, c'est un peu brutal pour un utilisateurrice. Il peut le vivre comme ça :
void* xmalloc(size_t nbytes) {
void* p = malloc(nbytes);
if(!p)
{
printf("Pas de mémoire. Et j'ai codé rapidement mon programme. Donc tu perds toutes tes données, dommage pour toi. Relance le programme et refais tout ce que tu as fait ! Bonne chance !\n");
exit(EXIT_FAILURE);
}
return p;
}
On peut imaginer des solutions plus agréables pour l'utilisateur. On débute une action... mais une erreur mémoire ne quitte pas le programme. On annule juste le début de l'action et on revient à l'état d'avant.
Désallocation avec free
free(p);
Désalloue la mémoire allouée par malloc (ou ses copines realloc, calloc, aligned_alloc). C'est comme vendre de la mémoire car on n'en a plus besoin. Par exemple :
int *p = malloc(sizeof(*p));
*p = 5;
free(p);
- Que pensez-vous du programme suivant ?
int *p = malloc(sizeof(*p));
*p = 5;
free(p);
free(p);
- Que pensez-vous du programme suivant ?
int *p = 4321;
free(p);
Ne vends pas quelque chose qui n'est pas à toi. (de toute façon, int *p = 4321 c'est le mal).
- Que pensez-vous du programme suivant ?
void f() {
int *p = xmalloc(sizeof(*p));
}
Un appel à f achète 4 octets, mais c'est une zone mémoire à laquelle on ne pourra plus accéder.
- Que pensez-vous du programme suivant ?
int* f() {
return xmalloc(sizeof(int));
}
Un appel à f achète 4 octets puis renvoie le pointeur vers ces 4 octets. Pas de soucis car on garde l'accès à ces 4 octets. Attention, à ne pas oublier de libérer la mémoire plus tard !
Applications : liste chaînée
- Ecrire les opérations pour le type abstrait d'une pile
- Implémenter la pile avec une liste chaînée
Applications directes
- Implémenter une pile avec une liste chaînée
- Implémenter le parcours de Graham pour calculer l'enveloppe convexe d'un ensemble de points du plan
- Etudier l'algorithme
- Utiliser l'implémentation de la pile
- Utiliser pointeur sur une fonction pour trier les points
Pointeurs et tableaux
Un pointeur peut être utilisé comme un tableau
Le programme suivant alloue sur le tas 3 cases contenant chacune un entier.
int* p = malloc(3*sizeof(*p));
p[0] = 1
p[1] = 3
p[2] = 35
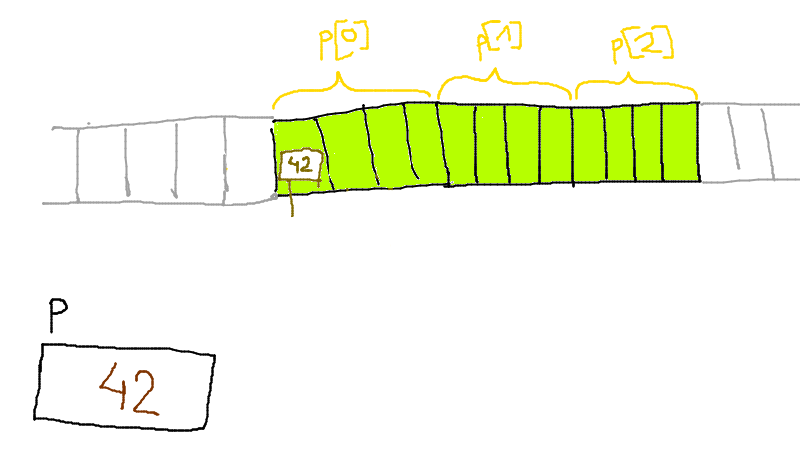
p[0] et *p sont synonymes.
- Que pensez-vous de ce programme ?
int* p = malloc(3*sizeof(*p));
p[0] = 1
p[1] = 3
p[2] = 35
p[10] = 5
malloc c'est acheter une zone mémoire. Là, avec p[10] = 5, on écrit là où on a pas acheté.
- Qu'est ce qui est moche dans
int* p = malloc(3*sizeof(*p));?
Le fait d'avoir 3 qui est volant. Si c'est une constante, on peut faire par exemple :
#define NB_POTATOES 3
int* p = malloc(NB_POTATOES*sizeof(*p));
Un tableau est quasiment comme un pointeur
Un tableau statique ou un tableau déclaré dans une fonction est considéré comme un tableau : il a une taille et sizeof(tableau) renvoie le nombre d'octets utilisés pour stocker tout le tableau.
Mais si on passe un tableau à une fonction, ça devient un pointeur. Les signatures suivantes sont équivalentes :
void f(char* p)
void f(char p[])
void f(char p[3])
Dans f, sizeof(p) renvoie 8 octets (64 bits).
Exercice : tableau dynamique
realloc permet de réallouer une zone mémoire. Voir TD.
Arithmétique des pointeurs
Addition d'un pointeur et d'un entier
Considérons le pointeur p tableau de 3 int :
avec
p++;
on avance de 1 case int dans le tableau (i.e. de 4 octets dans la plage mémoire) :
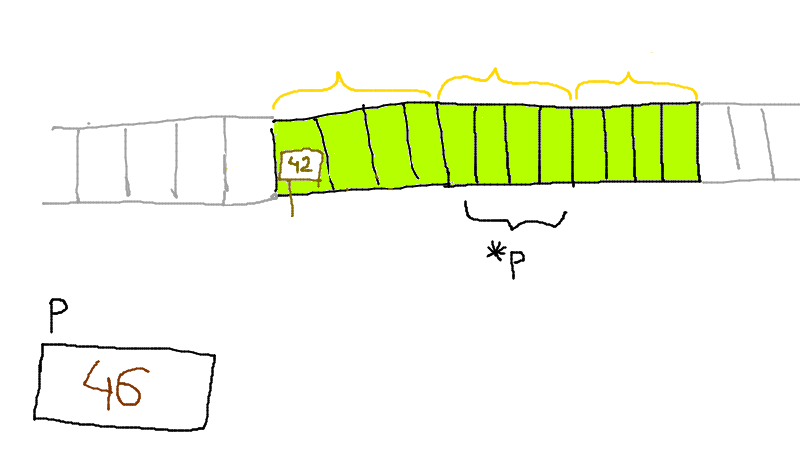
De la même manière, on peut faire p += 5 et on avance de 5 cases du tableau (5 fois 4 octets).
Différence de pointeurs
int* p;
int* q;
...
int nbCasesTableauEntrePetQ = q - p;
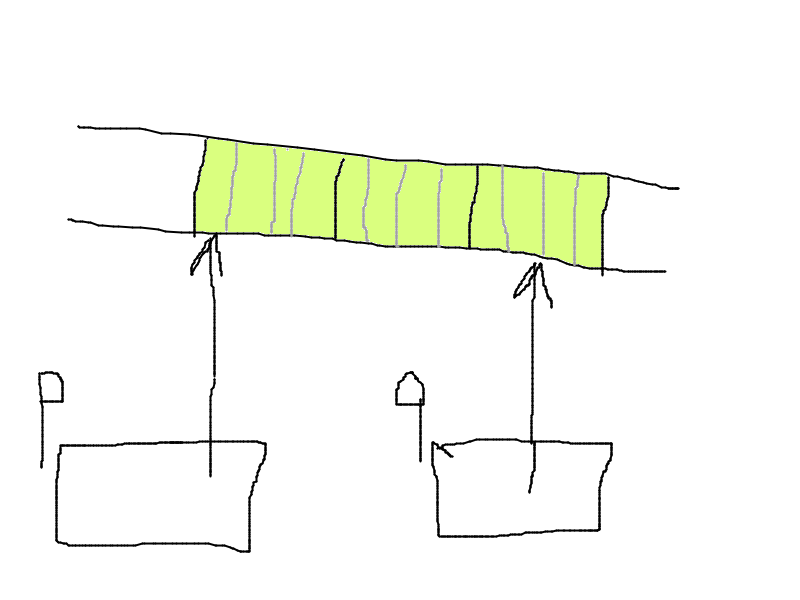
Sur le dessin, q - p vaut int)
La différence de pointeurs est un nombre relatif.
Dans l'exemple p - q vaut
Marrant !
int a[3] = {0, 1, 42};
Que vaut a[2] ?
Que vaut 2 [a] ?
En fait a[i] est une macro pour *(a+i).
Pointeurs vers un tableau 2D
Prenons l'exemple d'un tableau 2D d'entiers. Une façon de faire est de considérer un pointeur de pointeurs vers des entiers :
int **p;
Exercice à faire en TD
- Implémenter une fonction qui alloue un tableau 2D de taille n x n.
Un tableau 1D énorme qui simule un tableau 2D
typedef char* array2d_t;
array2d_t array2d_create(size_t sizeX, size_t sizeY) {
char *array = malloc(SIZEX * SIZEY * sizeof(char));
return array;
}
void array2d_free(array2d_t A) {
free(A);
}
char array2d_get(array2d_t A, size_t x, size_t y) {
return A[x*SIZEY + y];
}
void array2d_free(array2d_t A) {
free(A);
}
Un tableau 1D de pointeurs vers des tableaux 1D
typedef char** array2d_t;
array2d_t array2d_create(size_t sizeX, size_t sizeY) {
char **array = malloc(SIZEX * sizeof(char *));
for (int i = 0; i < SIZEX; i++)
array[i] = malloc(SIZEY * sizeof(char *));
return array;
}
void array2d_free(array2d_t A) {
for (int i = 0; i < SIZEX; i++)
free(array[i]);
free(A);
}
/*
array2d_t A = array2d_create(64, 32);
... on utilise A[x][y]...
array2d_free(A);
*/
Un tableau 1D de pointeurs vers des endroits dans un seul tableau 1D
typedef char** array2d_t;
array2d_t array2d_create(size_t sizeX, size_t sizeY) {
char **array = malloc(SIZEX * sizeof(char *));
array[0] = malloc(SIZEX*SIZEY);
for (int i = 1; i < SIZEX; i++)
array[i] = array[0] + (SIZEY * i);
return array;
}
void array2d_free(array2d_t A) {
free(A[0]);
free(A);
}
/*
array2d_t A = array2d_create(64, 32);
... on utilise A[x][y]...
array2d_free(A);
*/
Mot clé Const
En C, le mot clé const s'applique sur ce qu'il y a à sa gauche. Il veut dire "je suis une constante".
Pointeur vers un (ou des) caractères en lecture seule
char const * pointer1 = malloc(1);
*pointer1 = 'a'; //non car le char est une constante
pointer1 = malloc(1); //yes
Par convention, on met souvent le mot-clé const tout à gauche :
const char * pointer1 = malloc(1);
*pointer1 = 'a'; //no
pointer1 = malloc(1); //yes
const char* p = malloc(4);
p[0] = 'a'; // no
p[1] = 'a'; // no
p = malloc(4); // yes

Pointeur en lecture seule sur des caractères
Dans l'exemple suivant, le "je suis une constante" s'applique sur l'étoile, autrement dit sur le pointeur.
char* const q = malloc(4);
q[0] = 'a'; //yes
q = NULL; // non car on ne peut pas modifier le pointeur

Pointeur en lecture seule sur des caractères en lecture seule
const char* const r = malloc(4);
r[0] = 'a'; //no
r = NULL; //no

Réallocation
void * realloc( void * pointer, size_t memorySize );
Calloc
void* calloc( size_t num, size_t size );
int* A = calloc(NB_PATATES, sizeof int);
## Exercices
- Implémenter un tableau dynamique
Pointeurs et fonctions
Mettre des fonctions dans des variables
On peut déclarer une variable f de type int(*)(void), c'est-à-dire une fonction qui ne prend rien et renvoie un entier :
int myFunction(){ return 42; }
int (*f)(void); // là on déclare un pointeur sur une fonction qui prend pas d'argument et renvoie un entier
f = &myFunction; // mais en fait le & est optionnel car de tte façon, ça ne veut rien dire d'autres
x = (*f)() // appel de la fonction
Pourquoi parle-t-on de pointeurs sur une fonction ?
f = &myFunction;
La segment text contient le programme lui-même. Cette zone est en lecture seule. Mais on peut pointer dessus. &myFunction est une adresse vers une case de cette zone.

Passer des fonctions en paramètre
Du coup, on peut passer des fonctions en paramètre, par exemple pour renseigner comment trier un tableau d'entiers :
#include <stdlib.h>
int cmp(const void *pA, const void *pB)
{
/**
* ici on fait comme si c'était des entiers à trier
**/
int* intpA = pA;
int* intpB = pB;
int a = *intpA;
int b = *intpB;
return a - b;
/**
< 0 si "a < b"
= 0 si "a = b"
> 0 si "a > b"
*/
}
qsort(tableau, nbElementsTableau, nbOctetsElement, cmp)
Types pour les fonctions
Déclarer une variable
Voici le type d'une fonction :
int
(*)
(const void*, const void*)
En C, les types donnent une position pour mettre la variable déclarée. Vous avez toujours vu TYPE NOMVARIABLE;. Là on met la variable sur le partie verte :
int
(*f)
(const void*, const void*);
Définir un type
typedef
int
(*ComparisonFunction)
(const void*, const void*);
Et après on peut déclarer une variable f qui contient une fonction dont la signature est donnée par le type ComparisonFunction :
ComparisonFunction f;
ou
int cmp(const int *pA, const int *pB)
{
return *pA - *pB;
}
qsort(tableau, nbElementsTableau, nbOctetsElement, (ComparisonFunction) cmp)
Débugueur gdb
Le débugueur gdb (pour GNU Debugger) permet d'arrêter le programme (points d'arrêt) et d'inspecter des variables, la pile d'appel etc.
Mise en place
L'utilisation de gdb se fait sur l'exécutable directement. Mais il faut donc que l'exécutable contienne des données supplémentaires pour permettre le débogage. Pour cela on utilise le flag -g par exemple
gcc -Wall -g programme.c -o programme
Avec -g, l'exécutable contient des informations de débogage (liens entre code machine et numéro de lignes dans le code source) pour que gdb puisse nous raconter des choses :
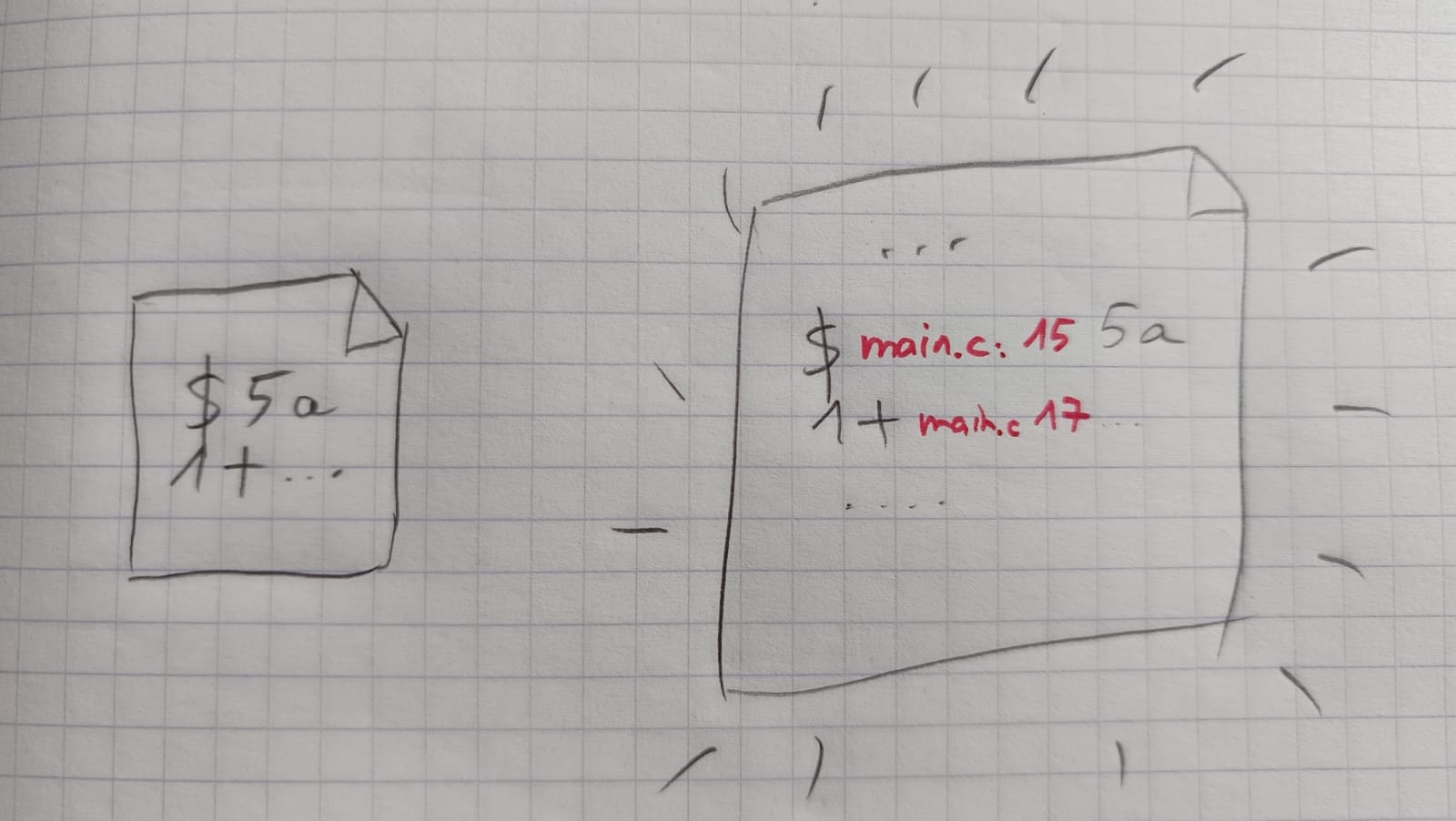
Utilisation de gdb
On lance le programme en mode débogage en faisant
gdb programme
On a alors un invite de commande pour réaliser le débogage. On peut toujours quitter le débogueur en tapant quit.
Points d'arrêt
Un point d'arrêt est un endroit du programme où le débogueur doit arrêter l'exécution.
Commandes
| Commandes | Raccourcis | Effets et exemples |
|---|---|---|
quit | q | on quitte le débogueur |
breakpoint 15 | b 15 | met un point d'arrêt à la ligne 15 |
breakpoint bloup.c:15 | b bloup.c:15 | met un point d'arrêt à la ligne 15 du fichier bloup.c |
breakpoint dfs | b dfs | met un point d'arrête au début de la fonction dfs |
watch x | w x | on s'arrête à chaque fois que la variable x change |
print x | p x | on affiche la valeur de la variable x |
list | l | on affiche l'endroit dans le code où on est |
step | s | on fait un pas dans l'exécution du programme |
next | n | on fait un pas mais en considérant un appel de fonction au niveau courant comme atomique |
continue | c | on continue l'exécution jusqu'au prochain point d'arrêt |
backtrace | bt | On affiche la pile d'exécution (la pile d'appels) |
clear 15 | enlève le point d'arrêt à la ligne 15 | |
clear dfs | enlève le point d'arrête au début de la fonction dfs | |
delete | supprime tous les points d'arrêt | |
delete 2 | supprime le deuxième point d'arrêt / watchpoint |
Débugueur Valgrind
Fuite mémoire

Parfois, des cellules mémoire ne sont plus accessibles. Par exemple, si on appelle la fonction f suivante :
int f() {
char* p = malloc(3);
}
cela allouera 3 cases mémoires qui ne seront pas libérées.
Lecture de zones non allouées

Si on essaie d'accéder à une zone non allouée, on obtient généralement un Segmentation fault (core dumped) comme avec :
void main() {
int* p = NULL;
printf("%d\n", *p);
}
Avec valgrind, on peut savoir où est l'erreur.
Utilisation
gcc -g main.c
valgrind ./a.out
valgrind -v --leak-check=summary ./a.out
Chaînes de caractères en C
Se termine par \0
"chouette"
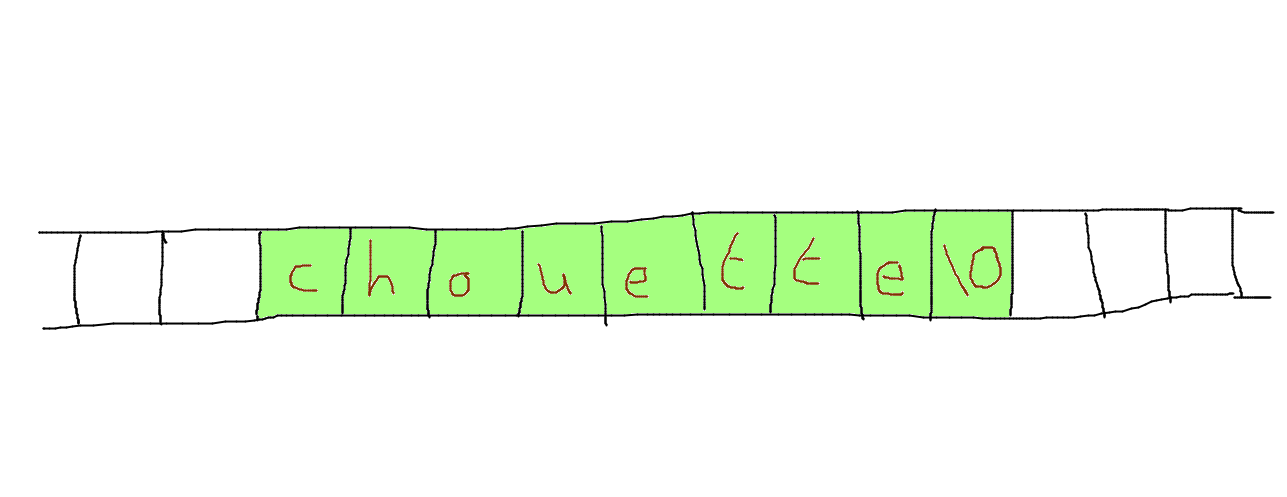
Chaîne de caractères = pointeur sur char
On peut initialiser
char* s = "chouette";
En mémoire, s est un pointeur, une adresse mémoire, vers une zone de la mémoire avec 9 octets alloués où on a :
QCM
-
Que pensez-vous de
char[3] s = "abc";?Il manque une case pour '\0'. -
Que pensez-vous de
char[10] s = "abc";?Pas de soucis, le compilateur complète avec des \0. -
Que pensez-vous de
char s[] = "abc";?Pas de soucis, le compilateur comprend qu'il faut allouer 4 octets, et d'ailleurs il n'alloue que 4 octets. -
Comment accéder à la i-ème lettre ?
a[i]. -
Que pensez-vous du programme suivant ?
char s[] = "abca";
s[2] = 'b';
- Que pensez-vous du programme suivant ?
char* s = "abca";
s[2] = 'b';
- Est-ce que ce programme est correct bien que le tableau ne finissent pas par
\0?
char A[3];
A[0] = 'a';
A[1] = 'a';
A[2] = 'a';
<string.h> qui gèrent les chaînes de caractères ! En effet, A[3] (qui sort de la zone allouée) n'est peut-être pas \0 et donc les fonctions vont continuer à lire des parties de la mémoire indéterminée jusqu'à trouver un \0.
- Est-ce que ce programme est correct ?
char* A = malloc(2);
A[0] = 'a';
A[1] = 'a';
A[2] = 'a';
A[2] n'est pas alloué.
- Est-ce que ce programme est correct ?
char* A = malloc(3);
A[0] = 'a';
A[1] = 'a';
A[2] = 'a';
char* A = malloc(4);
A[0] = 'a';
A[1] = 'a';
A[2] = 'a';
A[3] = `\0`;
\0.
char* A = malloc(10);
A[0] = 'a';
A[1] = 'a';
A[2] = 'a';
A[3] = `\0`;
\0. Il y a des cases non utilisées mais ce n'est pas grave.
Le C c'est vraiment du bas niveau !
Considérons deux chaînes de caractères
char s[10], t[10];
-
Peut-on écrire
s = "abc";?Non, car les tableaux ne sont pas assignables. -
Peut-on écrire
t = s;?Pareil, non. -
Peut-on initialiser
char u[10] = "abc";?Oui, à l'initialisation c'est bon. C'est équivalent à char u[10] = {'a', 'b', 'c', '\0'}; -
Peut-on tester
s == t?Oui, on peut toujours tester l'égalité d'adresse mémoire de tableaux ou de pointeurs :). -
Que teste
s == t?Que l'adresse mémoire sest égale à l'adresse mémoiret. -
Que pensez-vous du programme suivant ?
char* donnerSalutation() {
char s[50] = "Bonjour";
return s;
}
- Que pensez-vous du programme suivant ?
char* donnerSalutation() {
char* s = "Bonjour";
return s;
}
- Que pensez-vous du programme suivant ?
char* donnerSalutation() {
char* s = malloc(10*sizeof *s);
s[0] = 'h';
s[1] = 'i';
s[2] = '!';
s[3] = '\0';
return s;
}
Longueur d'une chaîne de caractères
size_t strlen(const char *s);
- Ecrire soi-même une fonction
int len(char* s)qui renvoie la longueur de la chaînes.
Parcours d'une chaîne de caractères
- Ecrire une fonction qui teste d'appartenance d'un caractère à une chaîne.
- Ecrire une fonction qui transforme une chaîne de caractères en sa version en minuscule.
Considérons :
char* s = "Bonjour tout le monde";
-
Que vaut
strlen(s)?21 car il y a 21 caractères dans "Bonjour tout le monde". -
Que vaut
sizeof(s)?8 car il faut 8 octets pour stocker une adresse mémoire.
Considérons :
char[] s = "Bonjour tout le monde";
-
Que vaut
strlen(s)?21 car il y a 21 caractères dans "Bonjour tout le monde". -
Que vaut
sizeof(s)?22 car il faut 22 octets pour mettre la chaîne de caractères "Bonjour tout le monde"de 21 caractères, puis\0.
Comparaison de chaînes
int strcmp(const char *s1, const char *s2)
strcmp("abricot", "chat") | strcmp("chat", "chat") | strcmp("chat", "abricot") |
|---|---|---|
< 0 | 0 | > 0 |
Copie de chaînes
strdup
char * strdup( const char * source);
Cette fonction renvoie une copie de la chaîne de caractères source :
- Elle alloue une nouvelle zone mémoire avec un
malloc(caché dans l'appelstrdup) de la même taille quesource - En cas de succès, elle copie
sourcevers cette nouvelle zone mémoire et renvoie un pointeur vers cette zone - En cas d'échec (hé oui, le
mallocpeut échouer), elle renvoie un pointeur nul.
⚠ Attention à libérer la mémoire avec free de la copie créée.
strcpy
strcpy copie src dans dst que l'on a déjà alloué préalablement. Attention, si ce n'est pas alloué suffisamment :  .
.
char * strcpy(char * restrict dest, const char * restrict source);
strncpy fait la même chose mais dans la limite de len caractères.
size_t strncpy(char * restrict dst, const char restrict * src, size_t len);
size_t strlcpy(char * restrict dst, const char * restrict src, size_t dsze);
memcpy etc.
void * memcpy ( void * destination, const void * source, size_t nbOctetsACopier );
La même chose mais pour de la mémoire et pas de vérification de caractère nul ou autre. C'est fait pour copier n'importe quoi.
Concaténer deux chaînes
strcat de <string.h>
char * strcat(char* restrict dst, const char * restrict src);
Précondition :
- il faut que
dstsoit suffisamment alloué pour contenir le contenu de la concaténation. Sinon.
Effet :
- place
srcà la fin dedst
char[1000] s = "";
strcat(s, "Bienvenue ");
strcat(s, "à ");
strcat(s, "l'ENS de Lyon");
strcat renvoie :
dst! C'est pour pouvoir faire des cascades d'appel
On peut donc chaîner les appels à strcat comme cela :
char[1000] s = "";
strcat(strcat(strcat(s, "Bienvenue "), "à "), "l'ENS de Lyon");
Variante efficace
Malheureusement, la complexité de strcat est en (O(|s1| + |s2|)).
cf https://www.joelonsoftware.com/2001/12/11/back-to-basics/
On souffre du problème de Shlemiel le peintre.
- Ecrire une version
mystrcatqui fait la même chose questrcatmais renvoie un pointeur sur la fin de la chaîne.
char* mystrcat( char* dst, char* src )
{
while (*dst) dst++;
while (*dst++ = *src++);
return --dst;
}
Variante à la Python
- En utilisant
memcpy, écrire une variantestring_concatqui renvoie une nouvelle chaîne de caractères qui est la concaténation des1ets2.
La signature de memcpy est
void * memcpy( void * restrict dst, const void * restrict src, size_t nbBytesToCopy );
/*
return a new string that is the concatenation of s1 and s2
(in Python, s1 + s2)
**/
char * string_concat(char* s1, char* s2) {
int l1 = strlen(s1);
int l2 = strlen(s2);
char* result = malloc(l1 + l2 + 1);
if(result == NULL)
return NULL;
memcpy(result, s1, l1);
memcpy(result + l1, s2, l2+1);
return result;
}
Variante avec réallocation
- Ecrire une fonction qui prend une chaîne
s1et qui lui concatènes2. Si pas assez de mémoire, on réalloues1. La fonction renvoie la nouvelle chaîne. Dans tous les cas, la chaînes1initiale est perdue.
char* strcatrealloc(char* s1, char* s2) {
int l1 = strlen(s1);
int l2 = strlen(s2);
char* result = realloc(s1, l1 + l2 + 1 * sizeof(*result));
if(result == NULL)
return NULL;
memcpy(result + l1, s2, l2 + 1);
return result;
}
Tableaux de chaînes de caractères
- Dessiner un schéma mémoire de
#define NB_MAXCHAR 12
char planets[][NB_MAXCHAR] = {"Mercury", "Venus", "Earth",
"Mars", "Jupiter", "Saturn",
"Uranus", "Neptune", "Pluto"};
- Même chose pour
char *planets[] = {"Mercury", "Venus", "Earth",
"Mars", "Jupiter", "Saturn",
"Uranus", "Neptune", "Pluto"};
- Même chose pour
#define NB_PLANETS 9
char ** planets = malloc(NB_PLANETS*sizeof(*planets));
planets[0] = "Mercury";
planets[1] = "Venus";
planets[2] = "Earth";
planets[3] = "Mars";
planets[4] = "Jupiter";
planets[5] = "Saturn";
planets[6] = "Uranus";
planets[7] = "Neptune";
planets[8] = "Pluto";
Arguments en ligne de commande
int main(int argc, char *argv[]) {
...
}
Par exemple si notre programme est programme et l'utilisateur lance la commande
programme -l arf.txt
alors
argcvaut3 argv[0]contient"programme" argv[1]contient"-l" argv[2]contient"arf.txt" argv[3]est le pointeurNULL
Exercices
- Modifier les projets précédents pour qu'ils prennent en entrée les arguments en ligne de commande
- Ecrire un programme qui prend en entrée un texte et qui renvoie sa version justifiée.
Aller plus loin
- article philosophique sur les chaînes qui finissent par \0 : https://queue.acm.org/detail.cfm?id=2010365
Git (avancé)
Annulation de modifications
Pour annuler des commits et aller quelque part :
git reset [where]
Exemple :
-
annuler le dernier commit :
git reset HEAD^ -
annuler les deux derniers commit :
git reset HEAD^^
Obtenir des informations sur le dépôt
Lister les nouveaux fichiers et à commiter :
git status
Lister les branches
git branch
Branches
Pour créer une nouvelle branche :
git branch [nom-nouvelle-branche]
Pour supprimer une branche :
git branch -d [branche-à-supprimer]
Pour basculer vers une branche :
git checkout [nom-de-branche]
Combiner des branches
Pour fusionner la branche courante avec une autre branche :
git merge [autre-branche]
Pour déplacer les commits de la branche courante après une certaine branche :
git rebase [nom-branche-après-laquelle]
Idée générale
TODO: faire une image plus simple pour commencer
Commandes avancées
| Pour faire ça | Il faut taper ça |
|---|---|
| Modifier l'URL du serveur d'un dépôt local | git remote rm origin puis git remote add origin <url to NEW repo>, puis git push origin --all |
| Pour connaître l'URL du dépôt distant (serveur) | git remote -v |
| Pour arrêter que git demande un mot de passe | git config --global credential.helper store |
Fichiers
Tout est dans
#include <stdio.h>
Lecture
Ouverture d'un fichier
FILE *file;
file = fopen("tilemap.txt", "r");
if (file == NULL)
return -1; // ou exit(-1)
Lire le contenu
while (!feof(file))
{
char line[MAXLINELENGTH] = "";
fgets(line, MAXLINELENGTH, file);
puts(line);
}
feof : ai-je atteint la fin du fichier
feof(file)

fget : lire un caractère
int character = fget(file);
- renvoie le caractère suivant lu dans le fichier
- ou alors
EOFsi on a atteint la fin du fichier

fgets : lire une ligne
fgets(line, MAXLINEENGTH, file)

fscanf : lire des données formatées
fscanf(file, "%s", &variable);
Remarque : scanf(...); c'est la même chose que fscanf(stdin, ...);.
Fermeture du fichier
A la fin, comme on est poli, on ferme le fichier :
fclose(file);
Ecriture
Ouverture du fichier pour y écrire
FILE *file;
file = fopen("tilemap.txt", "w");
if (file == NULL) {
printf("Impossible d'ouvrir le fichier. Voici le code d'erreur : %d\n", errno);
return -1; // ou exit(-1)
}
Attention, le fichier sera complètement écrasé.
En cas d'erreur, file est le pointeur nul, et la variable errno contient un code erreur.
fprintf : écrire des données formatées
fprintf( file, "x = %d\n", i );
Remarque : printf(...); c'est la même chose que fprintf(stdout, ...);. On peut aussi écrire dans la sortie d'erreur fprintf(stderr, ...);
Fermeture du fichier
A la fin, comme on est bien éduqué, on ferme le fichier :
fclose(file);
Autres fonctions
fflush : être sûr que le fichier est à jour
On vous a menti. Si tu dis d'écrire quelque chose, a priori le système ne l'écrit pas tout de suite sur le disque :
Voici ce qui se passe : le système écrit dans un buffer (une "todo list"). Quand le buffer est plein, il écrit vraiment sur le disque, ou alors quand on ferme le fichier.
fflush est un fonction qui force l'écrire :
int fflush( FILE * stream );
Quand on écrit dans un fichier, en fait, le système n'écrit pas directement dans le fichier, mais dans un tampon. Il écrit alors le contenu du tampon quand il est plein ou quand on ferme fichier. La fonction fflush force à écrire le contenu du tampon effectivement dans le fichier.
Un cas d'usage est l'écriture dans un fichier de log.
- Que fait l'instruction
fflush(stdout);?
printf(..) et autres sur la sortie standard (la console) ont bien été affiché.
Se déplacer dans un fichier
La fonction fgetpos permet de sauvegarder la position courante dans une variable (on passe le pointeur en deuxième argument).
int fgetpos( FILE * stream, fpos_t * pos );
fpos_t pos;
if ( fgetpos(file, &pos) != 0 ) {
fprintf(stderr, "Cannot access to the file position");
fclose(file);
exit(EXIT_FAILURE);
}
On peut ensuite revenir à cette position avec fsetpos :
int fsetpos( FILE * stream, fpos_t * pos );
Alternatives
On a aussi les fonctions :
long *ftell(FILE *stream)
donne la position courante depuis le début du fichier :
- en nombre d'octets si le fichier est ouvert en mode binaire
- en nombre de caractères si le fichier est ouvert en mode texte (ça dépend donc de l'encodage)
int *fseek(FILE *stream, long offset, int whence)
- Si
whence == SEEK_SET(0), alors on se déplace deoffset >= 0depuis le début du fichier - Si
whence == SEEK_CUR(1) alors on se déplace deoffsetdepuis la position courante - Si
whence == SEEK_END(2) alors on se déplace deoffset <= 0depuis la fin du fichier
- D'après vous que fait
fseek(stdout, 2, SEEK_SET)?
Lecture/écriture de données
size_t
fread(void *restrict ptr, size_t size, size_t nitems, FILE *restrict stream)
freadlitnitemséléments desizeoctets du fichierstream. Elle les écrit à l'adresseptr.- Elle renvoie le nombre d'éléments lus (a priori
nitems, ou alors moins en cas de fin de fichier ou d'erreurs)
size_t
fwrite(const void *restrict ptr, size_t size, size_t nitems, FILE *restrict stream)
Fonctions variadiques
Une fonction est variadique si le nombre d'arguments est quelconque. Comme par exemple printf !
Motivation
On peut avoir envie de fonctions variadiques comme pour calculer le maximum :
maximum(1, 2)
maximum(1, 2, 9, 5)
stdarg.h
#include <stdarg.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#define SENTINEL -1
/**
* \param the parameters are ints. They should be positive integers except the last number should be SENTINEL.
* \result the maximum about the numbers
* */
int maximum( int first, ... ) {
int max = first;
va_list parametersInfos;
va_start( parametersInfos, first );
while( true ) {
int current = (int) va_arg( parametersInfos, int );
if ( current == SENTINEL) break;
if ( current > max )
max = current;
}
va_end( parametersInfos );
return max;
}
int main() {
printf( "%d\n", maximum( 2, 11, 5, SENTINEL ));
return EXIT_SUCCESS;
}
Failles de sécurité
Débordements de tampons
int save() {
FILE* file = NULL;
char filename[256];
do {
printf("Entrez le nom de la sauvegarde : ");
fflush(stdout);
} while (gets(filename) == NULL);
file = fopen(filename, "rw");
...
}
On suppose ici que le nom de fichier est au plus 256 caractères. Or en réalité rien n'empêche l'utilisateur d'entrer un chaîne de caractères avec plus de 256 caractères.
Le risque est gets aille écrire au delà de la zone réservée pour filename. Elle peut en particulier écrire sur l'adresse de retour de la fonction save.
Pire, un attaquant pourrait se débrouiller que cette adresse de retour soit le contenu du fichier file dans lequel il aura écrit les actions qu'il désire.
Débordement sur le tas
C'est la même idée mais maintenant, on va écrire au delà d'un bloc allouée. On peut alors toucher des informations de gestion de la mémoire (la liste doublement chaînée de la mémoire).
String-format vulnerabilities
int i;
printf("blip%n", &i);
D'habitude printf ne fait que écrire dans la console mais ne modifie pas de variables. En fait, si, avec %n on écrit dans un entier le nombre de caractères déjà écrit sur la console.
Supposons qu'un attaquant contrôle la chaîne de caractères de formatage. Soit trivialement avec :
int i;
printf(stringControléeParLeMéchant, &i);
soit parce qu'il a déjà écrit dans la mémoire à l'endroit de la chaîne de formatage.
Dans ce cas, il peut faire :
int i;
printf("%c %d %n %n %n %n", c, x);
Avec les %n surnuméraires, il écrit dans le contexte de la fonction appelante ou au delà dans la pile.
Conseils :
- éviter
gets,strcat,strcpy,sprintf - utiliser
printf("%s", string)au lieu deprintf(string)! - faire du fuzzing, c'est-à-dire du test avec des entrées aléatoires, à compris tester les fonctions accessibles à l'utilisateur par exemple avec une chaîne de caractères et un entier sensé être sa longueur, mais différente de sa longueur, etc.
Race conditions
Une race condition ou condition de course désigne l'examen d'un contexte puis la prise de la décision en fonction de cet examen. Par exemple : je regarde si j'ai les droits sur un fichier, si oui, j'écris dedans.
Le problème est que le contexte peutchanger entre l'examen et le moment où on agit. Ce problème arrive souvent avec plusieurs threads. Mais il arrive aussi en séquentiel, avec des fichiers notamment.
if(access(filename, W_OK) == 0) {
if((fd = open(filename, O_WRONLY)) == NULL) {
perror(filename);
return 0;
}
/** écrire dans le fichier */
}
Débordements sur les nombres
longueur = ...;//qui dépend de l'utilisateur
char* buf = (char*) malloc(longueur*2);
if(buf == NULL) return -1;
...
Quel est le problème du code ci-dessus ?
longueur * 2 ne tiennent pas dans un size_t.
Supposons que size_t soit un unsigned char, dans ce cas, longueur = 129, que se passe-t-il ?
longueur * 2 vaut 2.
Résultat : on écrit en dehors de la zone allouée, et catastrophe. Avec OpenSSH <=3.3, un problème de ce type permettait à un attaquant d'être administrateur.
Remarque : calloc permet d'allouer n objets de taille m, et ça vérifie que (m \times n) ne déborde pas.
int nombre;
if(nombre < 1000) {
char* buf = malloc(nombre * sizeof(char));
...
}
Est-ce que vous voyez un problème ?
nombre peut être négatif. On convertit en size_t non signé, on allouera souvent une place très grande. On peut alors écrire un très gros fichier, ou envoyer plein de données sur Internet...
Bibliographie
Programmation avancée en C. Sébastien Varette et Nicolas Bernard.
Python
Conditionnals
x = 1
if x == 2:
a = 3
else:
a = 2
a
One-line ternary condition
In languages with a C-syntax, it is possible to write an conditional ternary expression: a = (x == 2) ? 3 : 2. It Python, we can do the same with a more understandable syntax:
a = 3 if x == 2 else 2
a
Easy-to-read conditions
In Python, conditions can be written for normal people.
age = 5
print("young" if 0 < age < 18 else "old")
invitationList = ["Alan", "Bob", "Christine", "Dylan", "Emeline", "Franck"]
me = "John"
if me not in invitationList:
print("you cannot enter")
Assignments in conditions
According to https://peps.python.org/pep-0572/, it is possible to make an assignment in a condition, like in C. To do that, we use the Walrus operator :=.
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
if (n := len(a) > 10):
print(f"List is too long ({n} elements, expected <= 10)")
No switch, sorry
There is no switch in Python, contrary to C. See https://peps.python.org/pep-3103/
Pattern matching
Here is an example of pattern matching (available in Python 3.10, https://docs.python.org/3/reference/compound_stmts.html#match).
i=0
match i:
case 0: print("zero")
case _: print("non zero")
While loops
x = 0
while x < 10:
x += 1
For loops
In Python, it is possible to write for loops. They take the form of for i in BLOUP where BLOUP is an iterable. It matches somehow the theory of primitive recursive functions: we know that for loops terminates if the iterable object produces a finite number of elements.
for i in range(10):
print(i)
Generators
A generator is a special kind of function that contains the keyword yield. It returns an iterable object.
def squares(start, stop):
for i in range(start, stop):
yield i * i
for i in squares(1, 6):
print(i)
1
4
9
16
25
Comparing C and Python
| C | Python | |
|---|---|---|
| Use case | System | Prototyping, scripting, data science, etc. |
| Users | Computer scientists | Computer scientists, Biologists, etc. |
| Usage | Compiled to machine code | Compiled to bytecode, interpreted |
| Typing | Static, weak | Dynamic, strong (somehow static with mypy) |
| Memory usage | By hand (malloc/free) | Automatic via a garbage collector |
import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
History
| When | What |
|---|---|
| 1991 | Creation of Python by Guido van Rossum |
| as a command-line interpreter for the OS Amoeba (research project) | |
| 1994 | Python 1.0: lambda, map, filter and reduce from LISP |
| 2000 | Python 2.0: list comprehensions from SETL (SET Language) and Haskell |
| 2001 | Creation of the Python Software Foundation |
| dec 2008 | Python 3.0 First standardization of C, locales (taking into account user's languages) |
| 2014 | Python package manager pip by default |
- PEP 7 – Style Guide for C Code
- PEP 8 – Style Guide for Python Code
- PEP 20 – The Zen of Python
- PEP 257 – Docstring Conventions
Pythonic constructions
Accessing last elements
In Python, we can access the last elements of a list with index len(L) - 1, len(L) - 2, etc. This is not Pythonic.
L = [1, 2, 1, 3, 4, 5, 8, 42]
L[len(L)-1]
This is the Pythonic option:
L = [1, 2, 1, 3, 4, 5, 8, 42]
L[-1]
Of course, the same trick works for tuples:
t = (1, 2, 1, 3, 4)
t[-1]
Slices
We can obtain slices of a list like this:
L = [1, 2, 1, 3, 4, 5, 8, 42]
L[2:5]
[1, 4]
Quiz
- What are the outputs of the following programs?
L = [1, 2, 1, 3, 4]
L[2] = 500
L
[1, 2, 500, 3, 4]
L = [1, 2, 1, 3, 4]
M = L[2:4]
M[0] = 500
M
[500, 3]
L = [1, 2, 1, 3, 4]
M = L[2:4]
M[0] = 500
L
[1, 2, 1, 3, 4]
We can obtain a slice of a tuple like this:
T = (1, 2, 8, 45, 2)
T[2:5]
(8, 45, 2)
T[:2]
(1, 2)
T[2:]
(8, 45, 2)
More generally, the syntax is L[start:stop:step], where the element at index stop is excluded.
L = list(range(0, 21))
L[1:8:2]
L = list(range(0, 21))
L[-3::-3]
L = list(range(0, 21))
L[-3:0:-3]
Sum of elements
Python provides sum to sum elements of a list, a tuple:
sum([1, 2, 5])
8
sum((1, 2, 5))
8
sum({1, 1, 2, 5})
List/set comprehensions
This code is super ugly:
squares = []
for i in range(10):
squares.append(i**2)
squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
Instead, we can use list comprehension. See https://peps.python.org/pep-0202/
[i*2 for i in range(10)]
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
List comprehension comes from the language SETL (SET Language) in 1969, where we can write:
{x: x in {2..n} | forall y in {2..x-1} | x mod y /= 0}
It is also present in Haskell:
s = [x | x <- [0..], x^2 > 3].
A = [[0 for i in range(10)] for j in range(5)]
A
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
A = [[0 for i in range(10)] for j in range(5)]
A[0].append(1)
A
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
[i for i in range(20) if i%2 == 0]
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
Be careful with *!
[[0]*10]*5
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
A = [[0]*10]*5
A[0][0] = 1
A
[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
Here is an example of set comprehension.
{c for c in "Hello world!"}
{' ', '!', 'H', 'd', 'e', 'l', 'o', 'r', 'w'}
Here is an example of dictionary comprehension.
s = "hello world!"
{c: s.count(c) for c in s}
{'h': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'w': 1, 'r': 1, 'd': 1, '!': 1}
Generators by comprehension
We can also write a sort of list by comprehension but the list itself is never created.
(i*2 for i in range(100))
<generator object <genexpr> at 0x7fd100179eb0>
They can even contain an infinite number of objects:
import itertools
(i*2 for i in itertools.count())
<generator object <genexpr> at 0x7fd100127120>
Unpacking tuples
point = (42, 2)
x, y = point
print(x)
42
x, y = [10, 2]
x
10
x, y = [1, 2, 3]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[28], line 1
----> 1 x, y = [1, 2, 3]
ValueError: too many values to unpack (expected 2)
x, _, y = [1, 2, 3]
y
3
Pattern matching
Here is an example of real pattern matching.
i=0
match i:
case 0: print("zero")
case _: print("non zero")
Functional programming
Python has filter, map, etc. even if they are not very useful because of list/set comprehension.
filter(lambda x: x % 2 == 0, [1, 2, 4, 6])
<filter at 0x7fd1002eafa0>
for x in filter(lambda x: x % 2 == 0, [1, 2, 4, 6]):
print(x)
2
4
6
map(lambda x: 2*x, [1, 2, 3])
<map at 0x7fd0e37be6d0>
list(map(lambda x: x**2, [1, 2, 3]))
[1, 4, 9]
Variables
A variable in Python is a pointer to some content.
Address
Technically, a variable in Python is a pointer, and it contains a memory address to an allocated memory zone containing an object.
x = 42
id(x)
139907129622096
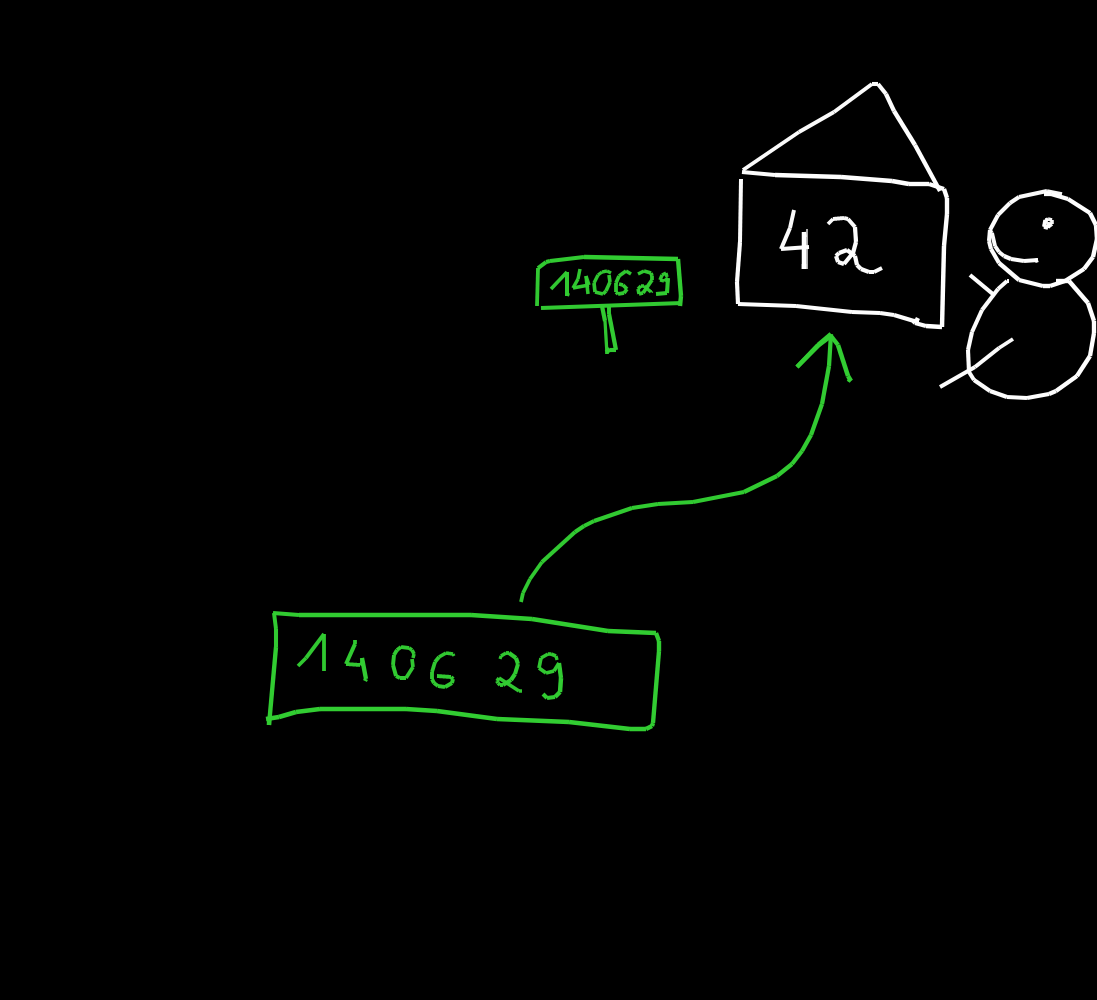
In Python, when numbers are small (between -5 and 255 let say), the memory address are equal.
x = 42
y = 42
print(id(x))
print(id(y))
139907129622096
139907129622096
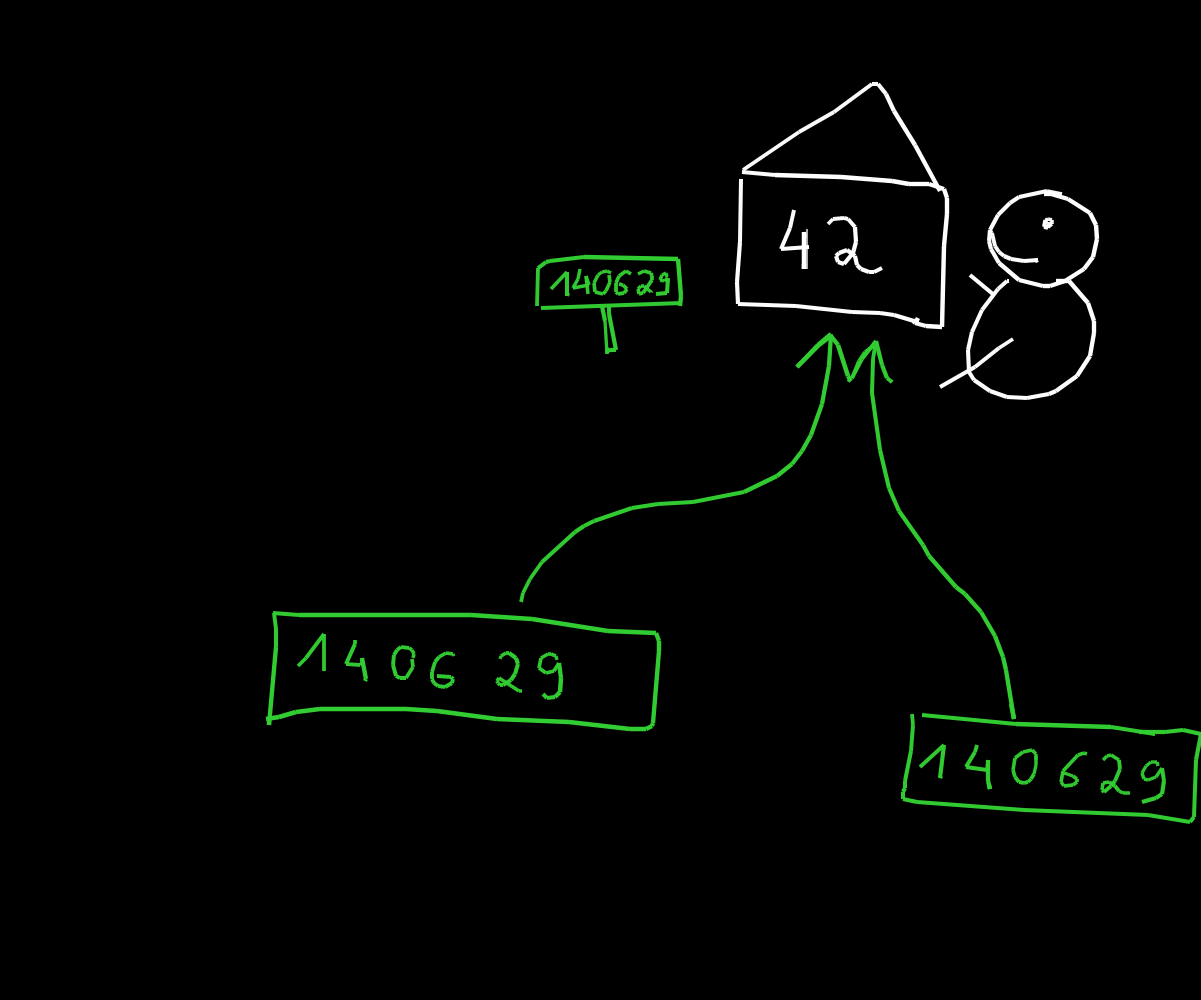
x = 4398473209847023984723981029836012983
y = 4398473209847023984723981029836012983
print(id(x))
print(id(y))
139906654312272
139906654314288
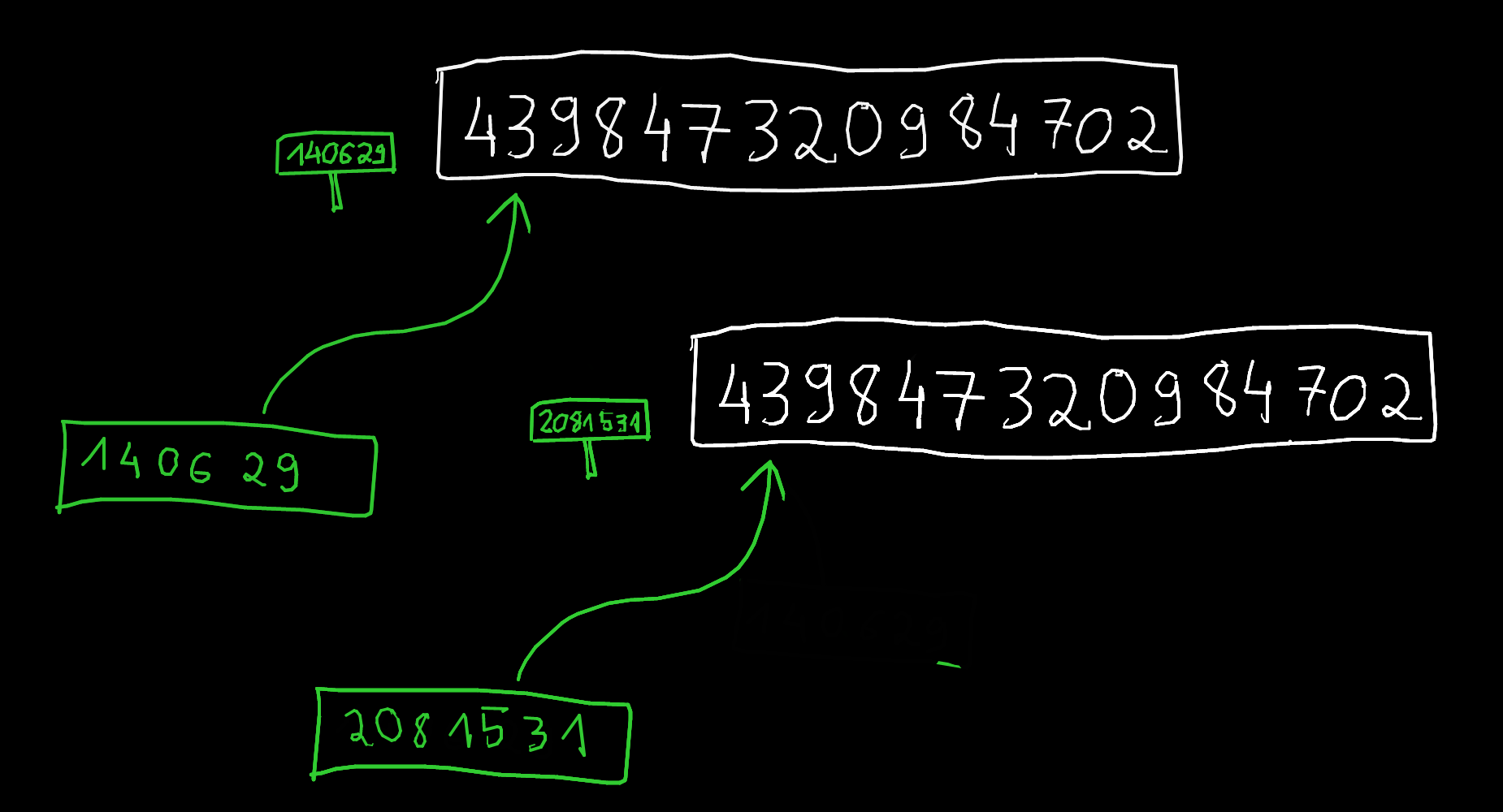
L = (1, 4)
print(id(L))
139906654305152
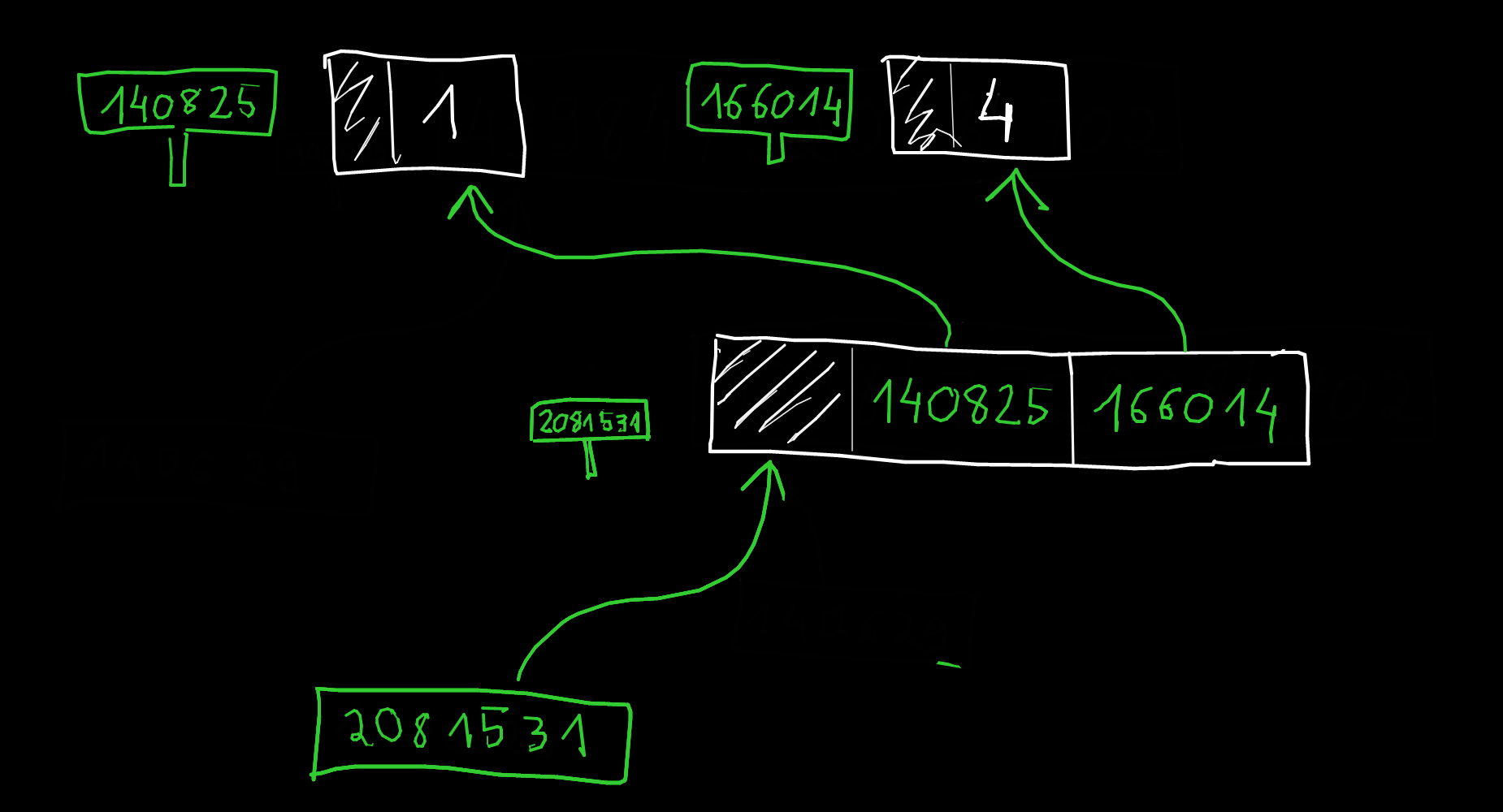
L = (1, 4)
M = (1, 4)
print(id(L))
print(id(M))
139907016431104
139906654343488
Types
Python is dynamically typed: each variable x has a type type(x).
type(2)
int
type([1, 2])
list
type((1, 2))
tuple
type((1,))
tuple
type({1, 2})
set
type(frozenset((1, 2)))
frozenset
Mutability vs Immutability
A variable is mutable when the content can be changed, and immutable otherwise.
| Mutable | Immutable |
|---|---|
int 42, bool True, float 37.5 | |
str "hello" | |
list [1, 2, 3] | tuple (1 2 3) |
dict {"x": 5, "y":2} | from collections import namedtuple |
namedtuple('ImmutableRobot', ['name', 'brandname']) (prefer typing.NamedTuple) | |
| object of a given custom class | |
| set | frozenset |
x = 2
x = 2
x += 1
x = (1, 4)
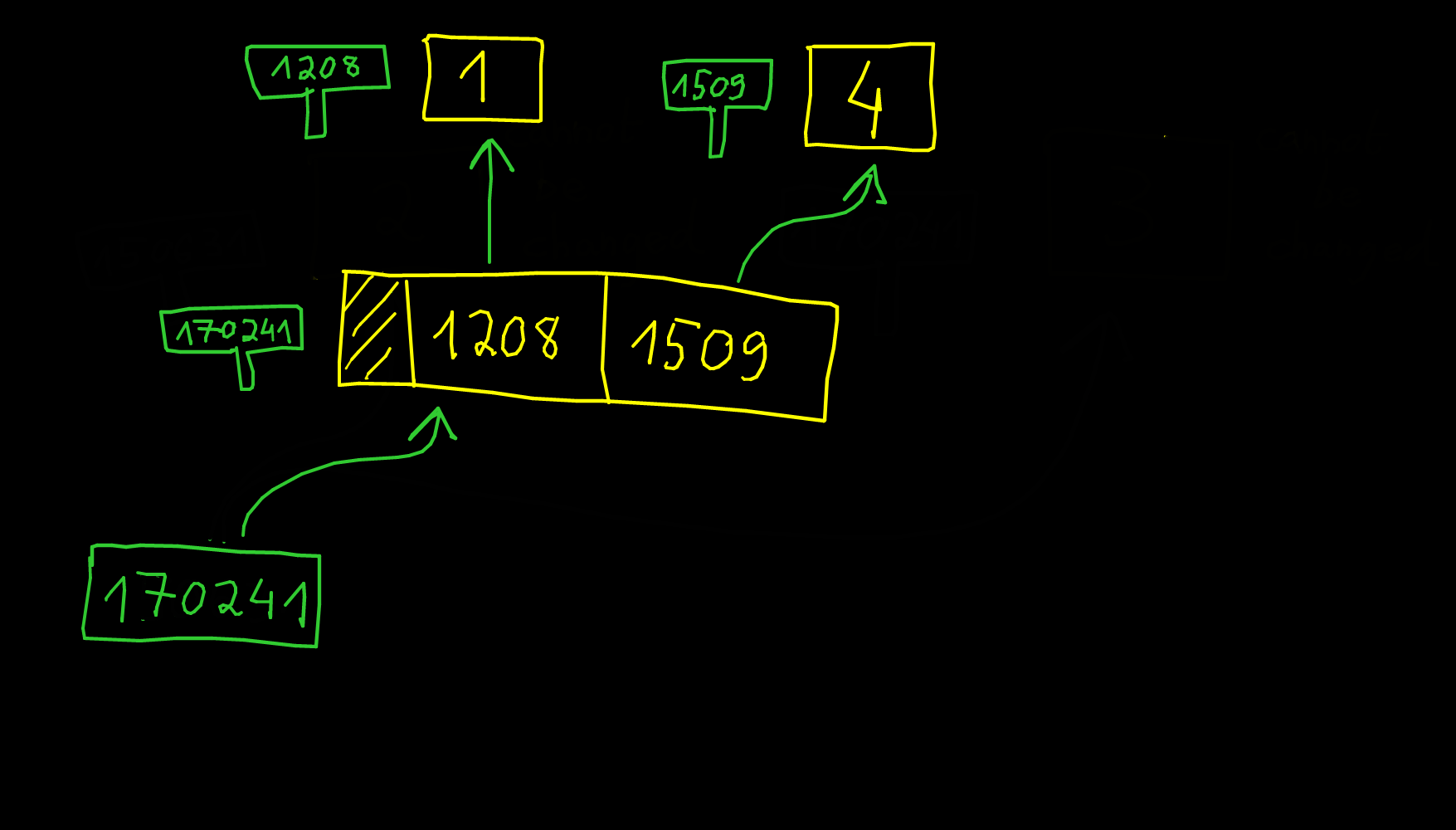
x = (1, 4)
x[0] = 2
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[16], line 2
1 x = (1, 4)
----> 2 x[0] = 2
TypeError: 'tuple' object does not support item assignment
x = [1, 4]
- What do you think about this picture for the datastructure for a list?
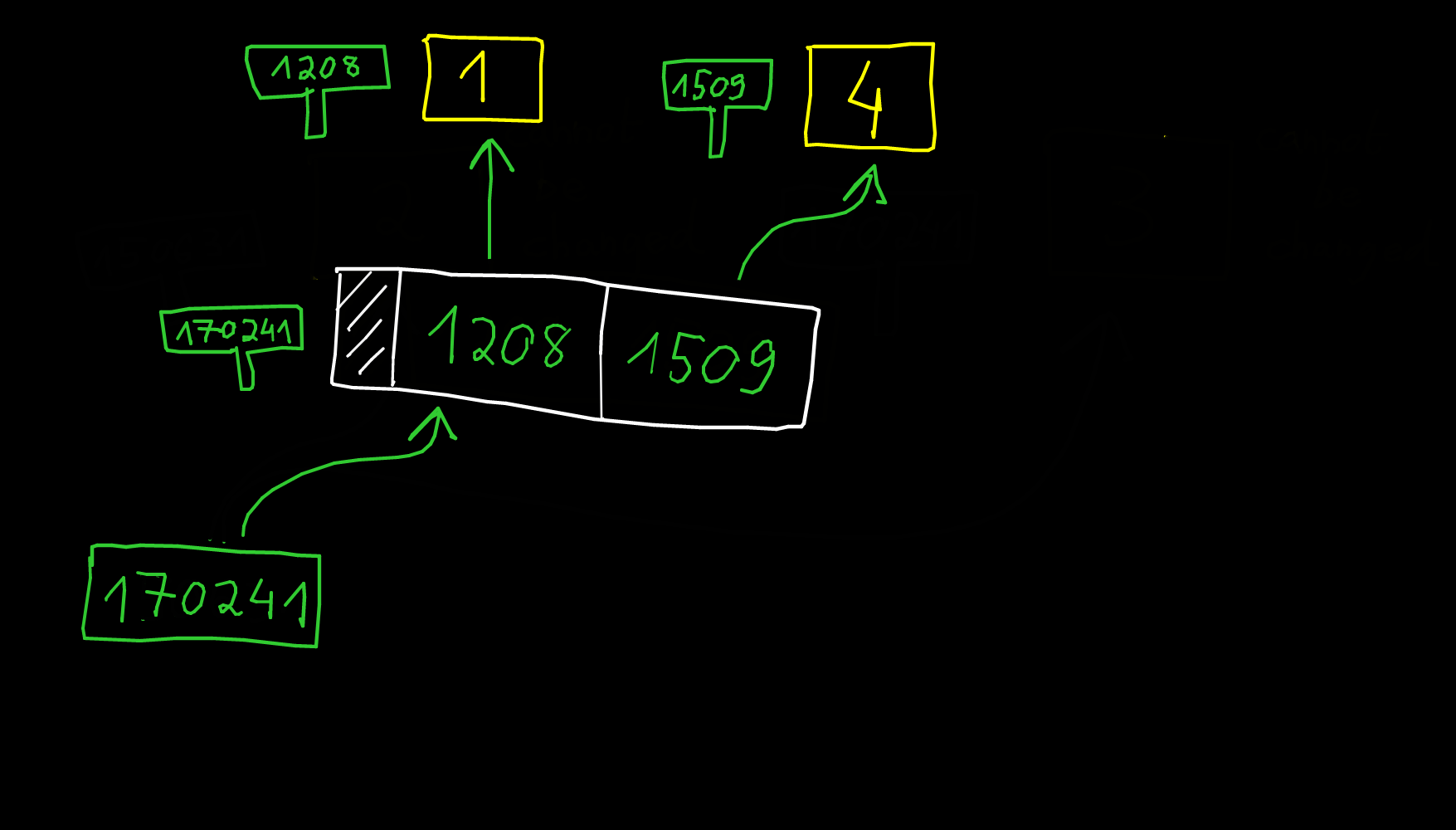
The problem is about resizing the list. The pointer may change. The solution in CPython is to add a new level of indirection.
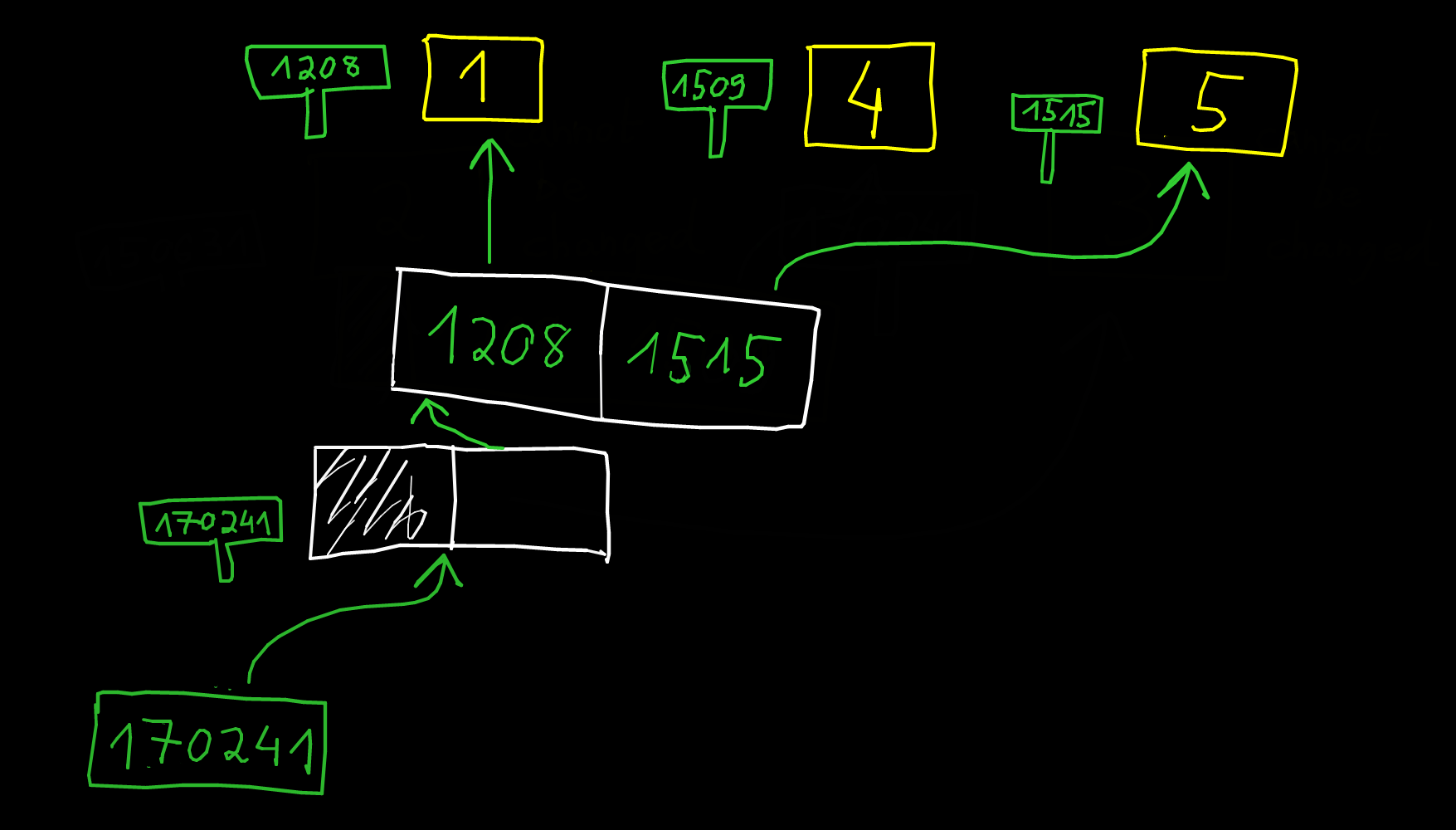
x = [1, 4]
x[1] = 5
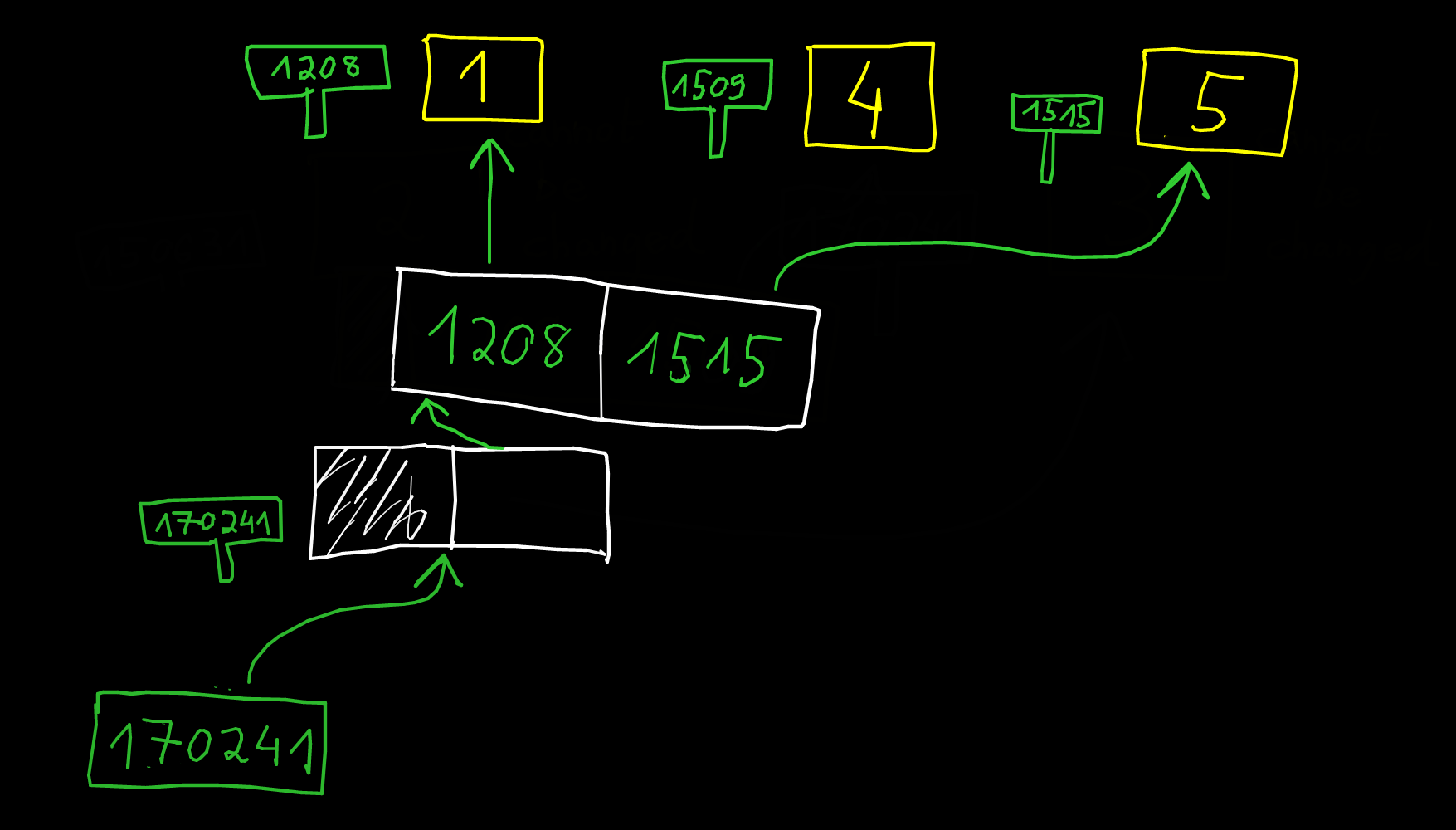
Functions
For the function, it is the same.
def f(x):
return x+1
type(f)
function
Attributes and methods
Each type, e.g. int is a class has attributes and methods obtained with dir(int). dir(2) gives attributes and methods of 2.
dir(int)
['__abs__',
'__add__',
'__and__',
'__bool__',
'__ceil__',
'__class__',
'__delattr__',
'__dir__',
'__divmod__',
'__doc__',
'__eq__',
'__float__',
'__floor__',
'__floordiv__',
'__format__',
'__ge__',
'__getattribute__',
'__getnewargs__',
'__gt__',
'__hash__',
'__index__',
'__init__',
'__init_subclass__',
'__int__',
'__invert__',
'__le__',
'__lshift__',
'__lt__',
'__mod__',
'__mul__',
'__ne__',
'__neg__',
'__new__',
'__or__',
'__pos__',
'__pow__',
'__radd__',
'__rand__',
'__rdivmod__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__rfloordiv__',
'__rlshift__',
'__rmod__',
'__rmul__',
'__ror__',
'__round__',
'__rpow__',
'__rrshift__',
'__rshift__',
'__rsub__',
'__rtruediv__',
'__rxor__',
'__setattr__',
'__sizeof__',
'__str__',
'__sub__',
'__subclasshook__',
'__truediv__',
'__trunc__',
'__xor__',
'as_integer_ratio',
'bit_length',
'conjugate',
'denominator',
'from_bytes',
'imag',
'numerator',
'real',
'to_bytes']
dir(2)
['__abs__',
'__add__',
'__and__',
'__bool__',
'__ceil__',
'__class__',
'__delattr__',
'__dir__',
'__divmod__',
'__doc__',
'__eq__',
'__float__',
'__floor__',
'__floordiv__',
'__format__',
'__ge__',
'__getattribute__',
'__getnewargs__',
'__gt__',
'__hash__',
'__index__',
'__init__',
'__init_subclass__',
'__int__',
'__invert__',
'__le__',
'__lshift__',
'__lt__',
'__mod__',
'__mul__',
'__ne__',
'__neg__',
'__new__',
'__or__',
'__pos__',
'__pow__',
'__radd__',
'__rand__',
'__rdivmod__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__rfloordiv__',
'__rlshift__',
'__rmod__',
'__rmul__',
'__ror__',
'__round__',
'__rpow__',
'__rrshift__',
'__rshift__',
'__rsub__',
'__rtruediv__',
'__rxor__',
'__setattr__',
'__sizeof__',
'__str__',
'__sub__',
'__subclasshook__',
'__truediv__',
'__trunc__',
'__xor__',
'as_integer_ratio',
'bit_length',
'conjugate',
'denominator',
'from_bytes',
'imag',
'numerator',
'real',
'to_bytes']
dir(f)
['__annotations__',
'__call__',
'__class__',
'__closure__',
'__code__',
'__defaults__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__get__',
'__getattribute__',
'__globals__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__kwdefaults__',
'__le__',
'__lt__',
'__module__',
'__name__',
'__ne__',
'__new__',
'__qualname__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__']
f.__code__
<code object f at 0x7f3ea9d110e0, file "/tmp/ipykernel_100995/1304018138.py", line 1>
Reference counters
import sys
lst = []
extra_ref = lst
sys.getrefcount(lst)
3
import sys
sys.getrefcount([])
Quiz: same object or not?
L = [[] for i in range(5)]
L[0].append(1)
L
[[1], [], [], [], []]
L = [[]] * 5
L[0].append(1)
L
[[1], [1], [1], [1], [1]]
Parameter passing
Parameter passing is somehow standard in Python. For instance:
def fact(n):
if n == 0:
return 1
else:
return n * fact(n-1)
fact(50)
30414093201713378043612608166064768844377641568960512000000000000
Default values
Parameters with default values should end the signature:
def f(a, b=0):
...
def f(a, b=1):
return a+b
f(5)
6
def f(a, b=0, c=1):
return a+b+c
Warning when using mutable default values
Mutable default values can lead to unexpected behavior:
def f(b=[]):
b.append(1)
return b
f()
f()
[1, 1]
The solution is to replace the mutable default argument by an immutable one as follows.
def f(b=None):
if b == None:
b = []
b.append(1)
return b
f()
f()
[1]
Positional VS keyword parameters
A positional parameter is characterized by its position. A keyword parameter is characterized by its name.
f(1, b=4)
f(b=4)
etc.
def f(a, b):
return a-b
f(b=2, a=5)
3
Unpacking arguments
On the calling side, it is possible to unpack tuples/lists and dictionnaries.
Unpacking a tuple/list
For instance,
f(*[1, 2, 3, 4])
is the same as:
f(1, 2, 3, 4)
def f(a, b,c, d):
return a+b+c+d
f(*[1, 2, 3, 4])
10
Warning: it is impossible to use * elsewhere than in a call.
*[1, 2]
Cell In[8], line 1
*[1, 2]
^
SyntaxError: can't use starred expression here
Unpacking a dictionnary
With **, you unpack a dictionnary.
f(**{'y': 5, 'z': 6}) is the same as f(y = 5, z= 6).
def f(z, y):
print(f"z = {z} and y = {y}")
f(**{'y': 5, 'z': 6})
z = 6 and y = 5
You can use both at the same time:
def f(a, b,c, d, y, z):
return a+b+c+d+y+z
f(*[1, 2, 3, 4], **{'y': 5, 'z': 6})
21
But you cannot give several arguments:
def f(a, b,c, d, y, z):
return a+b+c+d+y+z
f(*[1, 2, 3, 4], **{'a': 42, 'y': 5, 'z': 6})
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[9], line 4
1 def f(a, b,c, d, y, z):
2 return a+b+c+d+y+z
----> 4 f(*[1, 2, 3, 4], **{'a': 42, 'y': 5, 'z': 6})
TypeError: f() got multiple values for argument 'a'
Unpacking in Javascript
In Javascript, unpacking is performed with ...:
Math.min(...[2, 3, 1]) is the same as Math.min(2, 3, 1).
Packing arguments
It is possible to get all (remaining) arguments at once. This is called packing. It is possible to get:
- all (remaining) positional parameters
*argsas the tupleargs - all (remaining) keyword parameters
**kwargsas a dictionarykwargs
def f(a, b=0, *args, **kwargs):
return a + b + sum(args) + sum(kwargs.values())
f(1, 2, 3, 4, y=5, z=6)
21
Enforcing parameters to be keyword
A stand-alone * means that the parameters that follows * should be given with keywords.
def f(a, b, *, operator):
if operator == "+":
return a+b
else:
return a-b
f(3, 5, '+')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[12], line 7
4 else:
5 return a-b
----> 7 f(3, 5, '+')
TypeError: f() takes 2 positional arguments but 3 were given
def f(a, b, *, operator):
if operator == "+":
return a+b
else:
return a-b
f(3, 5, operator='+')
8
Enforcing parameters to be positional
The / enforces a and b not to be specified by keywords.
def f(a, b, /):
return a+b
f(3, 5)
8
def f(a, b, /):
return a+b
f(a=3, b=5)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[11], line 4
1 def f(a, b, /):
2 return a+b
----> 4 f(a=3, b=5)
TypeError: f() got some positional-only arguments passed as keyword arguments: 'a, b'
Immutability in Python
What is exactly immutability?
Tuples are immutable. It means we cannot change the size and/or reassign another element to a given cell.
A = (1, 2, [42])
A[1] = 56
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[1], line 2
1 A = (1, 2, [42])
----> 2 A[1] = 56
TypeError: 'tuple' object does not support item assignment
However, a tuple may contain mutable elements. The content of these mutable elements can be modified.
L = [42]
A = (1, 2, L)
A[2].append(3)
print(L)
[42, 3]
Use in dictionnaries and sets
When a whole object is immutable (e.g. tuples of integers, tuples of tuples, etc. but not tuples of lists), it can be used as a key in dictionnaries, or an element in sets. This is because they are hashable.
Technical remark. Actually, some mutable objects could be hashable in principle. But it is a terrible idea. Indeed, the hash of such an element could be just defined in terms of the id (address of the pointer) while equality may be defined from the inner values that may change.
S = {1, 2, 3}
S
{1, 2, 3}
S = {"Bonjour", 1}
S = {(1, 2), (3, 0)}
(132).__hash__()
132
(13200000).__hash__()
13200000
(1320000000000000000000).__hash__()
1057798729767060028
(132,).__hash__()
-2719358537048335948
((1, 2)).__hash__()
-3550055125485641917
[1, 2].__hash__()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[21], line 1
----> 1 [1, 2].__hash__()
TypeError: 'NoneType' object is not callable
S = {(1, 2), (3, 0), (1, 2)}
S
{(1, 2), (3, 0)}
{[], [1]}
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[2], line 1
----> 1 {[], [1]}
TypeError: unhashable type: 'list'
([]).__hash__()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[9], line 1
----> 1 ([]).__hash__()
TypeError: 'NoneType' object is not callable
D = {}
type(D)
dict
D = {(1, 2): 3, (5, 67): None}
D[(1, 2)]
3
Creation of a new object or not?
When a type is mutable, Python creates new objects, because we never know... you may modify it later on:
A = [1, 2]
A is A[:]
False
When the type is immutable, Python does not create a new object if not necessary.
A = (1, 2)
A is A[:]
True
Strings in Python
Strings in Python are immutable arrays of characters.
Accessing characters
s = "Hello"
s[1]
'l'
s = "Hello"
s[-1]
'o'
Immutability
Immutability means that the content of the object cannot change.
s = "Hello"
s[1] = "a"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[3], line 2
1 s = "Hello"
----> 2 s[1] = "a"
TypeError: 'str' object does not support item assignment
However, a variable can be reassigned.
s = "Hello "
s = s + "ENS Lyon!"
print(s)
Hello ENS Lyon!
Multiple assignments
s = ""
for i in range(10000000):
s += f"entier {i};"
L = [f"entier {i};" for i in range(10000000)]
''.join(L)
import io
ss = io.StringIO()
for i in range(10000000):
ss.write(f"entier {i};")
s = ss.getvalue()
Equality in Python
== (Same value)
== checks that two variables have the same value. The Python interpreter will look at the content of the variables to evaluate a == b.
For standard objects
a = [1, 2]
b = []
b.append(1)
b.append(2)
a == b
True
123456789 == 123456789
True
a = 123456789
b = 123456788+1
a == b
True
a = (1, 2, 3)
b = [1, 2, 3]
a == b
False
For custom objects
For custom objects, == has to specified via the magic method __eq__. Actually... for all objects!
class User:
def __init__(self, username: str, email: str):
self.username = username
self.email = email
User("francois", "francois@ens-lyon.fr") == User("francois", "francois@ens-lyon.fr")
False
class User:
def __init__(self, username: str, email: str):
self.username = username
self.email = email
def __eq__(self, other: object):
if isinstance(other, User):
return self.username == other.username and self.email == other.email
return NotImplemented
User("francois", "francois@ens-lyon.fr") == User("francois", "francois@ens-lyon.fr")
True
class User2:
def __init__(self, username: str, email: str):
self.username = username
self.email = email
User2("francois", "francois@ens-lyon.fr") == User2("francois", "francois@ens-lyon.fr")
False
is (Same object)
is means the same object. The Pyther interpreter will just check the memory address. a is b is true iff the memory address of a and b are the same (same pointers, i.e. pointers pointed to the very same object).
class Person:
pass
a = Person()
b = Person()
a is b
False
class Person:
pass
a = Person()
b = a
a is b
True
a = 123456789
b = 123456789
a is b
False
a = 123456789
b = a
a is b
True
a = 123456789
b = 123456788+1
a is b
False
a = 2
b= 1+1
a is b
True
a = [1,2]
b = a
a is b
True
a = (1, 2, 3)
b = (1, 2, 3)
a is b
False
Summary
In German:
isisdas selbe==isdas gleiche
Programmation objet
Motivation
sur ChatGPT, demander "give me a Python program that runs A* on a graph described as a png image (each white pixel is a vertex, and black pixels are obstacles)"
=> le résultat est un code monolithique. => Difficile d'avoir confiance, à comprendre, tester, vérifier => Difficile à améliorer => Difficile de réutiliser le code ailleurs
Struct
- LISP : en plus des listes, des objets avec des champs/attributs 1960s
Objet
Un objet est un ensemble de données (champs) + fonctions (méthodes). Une classe est une ensemble de champs et de définitions de méthodes.
- ALGOL W en 1966 : C. A. R. Hoare, champs/attributs et méthodes, mais pas de constructeurs
- Simula 67 par Ole-Johan Dahl and Kristen Nygaard in Norway :
- constructeur
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def norm():
return sqrt(self.x ** 2 + self.y ** 2)
p = Point(2, 3)
print(p.norm())
class Graph:
def __init__(self, n: int):
self.nbVertices = n
self.adjList: list[list[int]] = [[] for _ in range(n)]
def addEdge(self, u:int, v:int):
self.adjList[u].append(v)
def neighbors(self, v: int) -> list[int]:
return self.adjList[v]
Encapsulation
L' encapsulation a deux sens : le fait d'avoir les données et les méthodes. Mais aussi de cacher des champs aux utilisateurs.
- Simula 67 :
- naissances des champs privés et publics (privés = "hidden")
En Python, mettre __ devant le nom de champs et il est privé.
Apparté Python
[[]] * n VS [[] for _ in range(n)]
[2] * 3
Vision d'Alan Kay
Smalltalk 1970
- Encapsulation
- Message passing
- Liaison dynamique ~ Duck typing
class Cat:
def speak(self):
print("miaou")
class Dog:
def speak(self):
print("waouf")
L: list[Cat | Dog] = [Cat(), Dog(), Cat(), Cat()]
for animal in L:
animal.speak()
- isinstance(objet, class)
Héritage
Une classe A hérite de B si tout objet A est un B.
from abc import ABCMeta, abstractmethod
class Animal():
pass
class Cat(Animal):
def speak(self):
print("miaou")
class Dog(Animal):
def speak(self):
print("waouf")
L: list[Animal] = [Cat(), Dog(), Cat(), Cat()]
a = Animal() #fails
for animal in L:
animal.speak()
polymorphisme par héritage
- issubclass(class1, class2)
Classe abstraite
Une classe abstraite (Abstract Base Classes) est une classe où toutes les méthodes ne sont pas définies.
from abc import ABCMeta, abstractmethod
class Animal(metaclass=ABCMeta):
def hello(self):
print("hello")
@abstractmethod
def speak(self) -> None:
raise NotImplementedError
class Cat(Animal):
def speak(self):
print("miaou")
class Dog(Animal):
def speak(self):
print("waouf")
L: list[Animal] = [Cat(), Dog(), Cat(), Cat()]
a = Animal() #fails
for animal in L:
animal.hello()
animal.speak()
- Simula 67
- héritage
- méthodes virtuelles
Tout coder (sans type paramétrées)
Itérateur
-
Objet itérable : liste, etc.
-
Itérateur
-
Générateur
-
CLU (for "CLUsters") par Barbara Liskov en 1973 :
- types abstraits
- itérateurs
Types paramétrées (polymorphisme de type)
- types paramétrées (e.g List[T])
- types somme (e.g. List[T] | None)
- pas d'héritage (!)
Finir l'implémentation
Exemple de patron de conception
- Tableaunoir : patron de conception Command
Classes
Motivation
We aim at avoiding code where the data is scattered. For instance:

import math
x = 2
y = 3
xList = [1, 2, 3, 4]
yList = [1, 2, 3, 4]
def norm(x, y):
return math.sqrt(self.x ** 2 + self.y ** 2)
- Are variables
xandy? - Are
xListandyListtogether mean list of points?
A first answer: struct
The C language offers struct in order to group data together.
import math
class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
v = Vector2D(2, 3)
L = [Vector2D(1, 1), Vector2D(2, 2), Vector2D(3, 3), Vector2D(4, 4)]
def norm(v: Vector2D):
return math.sqrt(v.x ** 2 + v.y ** 2)
norm(v)
3.605551275463989
But the functions applied to the data are still scattered.

A class = struct + methods
A class mixes both data (fields and attributes) and methods (= functions applied to data). This is called encapsulation. A class desfines a type of objects.

Advantages:
- Functions are no more lost and the code is more organized (kind of namespace)
- More obvious to know on what the method is applied on
import math
class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def norm(self):
return math.sqrt(self.x ** 2 + self.y ** 2)
def scale(self, scalar):
self.x *= scalar
self.y *= scalar
v = Vector2D(2, 1)
v.scale(0.5)
print(v.norm())
v.scale(4)
print(v.norm())
print(v.x)
print(v.y)
1.118033988749895
4.47213595499958
4.0
2.0
The variable v is (contains/points to) an object. We say that v is an instance of the class Vector2D. Of course, we can have several instances, and each instance contains its own data:
v = Vector2D(2, 1)
w = Vector2D(1, 1)
The concept of class (and of object-oriented programming) appears in many languages: C++, Java, Javascript, C#, etc.
Methods
A method is a function applied on an object and defined in a class. In object-oriented object, the goal is to have different objects interacting via message-passing. For instance speak asks the cat to speak.
class Cat():
name = "Garfield"
def speak(self):
print(f"{self.name} says miaou.")
c = Cat()
c.speak()
c.name = "Felix"
c.speak()
Garfield says miaou.
Felix says miaou.
Of course, methods can have parameters than the object itself.
class Cat():
name = "Garfield"
def speak(self, strength):
print(f"{self.name} says {'miaou' if strength < 5 else 'MIAOU'}.")
c = Cat()
d = Cat()
c.speak(2)
d.speak(5)
Garfield says miaou.
Garfield says MIAOU.
Dataclasses
Dataclasses are specific to Python and helps to define classes without redefining the same `standard' methods over and over again.
Problems
When we defined a class Vector2D, equalities remain naïve by default.
class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
Vector2D(1, 2) == Vector2D(1, 2) # oh no!!
False
Also printing a Vector2D is not very informative.
print(Vector2D(1, 2))
<__main__.Vector2D object at 0x7f7ff414ce80>
Cumbersome solution...
A cumbersome solution would be to write the magic method __eq__ ourselves in order to make the equality == work properly.
class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __eq__(self, other):
return (self.x == other.x) and (self.y == other.y)
Vector2D(2, 3) == Vector2D(2, 3)
True
In the same way, we can define the magic method __repr__ for having a nice pretty printing.
class Vector2D:
def __init__(self, x, y):
self.x = x
self.y = y
def __eq__(self, other):
return (self.x == other.y) and (self.y == other.y)
def __repr__(self):
return f"(x={self.x}, y={self.y})"
print(Vector2D(1, 2))
(x=1, y=2)
Pythonic solution
Python provides dataclasses for automatically define these standard behaviors. See https://peps.python.org/pep-0557/. We do not have to write __eq__, __repr__, ourselves anymore. Python automatically defines them. Even more, Python automatically defines __init__, etc. and many other standard magic functions for obtaining standard behaviors for free. Look:
from dataclasses import dataclass
@dataclass
class Vector2D:
"""Class for representing a point in 2D."""
x: float
y: float
v = Vector2D(1, 2)
w = Vector2D(1, 2)
print(v == w)
print(v)
True
Vector2D(x=1, y=2)
@dataclass is a class decorator.
Abstraction
Abstraction consists in hidding the low-level details of an object from the user of the object.
- In some languages, e.g. C++ and Java, we have keywords like private VS public to explicitely say whether a field/method is private/public.
- In Python, we implicitely inform the user that an attribute/method is private by starting its name with
__(and not finishing with__otherwise you get a magic function 😉). See https://peps.python.org/pep-0008/
class Animal:
def __init__(self, health):
self.__health = health
def showHealth(self):
print(self.__health)
a = Animal(5)
a.showHealth()
a.__health
5
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[26], line 10
8 a = Animal(5)
9 a.showHealth()
---> 10 a.__health
AttributeError: 'Animal' object has no attribute '__health'
Actually, it creates a field _Animal__health. This is super ugly!
a._Animal__health
5
Exercice: Write a class for a grid graph created with an image.
Inheritance
Definition
A class A inherits from B if all A are B.
Examples:
- all cats are animals
- all integers are numbers
- in a video games, all enemies are movable entities
Why inheritance?
- Because we can easily reuse the common shared code for animals for cats. (this is a bit fake)
- It allows abstraction. Some part of the program just consider animals, whether a given object is a cat, dog, etc. is not important. This is called polymorphism.

UML diagrams
We use UML class diagrams that are graphs: nodes are classes and an edge from class A to B means "A is a subclass of B". For instance:
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([('Cat', 'Animal')])
dot

from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("Dog", "Animal"), ("Cat", "Animal"), ("Fish", "Animal")])
dot

How to inherit in Python
A subclass of a class is a class that inherits from it. This is abstraction!
- Any cat is an animal.
- Any integer is a number.
class Animal():
lifepoints = 10
def speak(self):
pass
class Cat(Animal):
def speak(self):
print("miaou")
class MagicCat(Cat):
def speak(self):
print("MiAoU")
class Animal():
lifepoints = 10
def speak(self):
pass
class Cat(Animal):
def speak(self):
print("miaou")
class MagicCat(Cat):
def speak(self):
print("MiAoU")
9
10
isinstance
isinstance(Cat(), Cat)
True
garfield = Cat()
isinstance(garfield, Animal)
True
garfield = Cat()
isinstance(garfield, object)
True
isinstance(Cat(), list)
False
isinstance(Cat, Animal)
False
isinstance(Cat, type)
True
isinstance(Cat, object)
True
isinstance(type, object)
True
isinstance(object, type)
True
isinstance(2, type)
False
issubclass
issubclass(Animal, Animal)
True
issubclass(Cat, Animal)
True
issubclass(list, Animal)
False
(Inheritance) Polymorphism
The goal of inheritance is also to treat several objects of different types in the same way. This is called polymorphism. An animal speaks whatever it is.
class Animal():
lifepoints = 10
class Cat(Animal):
def speak(self):
print("miaou")
class Dog(Animal):
def speak(self):
print("waouf")
class Duck(Animal):
def speak(self):
print("coin")
L = [Cat(), Dog(), Cat(), Cat(), Duck()]
for animal in L:
animal.speak()
miaou
waouf
miaou
miaou
coin
for animal in L:
if animal.type == Cat:
...
elif animal.type == Dog:
...
Duck typing
In Python, actually, we do not need inheritance in that case. As long an object looks like a duck, it is a duck. Here, as long an object can speak, it is an animal.
class Cat:
def speak(self):
print("miaou")
class Dog:
def speak(self):
print("waouf")
L = [Cat(), Dog(), Cat(), Cat()]
for animal in L:
animal.speak()
miaou
waouf
miaou
miaou
Examples
Example of the number class hierarchy in Python
Here is the class hierarchy for the numbers in Python. See https://peps.python.org/pep-3141/ where you may read the rejected alternatives.
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([('Complex', 'Number'), ('complex', 'Complex'), ('Real', 'Complex'), ('float', 'Real'), ('Rational', 'Real'), ('Integral', 'Rational'), ('int', 'Integral'), ('bool', 'int')])
dot

import numbers
isinstance(5, numbers.Number)
True
Example of datastructures used in Dijkstra's algorithm
Dijkstra's algorithm needs a graph and a priority queue. But the details on how the graph and the priority queue is implemented does not matter for Dijkstra's algorithm. Inheritance enables abstraction. The most obvious way is to declare interfaces:
- an interface
Graphand then we can for instance implement a grid graph stored as a PNG image file; - an interface
PriorityQueueand then we could implement for instance a binary heap.
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("PNGGridGraph", "Graph"), ("VoxelGraph", "Graph"), ("ExplicitGraph", "Graph")])
dot

from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("ArrayPriorityQueue", "PriorityQueue"), ("BinaryHeap", "PriorityQueue"), ("FibonacciHeap", "PriorityQueue")])
dot

In a video game, we could imagine characters that are animals of different types.
Exercice
- Write A* algorithm and adequate classes for representing a graph and a priority queue (e.g. a binary heap).
Overriding
Overriding (spécialisation or redéfinition in french) consists in redefining a method in a subclass.

class Animal:
def speak(self):
print("...")
class Cat(Animal):
def speak(self):
print("miaou")
a = Animal()
a.speak()
c = Cat()
c.speak()
...
miaou
Delegation to superclass methods
Problem
If we override a method, the previous one can a priori not be called anymore.

class Animal:
def __init__(self):
self.number_of_times_I_spoke = 0
def speak(self):
self.number_of_times_I_spoke += 1
class Cat(Animal):
def speak(self):
print("miaou")
a = Animal()
a.speak()
print(a.number_of_times_I_spoke)
c = Cat()
c.speak()
print(c.number_of_times_I_spoke)
1
miaou
0
(Not so great) solution
We can explicitely mention the class name Animal to have access to the method defined in Animal.
class Animal:
def __init__(self):
self.number_of_times_I_spoke = 0
def speak(self):
self.number_of_times_I_spoke += 1
class Cat(Animal):
def speak(self):
Animal.speak(self) # yes
print("miaou")
a = Animal()
a.speak()
print(a.number_of_times_I_spoke)
c = Cat()
c.speak()
print(c.number_of_times_I_spoke)
1
miaou
1
Example with the initializer


class Animal:
def __init__(self):
self.health = 3
class Cat(Animal):
def __init__(self):
self.mustache = True
garfield = Cat()
garfield.health
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[4], line 10
7 self.mustache = True
9 garfield = Cat()
---> 10 garfield.health
AttributeError: 'Cat' object has no attribute 'health'
The solution is again to explicitely mention the class name Animal to have access to the method defined in Animal.
class Animal:
def __init__(self):
self.health = 3
class Cat(Animal):
def __init__(self):
Animal.__init__(self) # yes
self.mustache = True
garfield = Cat()
garfield.health
3
The super function
Problem
Writing Animal.speak(self) is not so robust. It may fail if we add a new subclass etc.
Solution
The function super creates a wrapper object of self for accessing methods as we were in the next superclass of the current one.

class Animal:
def __init__(self):
self.number_of_times_I_spoke = 0
def speak(self):
self.number_of_times_I_spoke += 1
class Cat(Animal):
def speak(self):
super().speak() # yes
print("miaou")
a = Animal()
a.speak()
print(a.number_of_times_I_spoke)
c = Cat()
c.speak()
print(c.number_of_times_I_spoke)
1
miaou
1
class Animal:
def __init__(self):
self.health = 3
class Cat(Animal):
def __init__(self):
super().__init__()
self.mustache = True
garfield = Cat()
garfield.health
10
What is exactly this super()?
Actually, super() is syntaxic sugar for super(Cat, self). It gives a wrapper object of self which calls the methods as if we were in the next superclass of Cat with the very instance.

class Animal:
def __init__(self):
self.health = 3
class Cat(Animal):
def __init__(self):
super(Animal, self).__init__()
self.mustache = True
garfield = Cat()
garfield.health
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[9], line 11
8 self.mustache = True
10 garfield = Cat()
---> 11 garfield.health
AttributeError: 'Cat' object has no attribute 'health'
More precisely, it is syntactic sugar for super(self.__class__, self) where __class__ is a magic method that returns the class of an object.
Quiz
class Animal:
def speakTwice(self):
self.speak()
self.speak()
def speak(self):
pass
class Cat(Animal):
def speak(self):
print("miaou")
class Dog(Animal):
def speak(self):
print("waouf")
for a in [Cat(), Dog()]:
a.speakTwice()
miaou
miaou
waouf
waouf
class Animal:
def speakTwice(self):
self.speak()
self.speak()
def speak(self):
print("no sound")
class Cat(Animal):
def speak(self):
print("miaou")
class Dog(Animal):
def speak(self):
print("waouf")
for a in [Cat(), Dog()]:
a.speakTwice()
miaou
miaou
waouf
waouf
class Animal:
def speakTwice(self):
self.speak()
self.speak()
def speak(self):
print("no sound")
class Cat(Animal):
def speak(self):
print("miaou")
class Dog(Animal):
def speak(self):
super().speak()
print("waouf")
for a in [Cat(), Dog()]:
a.speakTwice()
miaou
miaou
no sound
waouf
no sound
waouf
class Animal:
def __init__(self):
self.sound = "no sound"
def speakTwice(self):
self.speak()
self.speak()
def speak(self):
print(self.sound)
class Cat(Animal):
def __init__(self):
self.sound = "miaou"
class Dog(Animal):
def __init__(self):
self.sound = "waouf"
def speak(self):
super(Dog, self).speak()
print("tss tss")
for a in [Cat(), Dog()]:
a.speakTwice()
miaou
miaou
waouf
tss tss
waouf
tss tss
class Animal:
def speakTwice(self):
self.speak()
self.speak()
def speak(self):
print("no sound")
class Cat(Animal):
def speak(self):
print("miaou")
class Dog(Animal):
def speak(self):
print("waouf")
for a in [Cat(), Dog()]:
super(Cat, a).speak()
no sound
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[16], line 18
15 print("waouf")
17 for a in [Cat(), Dog()]:
---> 18 super(Cat, a).speak()
TypeError: super(type, obj): obj must be an instance or subtype of type
class Animal:
def speakTwice(self):
self.speak()
self.speak()
def speak(self):
print("no sound")
class Cat(Animal):
def speak(self):
print("miaou")
class Dog(Animal):
def speak(self):
print("waouf")
for a in [Cat(), Cat()]:
super(Cat, a).speak()
no sound
no sound
class Animal:
def speakTwice(self):
print(type(self))
self.speak()
self.speak()
def speak(self):
print("no sound")
class Cat(Animal):
def speak(self):
print("miaou")
class Dog(Animal):
def speak(self):
print("waouf")
for a in [Cat(), Cat()]:
super(Cat, a).speakTwice()
<class '__main__.Cat'>
miaou
miaou
<class '__main__.Cat'>
miaou
miaou
Iterable objects and iterators
Motivation
The objective is to write more elegant code that the for(int i = 0; i < n; i++) style of code. For instance, the following code is ugly.
A = [1, 7, 9, 3, 4]
for i in range(len(A)):
print(f"We have {A[i]} in the array")
On a 1 dans le tableau
On a 7 dans le tableau
On a 9 dans le tableau
On a 3 dans le tableau
On a 4 dans le tableau
Instead, write this:
A = [1, 7, 9, 3, 4]
for el in A:
print(f"We have {el} in the array")
We have 1 in the array
We have 7 in the array
We have 9 in the array
We have 3 in the array
We have 4 in the array
Definition
Iterators
An iterator is an object that gives you elements when pressing the next button. Like a coffee machine or a food dispenser:
Iterable objects
An iterable object is an object that can be transformed into an iterator. In for x in BLOUP, BLOUP should be an iterable object.
List
[1, 6, 2]
[1, 6, 2]
In Python:
- An iterable object can be transformed into an interator via
__iter__() - An iterator is an object implementing
__next__().
it = [1, 6, 2].__iter__()
print(it.__next__())
print(it.__next__())
print(it.__next__())
print(it.__next__()) # raise a StopIteration error
1
6
2
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
Cell In[12], line 5
3 print(it.__next__())
4 print(it.__next__())
----> 5 print(it.__next__()) # raise a StopIteration error
StopIteration:
Range
range(4)
range(0, 4)
for i in range(4):
print(i)
0
1
2
3
it = range(4).__iter__()
print(it.__next__())
print(it.__next__())
print(it.__next__())
print(it.__next__())
print(it.__next__()) # raise a StopIteration error
0
1
2
3
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
Cell In[17], line 6
4 print(it.__next__())
5 print(it.__next__())
----> 6 print(it.__next__()) # raise a StopIteration error
StopIteration:
Many iterable objects and iterators are lazy data structures. For instance, range(100000000) will not create a list of 100000000 elements! It is inspired from constructions in Haskell.
Generators
A generator is a special kind of function that contains the keyword yield. It returns an iterable object.
def squares(start, stop):
for i in range(start, stop):
yield i * i
it = squares(1, 5).__iter__()
print(it.__next__())
print(it.__next__())
print(it.__next__())
print(it.__next__())
print(it.__next__())
1
4
9
16
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
Cell In[10], line 6
4 print(it.__next__())
5 print(it.__next__())
----> 6 print(it.__next__())
StopIteration:
for i in squares(1, 6):
print(i)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[1], line 1
----> 1 for i in squares(1, 6):
2 print(i)
NameError: name 'squares' is not defined
def all_integers():
i = 0
while True:
yield i
i += 1
N = all_integers()
iter = N.__iter__()
print(next(iter))
print(next(iter))
0
1
Generators can also be defined with a functional construction, using parenthesis.
all_squares = (a ** 2 for a in all_integers())
N = all_squares
iter = N.__iter__()
print(next(iter))
print(next(iter))
print(next(iter))
print(next(iter))
0
1
4
9
Nest generators
Generators can be nested but not in naive way:
def f():
yield 1
yield 2
def g():
f()
yield 3
for i in g():
print(i)
3
You may write:
def f():
yield 1
yield 2
def g():
for j in f():
yield j
yield 3
for i in g():
print(i)
1
2
3
Or more elegantly:
def f():
yield 1
yield 2
def g():
yield from f()
yield 3
for i in g():
print(i)
1
2
3
Converting iterable objects into lists, etc.
list(ITERABLE) takes the iterable, get an iterator, and then press the next button until no more food gets out. All the items are then collected into a list.
list((1, 2, 3))
[1, 2, 3]
[*(1, 2, 3)]
[1, 2, 3]
list(squares(1, 6))
[1, 4, 9, 16, 25]
[*squares(1, 6)]
[1, 4, 9, 16, 25]
list(all_integers())
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[20], line 1
----> 1 list(all_integers())
Cell In[19], line 4, in all_integers()
2 i = 0
3 while True:
----> 4 yield i
5 i += 1
KeyboardInterrupt:
list({"a": 0, "b": 1})
['a', 'b']
set((1, 2, 3))
{1, 2, 3}
{*(1, 2, 3)}
{1, 2, 3}
frozenset([1, 2, 3])
frozenset({1, 2, 3})
tuple([1,2, 3])
(1, 2, 3)
(*[1, 2, 3],)
(1, 2, 3)
Enumerate
Sometimes you need the index and the element and you are stuck with: The enumerate function transforms any iterable object into a new iterable object that incorporates a counter.
fruits = ['banana', 'kiwi', 'strawberry']
for fruit in fruits:
print(f"Fruit number ?? is a {fruits[i]}")
le fruit numéro ?? est une pomme
le fruit numéro ?? est une banane
le fruit numéro ?? est une orange
So you are lazy and you write:
fruits = ['banana', 'kiwi', 'strawberry']
for i in range(len(fruits)):
fruit = fruits[i]
print(f"Fruit number {i+1} is a {fruit}")
le fruit numéro 1 est une pomme
le fruit numéro 2 est une banane
le fruit numéro 3 est une orange
But you can use enumerate that creates an interable object.
fruits = ['banana', 'kiwi', 'strawberry']
enumerate(fruits, start=1)
<enumerate at 0x7f87a626d200>
fruits = ['banana', 'kiwi', 'strawberry']
for i, fruit in enumerate(fruits, start=1):
print(f"Fruit number {i} is a {fruit}")
Fruit number 1 is a banana
Fruit number 2 is a kiwi
Fruit number 3 is a strawberry
Zip
Zip consists in transforming several iterables into a single one.
fruits = ['banana', 'kiwi', 'strawberry']
prices = [2, 4, 8]
for i in range(len(fruits)):
print(f"{fruits[i]} and costs {prices[i]}")
banana and costs 2
kiwi and costs 4
strawberry and costs 8
The fruits[i] and prices[i] are ugly. The solution is to zip fruits and prices.
fruits = ['banana', 'kiwi', 'strawberry']
prices = [2, 4, 8]
for (fruit, price) in zip(fruits, prices):
print(f"{fruit} and costs {price}")
banana and costs 2
kiwi and costs 4
strawberry and costs 8
fruits = ['banana', 'kiwi', 'strawberry']
prices = [2, 4, 8, 10, 5]
for i, (fruit, price) in enumerate(zip(fruits, prices), start=1):
print(f"{i}: {fruit} and costs {price}")
1: banana and costs 2
2: kiwi and costs 4
3: strawberry and costs 8
zip(["a", "b", "c", "d"], (1, 2, 3, 4))
<zip at 0x7fda498d3b40>
list(zip(["a", "b", "c", "d"], (1, 2, 3, 4)))
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
zip(["a", "b", "c", "d"], (1, 2, 3, 4), ("alpha","beta", "gamma", "delta"))
<zip at 0x7fda498c3e40>
zip peut être défini comme ça :
def myZip(A, B):
map(lambda x, y: (x, y), A, B)
list(zip(["a", "b", "c", "d"], (1, 2, 3, 4), ("alpha","beta", "gamma", "delta")))
[('a', 1, 'alpha'), ('b', 2, 'beta'), ('c', 3, 'gamma'), ('d', 4, 'delta')]
from itertools import zip_longest
list(zip_longest(["a", "b", "c"],(1, 2, 3, 4), ("alpha","beta", "gamma", "delta"), fillvalue=0))
[('a', 1, 'alpha'), ('b', 2, 'beta'), ('c', 3, 'gamma'), (0, 4, 'delta')]
Applications: computing the weight of a path
Suppose you have a path, for instance
path = [(1, 2), (3, 5), (6, 1), (10, 0)]

from math import sqrt
def distance(A, B):
"""_summary_
Args:
A (_type_): point represented as tuples
B (_type_): _description_
Returns:
_type_: distance from A to B
"""
Ax, Ay = A
Bx, By = B
return sqrt((Ax - Bx) ** 2 + (Ay - By) ** 2)
def length(path):
result = 0
for i in range(len(path)-1):
A = path[i]
B = path[i+1]
result += distance(A, B)
return result
length([(1, 2), (3, 5), (6, 1), (10, 0)])
12.72865690108165
path = [(1, 2), (3, 5), (6, 1), (10, 0)]
for A, B in zip(path, path[1:]):
print(A, B)
(1, 2) (3, 5)
(3, 5) (6, 1)
(6, 1) (10, 0)
from math import sqrt
def segmentLength(A, B):
Ax, Ay = A
Bx, By = B
return sqrt((Ax - Bx) ** 2 + (Ay - By) ** 2)
def length(path):
return sum(segmentLength(*segment) for segment in zip(path, path[1:]))
length([(1, 2), (3, 5), (6, 1), (10, 0)])
12.72865690108165
Slices of iterable
You can get all elements of an iterable from index 2 to 6.


 ...
...
import itertools
gen = range(20)
for i in itertools.islice(gen, 2, 6):
print(i)
2
3
4
5
You can get all elements of an iterable from index 2 and then forever
...
gen = range(20)
for i in itertools.islice(gen, 2, None):
print(i)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from math import sqrt
def segmentLength(A, B):
Ax, Ay = A
Bx, By = B
return sqrt((Ax - Bx) ** 2 + (Ay - By) ** 2)
def length(path):
"""_summary_
Args:
path (_type_): should be a **list** of points
Returns:
_type_: _description_
"""
return sum(segmentLength(*segment) for segment in zip(path, itertools.islice(path, 1, None)))
length([(1, 2), (3, 5), (6, 1), (10, 0)])
12.72865690108165
Be careful!
def generatePoints():
for i in range(20):
yield (i, i)
def test(path):
for segment in zip(path, itertools.islice(path, 1, None)):
print(segment)
test(generatePoints())
((0, 0), (2, 2))
((3, 3), (4, 4))
((5, 5), (6, 6))
((7, 7), (8, 8))
((9, 9), (10, 10))
((11, 11), (12, 12))
((13, 13), (14, 14))
((15, 15), (16, 16))
((17, 17), (18, 18))
Dictionnaries
As an iterable object
A dictionary in Python is implictly an iterable object on the keys.
costs = {"banana": 2, "kiwi": 4, "straberry": 8}
for key in costs:
print(f"{key} costs {costs[key]}")
banana costs 2
kiwi costs 4
straberry costs 8
Method keys
Alternatively, the method keys on a dictionnary returns a "view" on the set of keys.
costs = {"banana": 2, "kiwi": 4, "straberry": 8}
costs.keys()
dict_keys(['banana', 'kiwi', 'straberry'])
type(costs.keys())
dict_keys
import collections
isinstance(costs.keys(), collections.abc.KeysView)
True
collections.abc.KeysView.mro()
[collections.abc.KeysView,
collections.abc.MappingView,
collections.abc.Set,
collections.abc.Collection,
collections.abc.Sized,
collections.abc.Iterable,
collections.abc.Container,
object]
The main advantage is that it is a set!
costsA = {"banana": 2, "kiwi": 4, "straberry": 8}
costsB = {"chocolate": 100, "straberry": 85, "kiwi": 41}
for k in costsA.keys() & costsB.keys():
print(k)
straberry
kiwi
isinstance(costs, collections.abc.Mapping)
True
issubclass(dict, collections.abc.Mapping)
True
dict.mro()
[dict, object]
costs = {"banana": 2, "kiwi": 4, "straberry": 8}
for key in costs.keys():
print(f"{key} costs {costs[key]}")
banana costs 2
kiwi costs 4
straberry costs 8
Method items
costs = {"banana": 2, "kiwi": 4, "straberry": 8}
for key, cost in costs.items():
print(f"{key} costs {cost}")
banana costs 2
kiwi costs 4
straberry costs 8
Modifing a dictionnary during a loop
costs = {"banana": 2, "kiwi": 4, "straberry": 8}
for key in costs:
costs[f"{key}'"] = costs[key]*2
print(costs)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[19], line 2
1 costs = {"banana": 2, "kiwi": 4, "straberry": 8}
----> 2 for key in costs:
3 costs[f"{key}'"] = costs[key]*2
5 print(costs)
RuntimeError: dictionary changed size during iteration
costs = {"banana": 2, "kiwi": 4, "straberry": 8}
for key in list(costs):
costs[f"super{key}'"] = costs[key]*2
print(costs)
{'banana': 2, 'kiwi': 4, 'straberry': 8, "superbanana'": 4, "superkiwi'": 8, "superstraberry'": 16}
Counting
import itertools
itertools.count(start=10, step=2)
count(10, 2)
Cycle
...
import itertools
n = 0
for i in itertools.cycle(["player1", "player2", "player3"]):
if n > 10:
break
print(i)
n += 1
player1
player2
player3
player1
player2
player3
player1
player2
player3
player1
player2
import itertools
itertools.repeat("X", 4)
Permutations
itertools.permutations(ITERABLE, k) returns an iterable object that enumerates all k-length tuples which are all possible orderings with no-repeated elements.
import itertools
list(itertools.permutations(range(4), 2))
[(0, 1),
(0, 2),
(0, 3),
(1, 0),
(1, 2),
(1, 3),
(2, 0),
(2, 1),
(2, 3),
(3, 0),
(3, 1),
(3, 2)]
import itertools
list(itertools.permutations(range(4), 4))
[(0, 1, 2, 3),
(0, 1, 3, 2),
(0, 2, 1, 3),
(0, 2, 3, 1),
(0, 3, 1, 2),
(0, 3, 2, 1),
(1, 0, 2, 3),
(1, 0, 3, 2),
(1, 2, 0, 3),
(1, 2, 3, 0),
(1, 3, 0, 2),
(1, 3, 2, 0),
(2, 0, 1, 3),
(2, 0, 3, 1),
(2, 1, 0, 3),
(2, 1, 3, 0),
(2, 3, 0, 1),
(2, 3, 1, 0),
(3, 0, 1, 2),
(3, 0, 2, 1),
(3, 1, 0, 2),
(3, 1, 2, 0),
(3, 2, 0, 1),
(3, 2, 1, 0)]
The following program computes all $n \times n$ chess configurations of $n$ non-attacking queens.
from itertools import permutations
"""
We represent a board of n-queens by an array board such that
board[r] is the column index such that there is a queen at row r and column board[r]
"""
def printBoard(board):
"""
print a board in the terminal
"""
n = len(board)
print('_' * (n+2))
for r in board:
print('|' + (' ' * r) + '♛' + (' ' * (n-r-1)) + '|')
print('\n')
def nqueenboards(n):
"""
A generator that generates all configurations of non-attacking n queens on a n*n boards
"""
columns = range(n)
for board in permutations(columns):
numsDiagonalNWSE = set(board[i] + i for i in columns) # à vériier
numsDiagonalNESW = set(board[i] - i for i in columns)
if n == len(numsDiagonalNWSE) == len(numsDiagonalNESW):
yield board
def printAllBoards(N):
for board in nqueenboards(N):
printBoard(board)
printAllBoards(4)
______
| ♛ |
| ♛|
|♛ |
| ♛ |
______
| ♛ |
|♛ |
| ♛|
| ♛ |
Cartesian product
import itertools
list(itertools.product(["a", "b", "c"], [1, 2, 3, 4]))
[('a', 1),
('a', 2),
('a', 3),
('a', 4),
('b', 1),
('b', 2),
('b', 3),
('b', 4),
('c', 1),
('c', 2),
('c', 3),
('c', 4)]
Python object model
Everything is an object
In many languages, and also Python, everything is an instance of the class object. None is an object, a number is an object, a function is an object etc. In other words, we have a superclass called object and any class (implicitely) inherits from that superclass object.
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([(X,'object') for X in ["NoneType", "numbers.Number", "types.FunctionType"]])
dot

- In Java, also every class is a subclass of
Java.lang.Object. However, a class, e.g.Animalitself is not an object butAnimal.classis and inherits fromjava.lang.Class. - In Python, the class
Animalitself is an object too. - In C++, there is no superclass.
dir(object)
['__class__',
'__delattr__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__lt__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__']
type(1)
int
type(int)
type
True
Number class hierarchy in Python
Here is the class hierarchy for the numbers in Python. See https://peps.python.org/pep-3141/ where you may read the rejected alternatives.
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([('Complex', 'Number'), ('complex', 'Complex'), ('Real', 'Complex'), ('float', 'Real'), ('Rational', 'Real'), ('Integral', 'Rational'), ('int', 'Integral'), ('bool', 'int')])
dot

from numbers import Complex
dir(Complex)
['__abs__',
'__abstractmethods__',
'__add__',
'__bool__',
'__class__',
'__complex__',
'__delattr__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__lt__',
'__module__',
'__mul__',
'__ne__',
'__neg__',
'__new__',
'__pos__',
'__pow__',
'__radd__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__rmul__',
'__rpow__',
'__rsub__',
'__rtruediv__',
'__setattr__',
'__sizeof__',
'__slots__',
'__str__',
'__sub__',
'__subclasshook__',
'__truediv__',
'_abc_impl',
'conjugate',
'imag',
'real']
import numbers
isinstance(5, numbers.Number)
True
Class hierarchy for Collections in Python
Here is the class hierarchy for collections in Python.
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("Collection", "Container"),
("Collection", "Iterable"),
("Collection", "Sized"),
("Sequence", "Collection"),
("Set", "Collection"),
("Mapping", "Collection"),
("MutableSequence", "Sequence"),
("MutableSet", "Set"),
("MutableMapping", "Mapping"),
("tuple", "Sequence"),
("str", "Sequence"),
("bytes", "Sequence"),
("list", "MutableSequence"),
("bytearray", "MutableSequence"),
("frozenset", "Set"),
("set", "MutableSet"),
("dict", "MutableMapping")])
dot

In Java, https://docs.oracle.com/javase/8/docs/api/java/lang/package-tree.html
from collections import Sized
dir(Sized)
/tmp/ipykernel_646363/3389889515.py:1: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.10 it will stop working
from collections import Sized
['__abstractmethods__',
'__class__',
'__delattr__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__len__',
'__lt__',
'__module__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__slots__',
'__str__',
'__subclasshook__',
'_abc_impl']
class Farm:
def __len__(self):
return 4
f = Farm()
len(f)
4
from collections import Sized
class Farm(Sized):
def __len__(self):
return 4
f: Sized = Farm()
len(f)
4
Type annotation in Python
Principle
In Python, you can annotate your code with type annotation. For instance, we can say that variable a is an integer:
a: int = 5
In Python, type checking is decorrelated from the execution. So the following program works:
a: str = 5
You are free to leave variable unanotated.
a: str = "aze"
b = 1
Gradual typing
- C, Java, have static typing.
- Python, Javascript have dynamic typing.
- Python has type anotations. You can annotate only a part of your program. This is called gradual typing. It leverages desirable aspects of both dynamic and static typing.
Javascript and Typescript
The situation is a bit close to Typescript which is Javascript with type annotations.
Declaring constants
A variable is... by definition variable. You can change its value (note that you can change it in Python even if its value is immutable).
To make a constant, we can use the type Final[...].
from typing import Final
a: Final[int] = 2
a = 1 # wrong
from typing import Final
lst: Final[list] = [2]
lst.append(3) # ok
lst = [3] # wrong
This is close to:
constin C, Javascriptfinalin Java- variable without the keyword
mutin Rust
| In Python | In C |
|---|---|
x: mutabletype = .... | type * x = ... |
x: immutabletype = .... | const type * x = ... |
x: Final[mutabletype] = .... | type * const x = ... |
x: Final[immutabletype] = .... | const type * const x = ... |
Any
Any is the type of anything in Python.
A: any = 2
- In Typescript, it is also
any - In Pascal, we had
Variantbut it is a bit different.
Parameterized types
A list of what? A tuple of what? A list of integers is list[int].
L: list[int] = [1, 2, 3]
D: dict[str, int] = {"aze": 2, "a": 1}
Veryfing types
Just run:
mypy mypythonprogram.py
Properties/methods on a class
Class variable
A class variable is a field/attribute of a class. The value is for the class itself, but can also be accessed via objects. This is called static field in JAVA/C++, but it is almost the same.
However, it can be modified from an object and the value is for that partcular object only. If modified for the class, then it is modified for the class (of course) but also for the objects of that class.
class Animal:
nbLegs = 4
a = Animal()
b = Animal()
print(a.nbLegs, b.nbLegs, Animal.nbLegs)
Animal.nbLegs = 5
print(a.nbLegs, b.nbLegs, Animal.nbLegs)
a.nbLegs = 4
print(a.nbLegs, b.nbLegs, Animal.nbLegs)
Animal.nbLegs = 3
print(a.nbLegs, b.nbLegs, Animal.nbLegs)
4 4 4
5 5 5
4 5 5
4 3 3
class Animal:
def __init__(self):
self.nbLegs = 4
a = Animal()
print(a.nbLegs)
Animal.nbLegs
4
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[5], line 7
5 a = Animal()
6 print(a.nbLegs)
----> 7 Animal.nbLegs
AttributeError: type object 'Animal' has no attribute 'nbLegs'
Quiz
What is the answer of that program?
class A:
list = []
a = A()
b = A()
a.list.append(1)
b.list
[1]
class A:
def __init__(self):
self.list = []
a = A()
b = A()
a.list.append(1)
b.list
[]
Static methods
Static methods are functions declared inside a class. They behave like functions (no special pameters like self). This is usually used group functions under a class name. It used for utilility functions.
class Calculator:
@staticmethod
def sum(x, y):
return x + y
Calculator.sum(1, 2)
3
class Animal:
nbLegs = 4
@staticmethod
def nbLegsForHello(proportion):
return Animal.nbLegs * proportion
def speak(self):
print(f"I have {self.nbLegsForHello(2)}")
print(Animal.nbLegsForHello(0.5))
a = Animal()
print(a.nbLegsForHello(0.5))
a.speak()
2.0
2.0
I have 8
Class methods
A class method is a method that is attached to the class and takes the class itself as the first argument. Usually, they are used for providing alternative constructors.
class Cat():
def __init__(self, catAge):
self.age = catAge
@classmethod
def createByEqHumanAge(cls, humanAge):
return cls(humanAge / 7)
garfield = Cat.createByEqHumanAge(21)
garfield.age
3.0
Class methods have nice behavior when inheritance is involved.
class Cat():
def __init__(self, catAge):
self.age = catAge
def speak(self):
print("classical miaou")
@classmethod
def createByEqHumanAge(cls, humanAge):
print(cls)
return cls(humanAge / 7)
class AngoraCat(Cat):
def __init__(self, catAge):
print("feu d'artifice")
self.age = catAge
def speak(self):
print("mIaOu")
a = AngoraCat.createByEqHumanAge(21)
print(a.age)
a.speak()
<class '__main__.AngoraCat'>
feu d'artifice
3.0
mIaOu
type
Threads
Qu'est ce que c'est ?
Jusqu'à présent, le programme était séquentiel (bon avec raylib c'était faux mais vous ne le saviez pas !).

Avec des threads, on est plusieurs à calculer. Chaque personne est un thread, par exemple, l'un est le thread principal et un thread secondaire que l'on a créé :

Le tas est partagé par tous les threads. Mais chaque thread possède sa propre pile d'appel, et bien sûr son propre program counter.
Motivation
Pourquoi utiliser plusieurs threads ?
- Pour accélérer un calcul sur des architectures multi-coeurs
- Pour lancer un calcul compliqué alors que l'interface graphique fonctionne encore
- En JAVA, un thread ramasse-miettes, qui nettoie la mémoire (En Python, c'est en discussion https://peps.python.org/pep-0556/)
Librairie POSIX
Depuis C11, la gestion des threads est possible avec la librairie standard. Avant C11, on utilisait toujours des librairies spécifiques à une plate-forme. Là, on va faire comme dans le temps... on va utiliser la librairie de la norme POSIX qui s'appelle pthread. En effet :
- au moins on est sûr que ça même avec des anciennes versions de C sous Unix.
- La librairie standard n'est pas franchement différente.
pthreadest au programme de l'agrégation d'informatique.
#include <pthread.h>
Pour compiler il faut dire au compilateur d'utiliser la librairie pthread :
gcc -lpthread programme.c
Autrement dit, on effectue une liaison statique avec la librarie pthread.
Principe
But
Disons que l'on a une fonction
/**
@brief faire la plonge
**/
void faireLaVaisselle() {
...
}
que l'on aimerait déléguer.
Création d'une variante avec pointeurs
/**
@brief faire la plonge
**/
void* faireLaVaissellePourThread() {
faireLaVaisselle();
return NULL;
}
En fait, la communication avec l'extérieur (valeur de retour, et arguments) sont des pointeurs sur des données dans le tas.
Création du thread
Pour cela, on écrit :
pthread_t mon_thread;
int ok = pthread_create(&mon_thread, NULL, faireLaVaissellePourThread, NULL);
- La fonction
pthread_createplace l'identifiant du thread créé dansmon_thread. C'est pourquoi on passe l'adresse demon_thread. Le typepthread_test opaque : ce n'est pas important de ce que c'est vraiment. - Le deuxième paramètre est subtil et dans ce cours, on laisse à
NULL. - Le troisième paramètre est la fonction
fque le thread doit exécuter. - Le dernier paramètre est un pointeur sur les paramètres de la fonction
f.
La fonction renvoie :
- ✅
ok == 0si tout s'est bien passé, on a réussi à créer un thread qui fait la vaisselle. - ❌ Sinon, la fonction renvoie un code d'erreur car une erreur s'est produite : par exemple il n'y a pas assez de ressources, ou autre (voir doc pour la liste de tous les problèmes possibles).
Pendant que notre thread fait la vaisselle, nous, thread principal, on peut faire autre chose, comme passer la serpière.

- Est-ce que chaque thread a sa pile d'appel ?
Oui, encore heureux car la fonction faireLaVaissellePourThreaddoit pouvoir appeler d'autres fonctions etc.
Attendre un thread
Voici comment faire pour attendre que le thread mon_thread termine :
int ok = pthread_join(mon_thread, NULL);
La fonction pthread_join renvoie :
- ✅
ok == 0si tout va bien. - ❌ Mais autre chose en cas d'erreur :
- pas de thread qui s'appelle
mon_thread(i.e. le contenu demon_threadne désigne pas un thread) - le
mon_threada déjà été attendu - il y a deadlocks (i.e. les threads sont bloqués... on verra ça plus tard)
- pas de thread qui s'appelle
Création d'un thread avec un paramètre
Voici une fonction :
/**
@brief ajoute nbCrepes crêpes sur l'assiette.
@param nbCrepes
@param isRhum
*/
void preparerCrepes(int nbCrepes) {
...
}
On aimerait maintenant déléguer la tâche
preparerCrepes(10);
à un autre thread.
Passage des paramètres
Heureusement, la bibliothèque pthread est générique. La fonction de création de threads ne dépend pas du type des paramètres. D'où l'utilisation de void* (pointeur sur n'importe quoi).
On crée une fonction pour la lecture du paramètre :
void* preparerCrepesPourThread(void* p) {
preparerCrepes(*(int*) p);
return NULL;
}
où (int*) convertit ("caste") p en un pointeur sur entier. Puis l'étoile à gauche * permet d'accéder à cet entier, que l'on donne en argument à preparerCrepes.
Puis :
pthread_t mon_thread;
int *p = malloc(sizeof(int));
if(p == NULL) exit(EXIT_FAILURE);
*p = 10;
int ok = pthread_create(&mon_thread, NULL, (void*) preparerCrepesPourThread, p);
Exercices
- Que pensez-vous de la fonction suivante :
void creerThreadCrepes() {
pthread_t mon_thread;
int *p = malloc(sizeof(int));
if(p == NULL) exit(EXIT_FAILURE);
*p = 10;
int ok = pthread_create(&mon_thread, NULL, (void*) preparerCrepesPourThread, p);
}
mon_thread est perdue une fois que la fonction creerThreadCrepes est terminée.
- Que pensez-vous de la fonction suivante :
void creerThreadCrepes(pthread_t* p_mon_thread) {
int *p = malloc(sizeof(int));
if(p == NULL) exit(EXIT_FAILURE);
*p = 10;
int ok = pthread_create(p_mon_thread, NULL, (void*) preparerCrepesPourThread, p);
}
- Que pensez-vous de la fonction suivante :
void creerThreadCrepes(pthread_t* p_mon_thread) {
int i = 10;
int ok = pthread_create(p_mon_thread, NULL, (void*) preparerCrepesPourThread, &i);
}
- Que pensez-vous de ce code là ?
for (size_t i = 0; i < NUM_FRIENDS; i++)
pthread_create(&friends[i], NULL, meetup, &i);
for (size_t j = 0; j < NUM_FRIENDS; j++)
pthread_join(friends[j], NULL);
Création d'un thread avec plusieurs paramètres
Ajoutons du rhum dans l'histoire. Voici une fonction qui prend deux paramètres :
/**
@brief ajoute nbCrepes crêpes sur l'assiette.
On utilise la pâte avec du rhum ssi isRhum est vrai.
@param nbCrepes
@param isRhum
*/
void preparerCrepes(int nbCrepes, bool isRhum) {
...
}
On aimerait maintenant déléguer la tâche
preparerCrepes(10, true);
à un autre thread.
Passage des paramètres
- Comment pour passer plusieurs arguments à une tâche à sous-traiter à un thread alors que
pthread_createne prend qu'un seul argument pour ces arguments justement ?
struct pour représenter les paramètres. Démonstration !
Premièrement on définit le struct pour grouper les arguments.
/**
* @brief the struct that groups the parameters of preparerCrepes together
*/
struct mon_thread_args
{
int nbCrepes;
bool isRhum;
};
Ensuite, on écrit la fonction qui s'occupe de rediriger vers notre fonction existante :
void *preparerCrepesPourThread(void *pointeurArguments)
{
struct mon_thread_args *p = pointeurArguments;
preparerCrepes(p->nbCrepes, p->isRhum);
}
Puis on délègue la préparation des crêpes en créant un thread :
pthread_t mon_thread;
struct mon_thread_args *p = malloc(sizeof(*p));
if(p == NULL)
exit(EXIT_FAILURE);
p->nbCrepes = 12230;
p->isRhum = true;
pthread_create(&mon_thread, NULL, preparerCrepesPourThread, p);
Valeur de retour d'un thread
Nous n'allons pas utilisé cela... mais si jamais vous voulez utiliser la valeur de retour de la fonction faireVaisselle, on procède comme suit. La valeur de retour doit être dans le tas car il faudra la communiquer au thread principal. On alloue la mémoire dans faireVaisselle.
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
void *faireVaisselle(void *arg) {
int *pResult = malloc(sizeof(int));
*pResult = 42;
return pResult;
}
int main() {
pthread_t thread;
int *pResult;
pthread_create(&thread, NULL, faireVaisselle, NULL);
pthread_join(thread, (void **)&pResult);
printf("Result: %d\n", *pResult);
free(pResult);
}
Dans le thread principal (ici la fonction main), on récupère la valeur de retour dans l'attente du thread.
Application : accélérer l'affichage de l'ensemble de Mandelbrot
Problème de l'affichage de l'ensemble de Mandelbrot
On présente ici le problème d'afficher une comme celle-là.

- Est-ce que vous savez ce que représente cette image ?
La couleur d'un pixel est donnée par :
/**
* \fn Color computeColor(complex z)
* \param z a complex
* \return the color that should be displayed at z
*/
Color computeColor(complex z)
{
complex u = 0;
for (int i = 0; i < NBINTER; i++)
{
u = u*u + z;
if (cabs(u) > 2)
return ColorFromHSV(i * 255 / NBINTER, 1.0, 1.0);
}
return BLACK;
}
Un programme mono-thread est lent ; le déplacement et le zoom dans la fractale râme (on peut aussi se souvenir de la portion de l'image commune entre une frame et une autre, mais là pas besoin de thread donc on n'aborde pas ça ici). Pour cela, on se propose ici deux solutions qui utilisent des threads.
Découpe du problème : fork and join
Voici la première solution. Au lieu de dessiner l'image en entier, on découpe l'image en zone et chaque thread va calculer sa zone.
- On démarre les calculs des 4 zones
- Puis on attend que les calculs soient finis
C'est le principe du fork and join.
- Est-ce que vous voyez des qualités à cette approche ?
- Est-ce que vous voyez un défaut à cette approche ?
File de tâches
On considère un bassin de threads (thread pool). Chaque thread vient se servir d'une tâche à effectuer dans une file et s'arrête quand la file est vide.
- Est-ce que vous voyez des qualités à cette approche ?
- Est-ce que vous voyez un défaut à cette approche ?
Canaux
Il existe des architectures de threads qui ressemblent aux pipes. On ne va pas aborder ça ici.
Problème de concurrence
Deux personnes ensemble ne savent pas compter
- Qu'écrit ce programme ?
#include <stdio.h>
#include <pthread.h>
int x = 0;
void* f(void*) {
for(int i = 0; i<50000; i++)
x++;
}
int main()
{
pthread_t t1, t2;
pthread_create(&t1, NULL, f, NULL);
pthread_create(&t2, NULL, f, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("%d",x);
return 0;
}
- Est-ce toujours une valeur inférieure à la valeur attendue ?
On parle de race condition (Situation de compétition, situation de concurrence).
Solution : les mutex
Un mutex (pour Mutual exclusion, Exclusion mutuelle) est une sorte de loquet/verrou. On déclare un mutex comme ça :
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, NULL);
On donne l'adresse du mutex pour que pthread_mutex_init puisse y inscrire l'ID. Le paramètre NULL c'est pour des choses plus compliquées.
On verouille ou déverouille comme ça :
pthread_mutex_lock(&mutex);
...
pthread_mutex_unlock(&mutex);
Le morceau de programme entre le verrouillage du mutex et son déverouillage s'appelle la section critique.



-
En image
pthread_mutex_lock(&m42);, c'est une porte labélisém42, ouverte par défaut, suivi d'une dalle/bouton qui ferme toutes les portes de typem42. -
En image,
pthread_mutex_unlock(&m42);, est une dalle qui ouvre les portes de typem42.
A la fin, on détruit le mutex :
pthread_mutex_destroy(&mutex);
Exemple
#include <stdio.h>
#include <pthread.h>
pthread_mutex_t mutex;
int x = 0;
void* f(void*) {
for(int i = 0; i<50000; i++) {
pthread_mutex_lock(&mutex);
x++;
pthread_mutex_unlock(&mutex);
}
}
int main()
{
pthread_t t1, t2;
pthread_mutex_init(&mutex, NULL);
pthread_create(&t1, NULL, f, NULL);
pthread_create(&t2, NULL, f, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
pthread_mutex_destroy(&mutex);
printf("%d",x);
return 0;
}
Deadlocks
Des fois, avec des mutex, on peut arriver à des situations bloquantes. Comme :
| Thread 1 |
|---|
| lock(mutex) |
| lock(mutex) |
| ... |
ou
| Thread 1 | Thread 2 |
|---|---|
| lock(mutex1) | lock(mutex2) |
| lock(mutex2) | lock(mutex1) |
| ... | ... |
Exercices
- Multiplication de matrices
- Tri fusion et autres
- FFT
Références
Programmer avec Rust. Jim Blandy et Jason Orendorff. (même si on fait du C et pas du Rust, le principe des threads est bien expliqué dans ce livre, avec l'exemple de la fractale de Mandelbrot et les différentes méthodes)
Gestion d'erreurs en C
Exemples d'erreurs
Fichiers
FILE *file;
file = fopen("tilemap.txt", "r");
if (file == NULL) {
//quelle erreur
return -1; // ou exit(-1)
}
Avec un fichier on peut savoir un stream est dans un état d'erreur avec :
int ferror( FILE * stream );
qui renvoie en fait un booléen.
Problème de réseau
Cf. cours au 1er semestre
Problème de chargement d'une librairie dynamique
Numéro d'erreurs
Quand il y a une erreur dans une fonction, on a un accès un numéro d'erreurs avec la variable globale errno disponible avec #include <errno.h>.
errno == 0: pas de soucis ✅errno != 0: il y a eu un problème ❌
Message d'erreur
Aussi, la fonction
char * strerror ( int errCode );
affiche le message d'erreur textuel compréhensible par un humain correspondant à l'erreur. La fonction strerror est disponible via #include <string.h>. Typiquement, on appelle :
puts(strerror(errno));
⚠ On ne libère pas la mémoire de la chaîne de caractères d'erreur : free(strerror(errno));
- D'après vous pourquoi on ne libère pas la mémoire d'une chaîne de caractères renvoyés par
strerror?
Informer l'utilisateur sur la sortie d'erreur
void perror( const char * prefix );
Elle affiche un message d'erreur sur stderr. Comme stdin et stdout qui sont respectivement les flux standards pour l'entrée et la sortie, stderr est le flux standard pour les erreurs. stderr est généralement redirigé vers la console, comme stdout.
Utilisation mot-clé goto
https://github.com/openbsd/src/blob/master/sys/dev/ata/wd.c
setjmp et longjmp
Devoir gérer les erreurs en cas d'imbrication de fonctions est fastidieux.

En Java, Python, C++, et autres,on a des exceptions pour gérer les erreurs. En C, non, mais il y a setjmp et longjmp de <setjmp.h>.
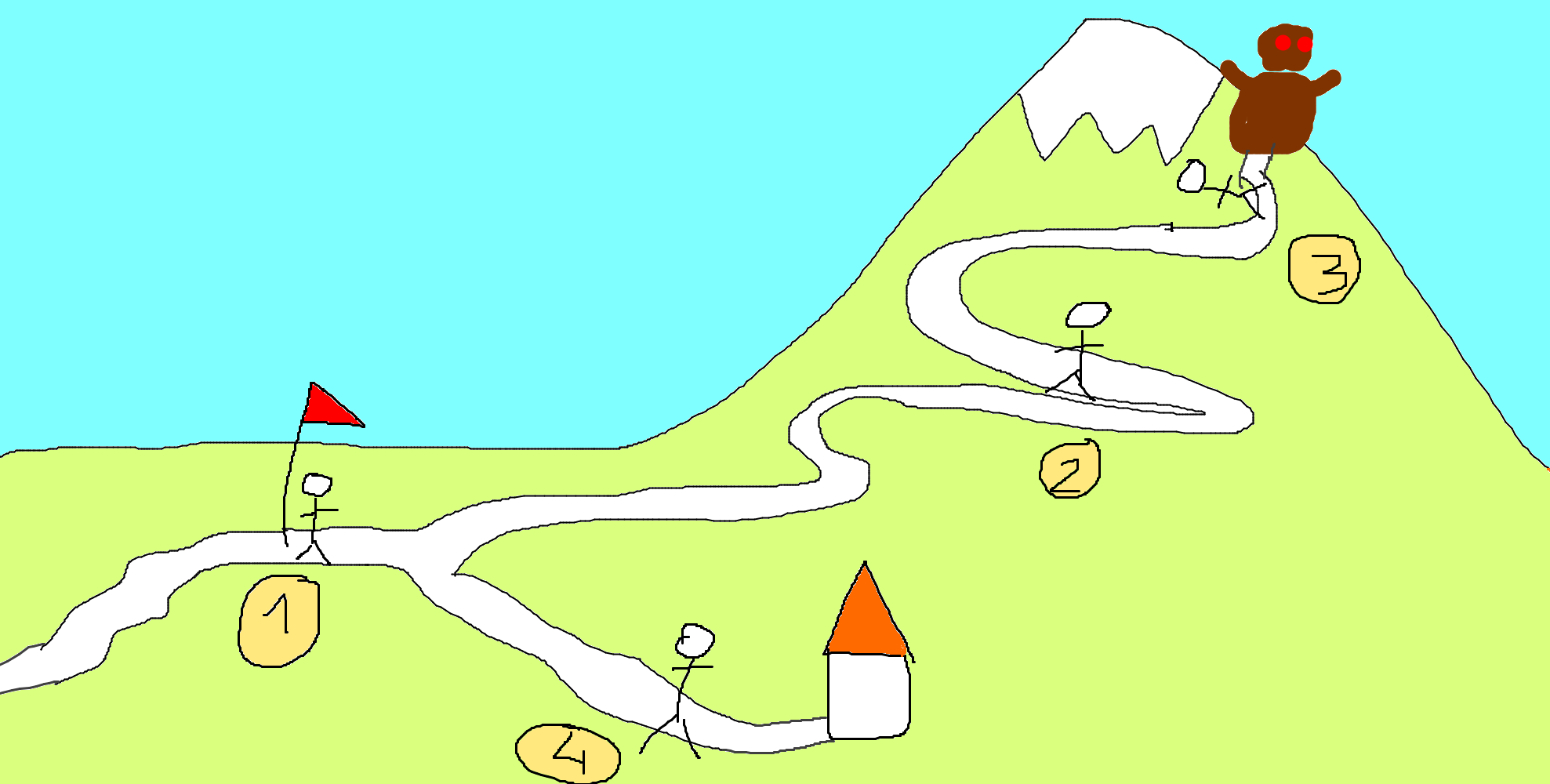
- Tu poses un jalon pour y revenir plus tard
- Tu exécutes des choses (chargement d'un gros fichier par exemple)
- Tu tombes sur une erreur en croisant un ours
- Tu reviens au jalon et tu affiches un message d'erreur, tu libères la mémoire et tu reviens dans une situation stable
int setjmp(jmp_buf env);
setjmp pose un jalon 🚩. Elle écrit dans env les données relatives au contexte de la pile d'appel actuel. Cette fonction renvoie 0... sauf que...
void longjmp(jmp_buf env, int value);
longjmp renvoie au jalon avec le contexte de l'époque. On renvoie dans le code où il y avait l'appel à setjmp qui maintenant renvoie value (qui doit être différente de 0).
#include <stdio.h>
#include <setjmp.h>
static jmp_buf jmpBuffer;
void b() {
...
if(error) {
longjmp(jmpBuffer, 1);
}
}
void a() {
b();
}
void bigComputation() {
a();
}
int main() {
if (setjmp(jmpBuffer) == 0)
bigComputation();
else
printf("désolé il y a eu une erreur\n");
return EXIT_SUCCESS;
}
Exemple d'utilisation : https://sourceforge.net/p/libpng/code/ci/master/tree/example.c#l322
Exceptions

The language C does not provide any mechanism for handling errors. That is a pity because in C, we must always handle error propagation by writing functions that returns 0 in general, and a value different from 0 in case of an error. The code becomes horrible.

We also have nasty setjmp and longjmp which are dangerous!. Many languages, like C++, Python, Javascript, Java, C# etc. offer exceptions to handle errors. They work like setjmp and longjmp, but they take care about the memory.

3/0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
Cell In[1], line 1
----> 1 3/0
ZeroDivisionError: division by zero
import logging
y = 0
try:
x = 3/y
except ZeroDivisionError:
logging.error("You are crazy to try a division by zero!")
ERROR:root:You are crazy to try a division by zero!
This is particularly useful when the error occurs deep in the program.
def division(x, y):
return x/y
def f(x, y):
return division(x, y) + 1
try:
print(f(3, 0))
except ZeroDivisionError:
print("You are crazy to try a division by zero!")
You are crazy to try a division by zero!
Syntax of try-except-else-finally
try:
print("write here the code what may cause an exception")
except ZeroDivisionError:
print("write here what to do in case of a division by zero")
except AssertionError:
print("write here what to do in case of an assert condition was false")
else:
print("write here some code to execute when no error occurred")
finally:
print("write here code which is always executed (error or not)")
write here the code what may cause an exception
write here some code to execute when no error occurred
write here code which is always executed (error or not)
def f():
try:
x = 3/0
except ZeroDivisionError:
print("write here what to do in case of a division by zero")
return
except AssertionError:
print("write here what to do in case of an assert condition was false")
else:
print("write here some code to execute when no error occurred")
finally:
print("write here code which is always executed (error or not)")
f()
write here what to do in case of a division by zero
Hierarchy of exceptions
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("Exception", "BaseException"),
("KeyboardInterrupt", "BaseException"),
("SystemExit", "BaseException"),
("ZeroDivisionError", "Exception"),
("AssertionError", "Exception"),
("ValueError", "Exception"),
])
dot

try:
3/0
except BaseException:
print("All base exceptions are handled")
NEVER catch a BaseException. The program should STOP in that case
All exceptions are BaseException. Normally, you do not catch KeyboardInterrupt, SystemExit because you prevent your program from stopping if the user wants so!
The following code is bad:
try:
print("my program")
except BaseException:
print("NEVER catch a BaseException. The program should STOP in that case")
try:
print("my program")
except KeyboardInterrupt:
print("NEVER catch a BaseException. The program should STOP in that case")
However, you can catch exceptions that inherits from Exception
User-defined exceptions
You can define your own type of exceptions.
class DenominatorZeroError(Exception):
pass
def f(x,y):
if y == 0:
raise DenominatorZeroError
return x/y
try:
d = f(3, 0)
except DenominatorZeroError:
print("Denominator should be non-zero!")
Denominator should be non-zero!
class DenominatorZeroError(Exception):
pass
def g(x):
return DenominatorZeroError if x == 0 else ValueError
def f(x,y):
if y == 0:
raise g(0)
return x/y
try:
d = f(3, 0)
except DenominatorZeroError:
print("Denominator should be non-zero!")
Denominator should be non-zero!
class OddNumberOfVertexError(Exception):
def __init__(self, nbVertices):
super().__init__(f"should give a graph with an even number of vertices: {nbVertices} given")
def computePerfectMatching(G):
if G["nbVertices"] % 2 != 0:
raise OddNumberOfVertexError(G["nbVertices"])
try:
computePerfectMatching({"nbVertices": 3})
except OddNumberOfVertexError as e:
print(e)
should give a graph with an even number of vertices: 3 given
Ressource management
Bad practice
In Python, it is highly not-recommended to write:
for line in open('example.txt'): # bad
...
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[14], line 1
----> 1 for line in open('example.txt'): # bad
2 ...
File /usr/local/lib/python3.9/site-packages/IPython/core/interactiveshell.py:310, in _modified_open(file, *args, **kwargs)
303 if file in {0, 1, 2}:
304 raise ValueError(
305 f"IPython won't let you open fd={file} by default "
306 "as it is likely to crash IPython. If you know what you are doing, "
307 "you can use builtins' open."
308 )
--> 310 return io_open(file, *args, **kwargs)
FileNotFoundError: [Errno 2] No such file or directory: 'example.txt'
The issue is that... we do not close the file! Also do not write (even many websites say it):
f = open("example.txt")
print(file.read())
file.close()
In case of an error in the treatment, the file may not be closed.
Solution
Instead we should a construction which has the following form:
file = EXPR
file.__enter__()
try:
BLOCK
finally:
file.__exit__()
This is cumbersome. So thanks to https://peps.python.org/pep-0343/ we have a with-as construction:
with EXPR as file:
BLOCK
with open('example.txt') as file:
content = file.read()
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[1], line 1
----> 1 with open('example.txt') as file:
2 content = file.read()
File /usr/local/lib/python3.9/site-packages/IPython/core/interactiveshell.py:310, in _modified_open(file, *args, **kwargs)
303 if file in {0, 1, 2}:
304 raise ValueError(
305 f"IPython won't let you open fd={file} by default "
306 "as it is likely to crash IPython. If you know what you are doing, "
307 "you can use builtins' open."
308 )
--> 310 return io_open(file, *args, **kwargs)
FileNotFoundError: [Errno 2] No such file or directory: 'example.txt'
We can also use several ressources as follows.
with open('input.txt') as fInput, open("output.txt", "w") as fOutput:
for line in fInput:
fOutput.write(line)
Thread en Python
import threading
import time
# Fonction que le thread va exécuter
def afficher_message(nom: str, delai: int):
for i in range(3):
print(f"[{nom}] Message {i+1}")
time.sleep(delai)
print(f"[{nom}] Terminé !")
# Création d’un thread avec des arguments
thread1 = threading.Thread(target=afficher_message, args=("Thread-1", 1))
thread2 = threading.Thread(target=afficher_message, args=("Thread-2", 2))
# Lancement des threads
thread1.start()
thread2.start()
# Attendre la fin des threads
thread1.join()
thread2.join()
print("Tous les threads sont terminés.")
[Thread-1] Message 1
[Thread-2] Message 1
[Thread-1] Message 2
[Thread-1] Message 3
[Thread-2] Message 2
[Thread-1] Terminé !
[Thread-2] Message 3
[Thread-2] Terminé !
Tous les threads sont terminés.
Code plus "objet"
import threading
import time
class MonThread(threading.Thread):
def __init__(self, nom: str, delai: int):
super().__init__()
self.nom = nom
self.delai = delai
def run(self):
"""Méthode exécutée automatiquement quand on lance le thread avec start()."""
for i in range(3):
print(f"[{self.nom}] Message {i+1}")
time.sleep(self.delai)
print(f"[{self.nom}] Terminé !")
# Création des threads
t1 = MonThread("Thread-1", 1)
t2 = MonThread("Thread-2", 2)
# Démarrage des threads
t1.start()
t2.start()
# Attente de leur fin
t1.join()
t2.join()
print("Tous les threads sont terminés.")
Tous les threads sont terminés.
Verrou
import threading
import time
# Compteur partagé entre threads
compteur = 0
# Création d’un verrou
verrou = threading.Lock()
class CompteurThread(threading.Thread):
def __init__(self, nom: str, iterations: int):
super().__init__()
self.nom = nom
self.iterations = iterations
def run(self):
global compteur
for _ in range(self.iterations):
# On verrouille la section critique
with verrou:
valeur_temp = compteur
valeur_temp += 1
# Simulation d’un traitement
time.sleep(0.001)
compteur = valeur_temp
# On sort du "with", donc le verrou est libéré automatiquement
print(f"{self.nom} terminé.")
# Création de plusieurs threads
threads = [CompteurThread(f"Thread-{i+1}", 1000) for i in range(5)]
# Lancement des threads
for t in threads:
t.start()
# Attente de la fin
for t in threads:
t.join()
print(f"Valeur finale du compteur : {compteur}")
Thread-3 terminé.
Thread-4 terminé.
Thread-5 terminé.
Valeur finale du compteur : 5000
Await/async
Les mots-clés await et async voient le jour dans ce papier :
Syme, Don; Petricek, Tomas; Lomov, Dmitry (2011). "The F# Asynchronous Programming Model". Practical Aspects of Declarative Languages. Lecture Notes in Computer Science. Vol. 6539. Springer Link. pp. 175–189.
Depuis, il a été ajouté dans plein de langages : C#, Python, Typescript, Javascript, Rust, C++, etc.
En Python
import asyncio
# Asynchronous function to simulate a task
async def task(name):
await asyncio.sleep(0.01)
return f"Task {name} Completed"
# Main function to run multiple tasks concurrently
async def main():
tasks = [task(1), task(2), task(3)]
results = await asyncio.gather(*tasks) # Run all tasks concurrently and wait for them
for result in results:
print(result)
# Run the main function
asyncio.run(main())
async def f():
return 2
await f()
JavaScript
En JavaScript, await et async cache un système de promesses. Une promesse est un objet qui attend qu'une opération (asynchrone) se fasse, puis... soit elle réussit et on obtient une valeur de retour, soit il y a un échec.
function faireQqc() {
return new Promise((successCallback, failureCallback) => {
console.log("C'est fait");
// réussir une fois sur deux
if (Math.random() > 0.5) {
successCallback("Réussite");
} else {
failureCallback("Échec");
}
});
}
const promise = faireQqc();
promise.then(successCallback, failureCallback);
faireQqc()
.then((result) => faireAutreChose(result))
.then((newResult) => faireUnTroisiemeTruc(newResult))
.then((finalResult) => console.log("Résultat final : " + finalResult))
.catch(failureCallback);
try {
const result = syncFaireQqc();
const newResult = syncFaireQqcAutre(result);
const finalResult = syncFaireUnTroisiemeTruc(newResult);
console.log("Résultat final : " + finalResult);
} catch (error) {
failureCallback(error);
}
async function toto() {
try {
const result = await faireQqc();
const newResult = await faireQqcAutre(result);
const finalResult = await faireUnTroisiemeTruc(newResult);
console.log("Résultat final : " + finalResult);
} catch (error) {
failureCallback(error);
}
}
Thread en Go
Le langage Go est spécial car il implémente les threads et la communication par canaux dans le langage.
Goroutine
En Go, les threads sont implémenté comme des goroutines. Au lieu de lancer :
f(x)
On écrit :
go f(x)
Ca crée un nouveau thread qui exécute f(x) !
Communication
La communication entre threads s'effectue avec des canaux.
Pour déclarer un canal ch :
ch := make(chan int)
Pour y placer une valeur v :
ch <- v
Pour lire la prochaine valeur dans un canal ch :
v := <-ch
Model checking
Le model checking est une technique de vérification de programmes. Le problème de model checking est comme suit :
- entrée
- un programme
- une spécification qui décrit le comportement attendu du programme
- sortie :
- une attestation que le programme vérifie la spécification, ou alors une exécution contre-exemple qui montre que le programme ne fonctionne pas bien.
Généralement, le model checking est utilisé sur des systèmes réactifs simples (des systèmes de transition qui ressemblent à des automates finis) et des propriétés temporelles (e.g. "une infinité de fois, x prend la valeur 0). Ici, on s'intéresse à faire du model checking sur des programmes C, avec l'outil efficient SMT-based context-bounded model checker (EBSMC, disponible ici https://github.com/esbmc/esbmc). SMT signifie satisfiability modulo theory, vous allez voir partiellement en cours de logique, ou alors dans un cours de vérification formelle en M1 ou M2, ou jamais.
La documentation est là : http://esbmc.org/
Comment écrire la spécification
Deux solutions :
assert(x == 10)pour dire qu'icixdoit valoir 10__VERIFIER_assume(x < 5);pour dire que l'on suppose quex < 5
Ainsi un code comme cela :
int main() {
int x;
__VERIFIER_assume(x < 5);
// calcul sur x
assert(x == 10)
}
signifie que la spécification est *si x < 5 au début, alors x == 10 à la fin.
Utilisation
esbmc programme.c
Il y a aussi des flags pour contrôler la façon dont fonctionne le model checker :
esbmc programme.c --incremental-bmc
esbmc programme.c --data-races-check --context-bound 3
CPython
This document is a crash course on how the Python interpreter CPython (written in C) works. The source code is available here: https://github.com/python/cpython
Objects
In Python, every variable contains a pointer to an object. An object is a struct.
Example of a bigint
Writting the Python code
x = 5
means that internally x is a PyLongObject*, that is a pointer to a PyLongObject which stores data to manage the memory, plus the data 5.
Example of a list
Writting the Python code
L = [5, 2]
means that L is a PyListObject*, i.e. a pointer to a PyListObject.
Example of a tuple
Writting the Python code
L = (5, 2)
means that L is a pointer to a PyTupleObject.
Common data to any data in Python: PyObject
Many structs (like PyLongObject, PyListObject, etc.) actually extends the basic struct PyObject.
typedef struct _object PyObject;
It means that structs (like PyLongObject, PyListObject, etc.) always contain the data for a PyObject, stored in a field called ob_base.
/* PyObject_HEAD defines the initial segment of every PyObject. */
#define PyObject_HEAD PyObject ob_base;
struct _object {
// ob_tid stores the thread id (or zero). It is also used by the GC and the
// trashcan mechanism as a linked list pointer and by the GC to store the
// computed "gc_refs" refcount.
uintptr_t ob_tid;
uint16_t _padding;
PyMutex ob_mutex; // per-object lock
uint8_t ob_gc_bits; // gc-related state
uint32_t ob_ref_local; // local reference count
Py_ssize_t ob_ref_shared; // shared (atomic) reference count
PyTypeObject *ob_type;
};
ob_ref_localis the number of pointers pointing to the current object.
- The field
ob_typecontains the type of the current object.ob_typeis also an object of typePyTypeObjectwhich can be casted intoPyObject.
Implementation of the Python keyword is
https://github.com/python/cpython/blob/main/Include/object.h#L166
// Test if the 'x' object is the 'y' object, the same as "x is y" in Python.
PyAPI_FUNC(int) Py_Is(PyObject *x, PyObject *y);
#define Py_Is(x, y) ((x) == (y))
Big int in Python
Arbitrary big integers are represented by an object of C type PyLongObject:
https://github.com/python/cpython/blob/main/Include/pytypedefs.h#L19
typedef struct _longobject PyLongObject;
https://github.com/python/cpython/blob/main/Include/cpython/longintrepr.h
struct _longobject {
PyObject_HEAD
_PyLongValue long_value;
};
PyObject_HEADadds the necesarry fields that are common to any Python object- long_value stores the content
typedef struct _PyLongValue {
uintptr_t lv_tag; /* Number of digits, sign and flags */
digit ob_digit[1];
} _PyLongValue;
-
uintptr_test un type entier non signé qui a assez de bits pour représenter un pointeur. Il est défini dans<stdint.h> -
digitest un type de "chiffre" (généralement entre 0 et $2^{30}-1$) -
The array
ob_digitis of length 1 by default (when the user just write_PyLongValue v) and it can be of any size when the struct is allocated on the heap withmalloc(see the creation of such an object here https://github.com/python/cpython/blob/main/Objects/longobject.c#L155)
Reading lv_tag
Getting the sign
static inline bool
_PyLong_IsZero(const PyLongObject *op)
{
return (op->long_value.lv_tag & SIGN_MASK) == SIGN_ZERO;
}
static inline bool
_PyLong_IsNegative(const PyLongObject *op)
{
return (op->long_value.lv_tag & SIGN_MASK) == SIGN_NEGATIVE;
}
static inline bool
_PyLong_IsPositive(const PyLongObject *op)
{
return (op->long_value.lv_tag & SIGN_MASK) == 0;
}
Getting the number of digits
For get the number of digits, we read the field lv_tag appropriately:
https://github.com/python/cpython/blob/main/Include/internal/pycore_long.h#L227
static inline Py_ssize_t
_PyLong_DigitCount(const PyLongObject *op)
{
assert(PyLong_Check(op));
return (Py_ssize_t)(op->long_value.lv_tag >> NON_SIZE_BITS);
}
Implementation
https://github.com/python/cpython/blob/main/Objects/longobject.c
Addition
https://github.com/python/cpython/blob/main/Objects/longobject.c#L3750
static PyLongObject *
long_add(PyLongObject *a, PyLongObject *b)
{
...
}
Multiplication
https://github.com/python/cpython/blob/main/Objects/longobject.c#L4289
static PyLongObject*
long_mul(PyLongObject *a, PyLongObject *b)
{
/* fast path for single-digit multiplication */
if (_PyLong_BothAreCompact(a, b)) {
stwodigits v = medium_value(a) * medium_value(b);
return _PyLong_FromSTwoDigits(v);
}
PyLongObject *z = k_mul(a, b);
/* Negate if exactly one of the inputs is negative. */
if (!_PyLong_SameSign(a, b) && z) {
_PyLong_Negate(&z);
}
return z;
}
Type
Remember the field PyTypeObject *ob_type; of any PyObject object.
https://github.com/python/cpython/blob/main/Doc/includes/typestruct.h#L1
typedef struct _typeobject {
PyObject_VAR_HEAD
const char *tp_name; /* For printing, in format "<module>.<name>" */
Py_ssize_t tp_basicsize, tp_itemsize; /* For allocation */
/* Methods to implement standard operations */
destructor tp_dealloc;
Py_ssize_t tp_vectorcall_offset;
getattrfunc tp_getattr;
setattrfunc tp_setattr;
PyAsyncMethods *tp_as_async; /* formerly known as tp_compare (Python 2)
or tp_reserved (Python 3) */
reprfunc tp_repr;
/* Method suites for standard classes */
PyNumberMethods *tp_as_number;
PySequenceMethods *tp_as_sequence;
PyMappingMethods *tp_as_mapping;
/* More standard operations (here for binary compatibility) */
hashfunc tp_hash;
ternaryfunc tp_call;
reprfunc tp_str;
getattrofunc tp_getattro;
setattrofunc tp_setattro;
/* Functions to access object as input/output buffer */
PyBufferProcs *tp_as_buffer;
/* Flags to define presence of optional/expanded features */
unsigned long tp_flags;
const char *tp_doc; /* Documentation string */
/* Assigned meaning in release 2.0 */
/* call function for all accessible objects */
traverseproc tp_traverse;
/* delete references to contained objects */
inquiry tp_clear;
/* Assigned meaning in release 2.1 */
/* rich comparisons */
richcmpfunc tp_richcompare;
/* weak reference enabler */
Py_ssize_t tp_weaklistoffset;
/* Iterators */
getiterfunc tp_iter;
iternextfunc tp_iternext;
/* Attribute descriptor and subclassing stuff */
struct PyMethodDef *tp_methods;
struct PyMemberDef *tp_members;
struct PyGetSetDef *tp_getset;
// Strong reference on a heap type, borrowed reference on a static type
struct _typeobject *tp_base;
PyObject *tp_dict;
descrgetfunc tp_descr_get;
descrsetfunc tp_descr_set;
Py_ssize_t tp_dictoffset;
initproc tp_init;
allocfunc tp_alloc;
newfunc tp_new;
freefunc tp_free; /* Low-level free-memory routine */
inquiry tp_is_gc; /* For PyObject_IS_GC */
PyObject *tp_bases;
PyObject *tp_mro; /* method resolution order */
PyObject *tp_cache;
PyObject *tp_subclasses;
PyObject *tp_weaklist;
destructor tp_del;
/* Type attribute cache version tag. Added in version 2.6 */
unsigned int tp_version_tag;
destructor tp_finalize;
vectorcallfunc tp_vectorcall;
/* bitset of which type-watchers care about this type */
unsigned char tp_watched;
} PyTypeObject;
And here is the type of any object type: PyType_Type. It means that if t is a type, then t.ob_type == &PyType_Type.
https://github.com/python/cpython/blob/main/Objects/typeobject.c#L6294C1-L6339C3
PyTypeObject PyType_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"type", /* tp_name */
sizeof(PyHeapTypeObject), /* tp_basicsize */
sizeof(PyMemberDef), /* tp_itemsize */
type_dealloc, /* tp_dealloc */
offsetof(PyTypeObject, tp_vectorcall), /* tp_vectorcall_offset */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_as_async */
type_repr, /* tp_repr */
&type_as_number, /* tp_as_number */
0, /* tp_as_sequence */
0, /* tp_as_mapping */
0, /* tp_hash */
type_call, /* tp_call */
0, /* tp_str */
_Py_type_getattro, /* tp_getattro */
type_setattro, /* tp_setattro */
0, /* tp_as_buffer */
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_HAVE_GC |
Py_TPFLAGS_BASETYPE | Py_TPFLAGS_TYPE_SUBCLASS |
Py_TPFLAGS_HAVE_VECTORCALL |
Py_TPFLAGS_ITEMS_AT_END, /* tp_flags */
type_doc, /* tp_doc */
type_traverse, /* tp_traverse */
type_clear, /* tp_clear */
0, /* tp_richcompare */
offsetof(PyTypeObject, tp_weaklist), /* tp_weaklistoffset */
0, /* tp_iter */
0, /* tp_iternext */
type_methods, /* tp_methods */
type_members, /* tp_members */
type_getsets, /* tp_getset */
0, /* tp_base */
0, /* tp_dict */
0, /* tp_descr_get */
0, /* tp_descr_set */
offsetof(PyTypeObject, tp_dict), /* tp_dictoffset */
type_init, /* tp_init */
0, /* tp_alloc */
type_new, /* tp_new */
PyObject_GC_Del, /* tp_free */
type_is_gc, /* tp_is_gc */
.tp_vectorcall = type_vectorcall,
};
Lists
https://github.com/python/cpython/blob/main/Include/cpython/listobject.h#L22
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
* list.sort() temporarily sets allocated to -1 to detect mutations.
*
* Items must normally not be NULL, except during construction when
* the list is not yet visible outside the function that builds it.
*/
Py_ssize_t allocated;
} PyListObject;
Tuples
typedef struct {
PyObject_VAR_HEAD
/* ob_item contains space for 'ob_size' elements.
Items must normally not be NULL, except during construction when
the tuple is not yet visible outside the function that builds it. */
PyObject *ob_item[1];
} PyTupleObject;
Bindings Python and C
Goal
Our goal is to be able to call C functions from Python.
- Hello, I am a C programmer and I built a super-fast library to detect collisions between different shapes.
- Excellent! I am a Python programmer. Can I use your library?
- Sure, I also programmed bindings for it.
General idea
C code
Consider a C program:
int mysuperfunction(int x)
{
return 2 * x;
}
Compile a shared library
A shared library is a library that can be loaded dynamically (at the execution time). To do that:
gcc faslibrary.c -shared -o fastlibrary.so
In Python
import ctypes
def getFastlibrary():
fastlibrary = ctypes.CDLL("./fastlibrary.so") # load the shared library
return fastlibrary
def main():
fastlibrary = getFastlibrary()
print(fastlibrary.mysuperfunction(21)) # call to the function written in C :)
By default, ctypes assumes that functions takes int and returns int...
Primitive types
We can inform the types of the argument and of the returned value.
- The C function
mysuperfunctiontakes an int as an input:
fastlibrary.mysuperfunction.argtypes = [ctypes.c_int]
- The C function
mysuperfunctionreturns an int:
fastlibrary.mysuperfunction.argtypes = ctypes.c_int
- The C function
beautifytakes achar *an input:
fastlibrary.beautify.argtypes = [ctypes.c_char_p]
The usage is subtle:
fastlibrary.beautify.restype = ctypes.c_char_p
s = "AVEC".encode('utf-8') # in order to be able to get a char*
print(fastlibrary.beautify(s))
https://en.wikibooks.org/w/index.php?title=Python_Programming%2FExtending_with_ctypes
Structures
Declaration
For this C structure
struct Point {
int x;
int y;
};
we declare this class in Python:
class Point(ctypes.Structure):
_fields_ = (
("x", ctypes.c_int),
("y", ctypes.c_int),
)
Usage
Our super C function computes the norm of a vector/point:
float norm(struct Point p) {
return sqrt(p.x * p.x + p.y * p.y);
}
For the types we do:
fastlibrary.norm.argtypes = [Point]
fastlibrary.norm.restype = ctypes.c_float
For calling the C function, we do:
p = Point(0, 4)
p.x = 3
print(fastlibrary.norm(p))
Arrays and pointers
Suppose we want to be able to run:
/**
* @brief compute the integer barycenter
*
* @param n nb of points
* @param points (array of length n)
* @return the integer barycenter
*/
struct Point barycenter(int n, struct Point *p)
{
struct Point b = {.x = 0, .y = 0};
for (int i = 0; i < n; i++)
{
b.x += p[i].x;
b.y += p[i].y;
}
b.x /= n;
b.y /= n;
return b;
}
We declare the types as follows:
fastlibrary.barycenter.argtypes = [ctypes.c_int, ctypes.POINTER(Point)]
fastlibrary.barycenter.restype = Point
A Python list needs to be converted to C arrays.
pythonList = [Point(0, 4), Point(2, 0)]
length = len(pythonList)
Carray = (Point * length)(*pythonList)
The class Point represents struct Point. The expression (Point * length) represents the type "length continuous struct Point". We can directly feel it by passing *pythonList.
Finally we call:
result = fastlibrary.barycenter(length, Carray)
print(result.x, result.y)
We can create an non initialized C array as follows:
Carray = (Point * length)()
Carray[i] = ...
Tests
"Testing shows the presence, not the absence of bugs" (Dijkstra, Software Engineering Techniques)
Motivation
Utilisation
- Pour systèmes critiques : vérification formelle (model checking, assistant de preuve)
- Dans le reste de l'industrie : on fait du test
Croyance sur le test
- ça prend du temps => mais moins que tout débuguer
- c'est pas utile
- on ne sait pas comment s'y prendre
Bugs célèbres qui auraient pu être évités
- Ariane 5 (1996) : débordement sur la valeur des entiers (entiers grands devient entiers négatifs)
- Mars Orbiter (1999) : problème d'unités (pouces vs centimètres genre)
- CrowdStrike (2024) : panne "microsoft"
Vocabulaire
- tester = exécuter le programme pour trouver des erreurs
- erreur = comportemnet du programme différent des attentes
- attentes = spécification
- tests fonctionnels = est-ce que le code fonctionne comme on veut ?
- comme : tests unitaires, tests d'intégration, tests système
- aussi : tests de propriété, de non-régression (i.e. même si le code est modifié, les tests existants passent toujours)
- cf. cycle en V tests non-fonctionnels : test de performance, test d'intrusion (sécurité)
Comment on teste ?
- boite blanche : on a tout le code sous les yeux
- boîte noire : on n'utilise pas le code
Tests unitaires
Basic Testing
On crée des fonctions qui commence par test_.
def inc(x):
return x + 1
def test_inc():
assert inc(3) == 5
Then run pytest.
Tests in comments
You can write tests in the documentation.
def inc(x: int):
""" return the integer that follows x
Args:
x (int): a integer
Returns:
_int_: x+1
>>> inc(2)
3
"""
return x + 1
In order to perform the tests, run:
pytest --doctest-modules
You can also create files test_XAIJZPAUZXIUZABIZABC.txt for instance containing
# content of test_example.txt
hello this is a doctest
>>> x = 3
>>> x
3
See more information here: https://docs.pytest.org/en/stable/how-to/doctest.html
Test de couverture
- couverture des lignes de code (i.e. "noeuds de noeuds visités dans le graphe de flot de contrôle")
- couverture des décisions
- couverture des conditions (tous les cas des conditions)
- couverture de chemins (tous les chemins possibles du graphe de flot de contrôle)
C'est un test en boîte blanche, car on connaît le code.
En python
paquet : coverage
coverage run
coverage run --branch
coverage report
coverage html
Mais c'est un outil qui gère la converture de code comme ça... alors que l'on peut plutôt gérer la couverture avec du test.
Pour cela, pytest --cov=dossieroùilyalessources
Dans un fichier .coveragerc mettre ça pour éviter des erreurs de couverture sur des trucs stupides :
[report]
exclude_lines =
# Have to re-enable the standard pragma
pragma: no cover
# Don't complain if tests don't hit defensive assertion code:
raise NotImplementedError
En C
Programmes : gcov, lcov, genhtml
gcc --coveragedonneprogramme.gcno- on lance le programme
./programme, on obtientprogramme.gcda - on lance
gcov programmeavec option-b -c, on obtientprogramme.c.gcov - puis
lcov [--branch-coverage] - puis
genhtml ...
Test guidé par les données
C'est un test en boîte noire. On connait :
- la spécification
- le but du programme
- mais pas le code
On veut un jeu de test :
- qui couvre tous les cas, surtout les cas limites
- de taille minimale
- equivalence partitioning
Exemple pour le calcul de la valeur absolue :
def abs(x):
if x > 0:
return x
else x <= 0:
return -x
x = 1 ou -1 ou 0 c'est ok (0 = cas limite)
Tests automatiques
- Test aléatoire
- Exécution symbolique : model checking Le fuzzing consiste à générer automatiquement beaucoup de cas de tests... créer des entrées par mutation ou à partir d'une grammaire. Le but est de maximiser la couverture, ou cibler un type de vulnérabilités.
Exemple : https://en.wikipedia.org/wiki/American_Fuzzy_Lop_(software)
Typiquement, un algo génétique pour augmenter la couverture de code.
Conclusion
Sûreté : système fonctionne comme prévu Sécurité : système résiste à des personnes malintentionnées
Source
Vidéo de Yaëlle Vinçont (ENS Rennes) au Centre International de Rencontres Mathématiques :
- cycle en V 15:44
- Test automatique à '46
Decorators
A decorator is a functor that transforms each function call into something else.
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
What do you think about that example?
First example: write the calls
Our goal is to write a line at each call of the function into the terminal.
Bad solution: Hack the function itself
def fibnaive(n):
print("fibnaive(", n, ")")
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
fibnaive(3)
fibnaive( 3 )
fibnaive( 2 )
fibnaive( 1 )
fibnaive( 0 )
fibnaive( 1 )
3
It works but it is not reusable.
Write a functor
def printed(f):
def printerVersion(*args):
print(f.__name__, "(", *args, ")")
return f(*args)
return printerVersion
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
fibnaive = printed(fibnaive)
fibnaive(3)
fibnaive ( 3 )
fibnaive ( 2 )
fibnaive ( 1 )
fibnaive ( 0 )
fibnaive ( 1 )
3
Writing the decorator
@printed
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
fibnaive(3)
fibnaive ( 3 )
fibnaive ( 2 )
fibnaive ( 1 )
fibnaive ( 0 )
fibnaive ( 1 )
3
Writing a class instead of a functor
class Printed:
def __init__(self, f):
self.f = f
def __call__(self, *args):
print(self.f.__name__, "(", *args, ")")
return self.f(*args)
@Printed
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
fibnaive(3)
fibnaive ( 3 )
fibnaive ( 2 )
fibnaive ( 1 )
fibnaive ( 0 )
fibnaive ( 1 )
3
Second example: printing the running time
We want measure how fibnaiveis slow.
Bad solution
import time
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
begin = time.time()
fibnaive(30)
end = time.time()
print("Total time: ", end - begin)
Total time: 0.3410148620605469
The above code is ugly and not reusable.
Writing a functor
The code below is nice because it can be reused for any function.
def timedfunction(f):
def timedf(*args, **kwargs):
begin = time.time()
result = f(*args, **kwargs)
end = time.time()
print("Total time: ", end - begin)
return result
return timedf
fibnaive = timedfunction(fibnaive)
fibnaive(3)
Total time: 1.1920928955078125e-06
Total time: 0.000152587890625
Total time: 4.76837158203125e-07
Total time: 1.430511474609375e-05
Total time: 0.0001938343048095703
Total time: 0.00020623207092285156
Total time: 2.384185791015625e-07
Total time: 1.4781951904296875e-05
Total time: 0.0002486705780029297
Total time: 0.000263214111328125
3
Attempt to write the decorator with the functor
Instead of writing timedfunction(fibnaive) which is combersome, we try to decorate the function before its definition.
@timedfunction
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
fibnaive(3)
Total time: 2.384185791015625e-07
Total time: 4.76837158203125e-07
Total time: 4.673004150390625e-05
Total time: 2.384185791015625e-07
Total time: 6.651878356933594e-05
3
def timedfunction(f):
def timedf(*args, **kwargs):
begin = time.time()
result = f(*args, **kwargs)
end = time.time()
print("Total time: ", end - begin)
return result
return timedf
@timedfunction
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
fibnaive(3)
Total time: 7.152557373046875e-07
Total time: 1.1920928955078125e-06
Total time: 0.00017786026000976562
Total time: 4.76837158203125e-07
Total time: 0.00021576881408691406
3
Write the decorator with a class
class Timed:
def __init__(self, f):
self.f = f
self.__name__ = f.__name__
self.inside = False
def __call__(self, *args):
if not self.inside:
self.inside = True
begin = time.time()
result = self.f(*args)
end = time.time()
print("Total time: ", end - begin)
self.inside = False
return result
else:
return self.f(*args)
@Timed
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
fibnaive(32)
Total time: 2.3227994441986084
3524578
Memoization
The code for computing Fibonnaci numbers with a recursive function is so beautiful...
fibnaive(35)
Total time: 9.01091194152832
14930352
... but is so slow.
Direct code for memoized Fibonacci
It consists in storing the values already computed in a hashmap.
def fibmemo(n):
valuesAlreadyComputed = {}
def fibrec(n):
if n in valuesAlreadyComputed:
return valuesAlreadyComputed[n]
if n <= 1:
return 1
else:
valuesAlreadyComputed[n] = fibrec(n-1) + fibrec(n-2)
return valuesAlreadyComputed[n]
return fibrec(n)
fibmemo(35)
14930352
The previous code is ugly. And it handles two responsabilities: to compute the Fibonacci number, and to perform memoïsation. It should be seperated...
First attempt to write a decorator with a high-order function
def memo(f):
valuesAlreadyComputed = {}
def fmemo(*args):
if args not in valuesAlreadyComputed:
valuesAlreadyComputed[args] = f(*args)
return valuesAlreadyComputed[args]
return fmemo
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
fibnaive = memo(fibnaive)
fibnaive(35)
14930352
@memo
def fibnaive(n):
if n <= 1:
return 1
else:
return fibnaive(n-1) + fibnaive(n-2)
fibnaive(35)
14930352
class Memoize:
def __init__(self, f):
self.f = f
self.__name__ = f.__name__
self.valuesAlreadyComputed = {}
def __call__(self, *args):
if args not in self.valuesAlreadyComputed:
self.valuesAlreadyComputed[args] = self.f(*args)
return self.valuesAlreadyComputed[args]
@Memoize
def fib(n):
if n <= 1:
return 1
else:
return fib(n-1) + fib(n-2)
fib(35)
14930352
Combining decorators
@Printed
@Timed
@Memoize
def fib(n):
if n <= 1:
return 1
else:
return fib(n-1) + fib(n-2)
fib(35)
fib ( 35 )
fib ( 34 )
fib ( 33 )
fib ( 32 )
fib ( 31 )
fib ( 30 )
fib ( 29 )
fib ( 28 )
fib ( 27 )
fib ( 26 )
fib ( 25 )
fib ( 24 )
fib ( 23 )
fib ( 22 )
fib ( 21 )
fib ( 20 )
fib ( 19 )
fib ( 18 )
fib ( 17 )
fib ( 16 )
fib ( 15 )
fib ( 14 )
fib ( 13 )
fib ( 12 )
fib ( 11 )
fib ( 10 )
fib ( 9 )
fib ( 8 )
fib ( 7 )
fib ( 6 )
fib ( 5 )
fib ( 4 )
fib ( 3 )
fib ( 2 )
fib ( 1 )
fib ( 0 )
fib ( 1 )
fib ( 2 )
fib ( 3 )
fib ( 4 )
fib ( 5 )
fib ( 6 )
fib ( 7 )
fib ( 8 )
fib ( 9 )
fib ( 10 )
fib ( 11 )
fib ( 12 )
fib ( 13 )
fib ( 14 )
fib ( 15 )
fib ( 16 )
fib ( 17 )
fib ( 18 )
fib ( 19 )
fib ( 20 )
fib ( 21 )
fib ( 22 )
fib ( 23 )
fib ( 24 )
fib ( 25 )
fib ( 26 )
fib ( 27 )
fib ( 28 )
fib ( 29 )
fib ( 30 )
fib ( 31 )
fib ( 32 )
fib ( 33 )
Total time: 0.002529621124267578
14930352
Exercices
- Apply Dynamic Programming to solve Knapsack problem. Then apply memoization.
- Write factorial in imperative form, recursive form and recursive with tail recursion and compare the running time.
Multiple inheritance
Definition
class Car:
def drive(self):
print("wroum")
class GasolineCar(Car):
def drive(self):
print("🌫")
class ElectricCar(Car):
def drive(self):
print("⚡")
class HybridCar(ElectricCar, GasolineCar):
pass
H = HybridCar()
H.drive() # does it call the method drive in GasolineCar or ElectricCar?
⚡
Diamond problem
The problem is that a method not explicitely implemented in HybridCar should call the method of the same name in some superclass. But if both are implemented in GasolineCar and ElectricCar, the system does not how to solve the ambiguity. This problem is called the diamond problem.
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("GasolineCar", "Car"), ("ElectricCar", "Car"), ("HybridCar", "GasolineCar"), ("HybridCar", "ElectricCar")])
dot

Different solutions
1. Java solution: disallow multiple inheritance
In Java, multiple inheritance is disallowed, except for interfaces.
This example is OK :
interface GazolineCar {
public void drive();
public void fillWithFuel();
}
interface ElectricCar {
public void drive();
public void plug();
}
class HybridCar implements GazolineCar, ElectricCar {
public void drive() {
...
}
public void fillWithFuel() {
...
}
public void plug() {
....
}
}
But in Java, this is disallowed:
public class Car {
public void drive() {
...
}
}
public class GazolineCar extends Car {
public void drive() {
...
}
public void fillWithFuel() {
...
}
}
public class ElectricCar extends Car {
public void drive() {
...
}
public void plug() {
....
}
}
public class HybridCar extends GazolineCar, ElectricCar { //No
...
}
C++ solution: disallowing ambiguities
The C++ compiler disallows ambiguities and provides a compiling error in case of ambiguities.
class Car {
private:
Vector<Wheel> wheel;
};
class GazolineCar: public virtual Car {
public:
void fillWithFuel() {...};
void drive() {...};
};
class ElectricCar: public virtual Car {
public:
void plug() {...};
void drive() {...};
};
class HybridCar: public GazolineCar, public ElectricCar {
public:
void plug() {
}
}
int main()
{
HybridCar* h = new HybridCar();
h->drive();
return 0;
}
Main.cpp:33:8: error: request for member ‘drive’ is ambiguous
33 | h->drive();
| ^~~~~
Main.cpp:18:14: note: candidates are: ‘void ElectricCar::drive()’
18 | void drive() {};
| ^~~~~
Main.cpp:11:14: note: ‘void GazolineCar::drive()’
11 | void drive() {};
| ^~~~~
Python solution: deterministically resolve the ambiguity
In python, we deterministically resolve the ambiguity by computing which method of which class should be called. This is called Method Resolution Order.
Zoom on the Method Resolution Order in Python
The method resolution order (MRO) for class A is some total order on the superclass of A. Python searches the first class in the MRO of HybridCar that implements the method drive.
Example
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("GasolineCar", "Car"), ("ElectricCar", "Car"), ("HybridCar", "GasolineCar"), ("HybridCar", "ElectricCar")])
dot

class Car:
def drive(self):
print("wroum")
class GasolineCar(Car):
def drive(self):
print("🌫")
class ElectricCar(Car):
def drive(self):
print("⚡")
class HybridCar(GasolineCar, ElectricCar):
pass
H = HybridCar()
H.drive()
🌫
Here is the MRO is:
- first look in
HybridCar - then in
GasolineCar - then in
ElectricCar - then in
Car - finally in
object.
Behind the scene: the C3 linearization algorithm
The C3 linearization algorithm $mro$ takes a class $C$ and computes a total order $mro(C) = (C=C_0, C_1, \dots, C_n = object)$. It satisfies the following properties:
- For any outputs $mro(C) = (C=C_0, C_1, \dots, C_n = object)$, if $C_i$ inherits from $C_j$ then $i < j$
- $mro(C) = (C=C_0, C_1, \dots, C_n = object)$, in case of multiple inheritance
class Cl(..Ci...Cj), if $C_i$ is written before $C_j$ then $i < j$ - (Monotonicity) If $i < j$ then $C_i$ is before $C_j$ in $mro(B)$ for any subclass of $B$ of $C$
Here is a pseudo-code for C3 linearization algorithm:
- $mro(object) = [object]$
- if
class C(D)then $mro(C) = [C] + mro(D)$ - if
class C(D1, ... Dk)then $mro(C) = [C] + merge(mro(D_1), \dots, mro(D_k))$
The merge operations $merge(L_1, \dots, L_k)$ is:
merge(L1, ..., Lk)
L = empty list
while not all the lists are empty
Find a head C of some of the list L1, ..., Lk
that does not appear in the tail of some list L1, ..., Lk.
If there is not such $C$, raise an error
Remove all the occurrences of C in L1, ..., Lk
L := L + [C]
return L
Get the MRO in Python
It is possible to get the order via the method mro().
class Car(): pass
class GasolineCar(Car): pass
class ElectricCar(Car): pass
class HybridCar(GasolineCar, ElectricCar): pass
HybridCar.mro()
[__main__.HybridCar,
__main__.GasolineCar,
__main__.ElectricCar,
__main__.Car,
object]
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([(c, "O") for c in "CABDE"] + [("K1", "C"), ("K1", "A"), ("K1", "B"), ("K3", "A"), ("K3", "D"),
("K2", "B"), ("K2", "D"), ("K2", "E")] + [("Z", k) for k in ["K1", "K3", "K2"]])
dot

class O(): pass
class A(O): pass
class B(O): pass
class C(O): pass
class D(O): pass
class E(O): pass
class K1(C, A, B): pass
class K3(A, D): pass
class K2(B, D, E): pass
class Z(K1, K3, K2): pass
Z.mro()
[__main__.Z,
__main__.K1,
__main__.C,
__main__.K3,
__main__.A,
__main__.K2,
__main__.B,
__main__.D,
__main__.E,
__main__.O,
object]
Inconsistency
Sometimes it is impossible to find a consistent method resolution.
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("A", "B"), ("A", "C"), ("D", "C"), ("D", "B"), ("E", "A"), ("E", "D")])
dot

class B: pass
class C: pass
class A(B, C): pass
class D(C, B): pass
class E(A, D): pass
E.mro()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[6], line 5
3 class A(B, C): pass
4 class D(C, B): pass
----> 5 class E(A, D): pass
6 E.mro()
TypeError: Cannot create a consistent method resolution
order (MRO) for bases B, C
Stupid example
class Animal:
pass
class TrucBizarre(Animal, type):
pass
Function super
Actually super(cls, x) returns a wrapper that calls the method as we were in the next class strictly after cls in the MRO.
Shallow copy
In the following code, B is a shallow copy of A.
A = [[1], [2]]
B = A[:]
A = [[1], [2]]
B = A.copy()
B[0] = 3
print(A)
print(B)
[[1], [2]]
[3, [2]]
A = [[1], [2]]
B = A.copy()
B[0].append(42)
print(A)
print(B)
[[1, 42], [2]]
[[1, 42], [2]]
import copy
A = [[1], [2]]
B = copy.copy(A)
B[0].append(42)
print(A)
print(B)
[[1, 42], [2]]
[[1, 42], [2]]
Deep copy
import copy
A = [[1], [2]]
B = copy.deepcopy(A)
B[0].append(42)
print(A)
print(B)
[[1], [2]]
[[1, 42], [2]]
Special functions
Shallow copy and deep copy can be respectively user-defined by special functions __copy__ and __deepcopy__.
Metaclasses
class MyMeta(type):
"""
We define a meta class: a meta class is a class describing what a class is.
"""
def __new__(mcs, name, bases, dct):
"""
called when the class is created
:param mcs: the meta-class
:param name: the name of the class that is created
:param bases:
:param dct:
"""
print(f'mcs: {mcs}\n name: {name}\n bases: {bases} \n dct: {dct}')
return type.__new__(mcs, name, bases, dct)
def __init__(self, *args, **kwargs):
print(f'self: {self}\n args: {args}\n kwargs: {kwargs}')
return type.__init__(self, *args, **kwargs)
class MyClass(metaclass=MyMeta):
pass
# Instantiate the class
#my_instance = MyClass()
mcs: <class '__main__.MyMeta'>
name: MyClass
bases: ()
dct: {'__module__': '__main__', '__qualname__': 'MyClass'}
self: <class '__main__.MyClass'>
args: ('MyClass', (), {'__module__': '__main__', '__qualname__': 'MyClass'})
kwargs: {}
Example of documentation checker
class MetaClassWithDoc(type):
"""
This meta-class is like type but it checks at the creation (in __new__ of the class)
that all methods have a docstring (__doc__ field is defined)
"""
def __new__(cls, name, bases, dct):
for attr, value in dct.items():
if callable(value) and not value.__doc__:
raise TypeError(f'Method {attr} must have a docstring')
return super().__new__(cls, name, bases, dct)
class DocumentedClass(metaclass=MetaClassWithDoc):
"""
All methods of this class should be documented. Otherwise, BOOM.
"""
def method_with_docstring(self):
"""This method is documented."""
pass
# def method_without_docstring(self):
# pass # This will raise a TypeError
Example of timed classes
import types
from time import time
class TimerMetaClass(type):
"""
meta-class for classes with methods that are timed
"""
def __new__(mcs, name, bases, dct):
def getTimedVerionOfMethod(name, method):
def timedVersionFunctionOfMethod(self, *args, **kwargs):
t = time()
result = method(self, *args, **kwargs)
print("Appel de %s :\t%s" % (name, time() - t))
return result
timedVersionFunctionOfMethod.__name__ = method.__name__
timedVersionFunctionOfMethod.__doc__ = method.__doc__
timedVersionFunctionOfMethod.__dict__ = method.__dict__
return timedVersionFunctionOfMethod
d = {}
for name, slot in dct.items():
if type(slot) is types.FunctionType:
d[name] = getTimedVerionOfMethod(name, slot)
else:
d[name] = slot
return type.__new__(mcs, name, bases, d)
class A(metaclass=TimerMetaClass):
def m(self): pass
a = A()
a.m()
Magic methods
Small list
Magic methods are special methods that can be implemented, and then be used with standard Python constructions like +, len(..), print(...), etc.
| Python constructions | Real thing happening with magic methods |
|---|---|
1+2 | (1).__add__(2) |
2 * 3 | (2).__mul__(3) |
| len(a) | a.__len__() |
| print(a) | print(a.__repr__) |
Full list here: https://docs.python.org/3/reference/datamodel.html#specialnames
Example
from dataclasses import dataclass
@dataclass
class Vector2D:
"""Class for representing a point in 2D."""
x: float
y: float
def __add__(self, other):
return Vector2D(self.x + other.x, self.y + other.y)
print(Vector2D(2, 3) + Vector2D(10, 40))
Vector2D(x=12, y=43)
There are libraries to manipulate numbers with units, e.g. https://pypi.org/project/Pint/
SOLID principles
SOLID is an acronym for the five object-oriented design (OOD) principles by Robert C. Martin (also known as Uncle Bob). They provide a guide to writing maintainable, scalable, and robust software. They are high-level principles.

Single responsibility principle
A class should have a single responsibility.
Bad example
class Hero:
lp = 50
x = 2
y = 3
vx = 0
vy = 0
ax = 0
ay = 0

Drawbacks:
- The class is huge so difficult to understand
- Difficult to test: any modification of the class would need to test the whole class again.
- Difficult to extend/modify.
Good
- Seperate the responsabilities into different classes
class Life:
lp = 50
def is_dead(self):
return self.lp <= 0
class PhysicalPoint:
x = 2
y = 3
vx = 0
vy = 0
ax = 0
ay = 0
class Hero:
def __init__(self):
self.life = Life
self.point = PhysicalPoint()
Open/closed principle
Prefer extensions via adding new classes than modification of existing classes.
Bad example
It is bad to modify existing classes, add/remove fields, modify methods etc.
Drawbacks:
- Need for retest code that was already tested
- Need to check that the modified class is still usable from other classes
For example, suppose you want to add a new type of ennemy would need to modify existing code.
def get_damage(enemy):
if enemy.type == DRAGON:
return enemy.force + 3
elif enemy.type == WIZARD:
return enemy.magic ** 2
elif enemy.type == HUMAN:
return 2
else:
raise NotImplementedError
Good example
- do new classes that inherits from abstract classes, assign a behavior to a class by modifying a field/method which is abstract
class Enemy:
def get_damage(self):
raise NotImplementedError
class Dragon(Enemy):
def get_damage(self):
return self.force + 3
class Wizard(Enemy):
def get_damage(self):
return self.magic ** 2
class Human(Enemy):
def get_damage(self):
return 2
class SuperHuman(Enemy):
def get_damage(self):
return 10000
Liskov substitution principle
Barbara Liskov - 2008 Turing Award

Wrong example
Suppose there exists a class Square. We might be tempted to create a class Rectangle as a subclass of Square because we reuse the field width, and just add a field height.
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("Rectangle", "Square")])
dot

from dataclasses import dataclass
@dataclass
class Square():
width: float
def area(self):
return self.width * self.width
@dataclass
class Rectangle(Square):
height: float
def area(self):
return self.width * self.height
L = [Square(2), Rectangle(2, 3)]
for shape in L:
print(shape.area())
4
6
This causes problems. Indeed, the developer reads "Any rectangle is a square" which is false. Some invariants written in the class Square may no longer be true for a Rectangle.
Solution
Please do:
from graphviz import Digraph
dot = Digraph(graph_attr=dict(rankdir="BT"), edge_attr={'arrowhead':'empty'})
dot.edges([("Square", "Rectangle")])
dot

from dataclasses import dataclass
@dataclass
class Rectangle():
width: float
height: float
def area(self):
"""_summary_
Returns:
_type_: _description_
"""
return self.width * self.height
class Square(Rectangle):
def __init__(self, width):
super().__init__(width, width)
L = [Square(2), Rectangle(2, 3)]
for shape in L:
print(shape.area())
4
6
Interface segregation principle
Clients should not be forced to depend on methods that they do not use.
- Build small devoted abstract classes specific to some clients
Instead of implementing Dijkstra's algorithm that takes a GridGraph, please implement it that takes an abstract Graph. Dijkstra's algorithm does not care about method like G.grid_width or G.grid_height.
Dependency inversion principle
Please always depend on abstraction, not on concrete classes.
Bad example
For instance, the class Hero here depends on the class Sound. The class Sound is specific and you create an object of type Sound.
class Hero:
def __init__(self):
self.soundAttack = Sound("attack.ogg")
def attack(self):
self.soundAttack.play()
Drawbacks
- If the implementation if Sound changes (for instance, it does not take .ogg files anymore but .wav)
- handling deaf persons would require to traverse all the classes using
Soundand make the modification
Solution
Decide an abstract interface for the game first and stick to it (except if it is bad!).
class IGame:
sound: ISound
graphics: IGraphics
class Hero:
def __init__(self, game: IGame):
self.game = game
def attack(self):
self.game.sound.play("attack")
Advantages:
- Robust to the change of a library/framework. If the implemntation of the very concrete
Soundclass changes, we just change the implementation ofISound. The modification are confined. - Robust for adding new feature. Suppose you want to be inclusive and target deaf persons. Just add a new subclass to
ISoundthat also displays a subtitle.
Design patterns
Un design pattern désigne une astuce pour structurer du code correctement pour réaliser une certaine tâche.
Command
Pour implémenter annuler/refaire,
- https://github.com/tableaunoir/tableaunoir/blob/master/src/Operation.ts
- https://github.com/tableaunoir/tableaunoir/blob/master/src/OperationTranslate.ts
Itérateur
(déjà vu !)
Observateur
Singleton
Faire qu'une classe ne peut qu'avoir une seule instance.
Ecrire des fonctions à l'intérieur de fonctions
En C, c'est impossible. Mais en Python, on peut écrire des fonctions à l'intérieur de fonctions.
En Python, les variables sont capturées par référence (bounded by reference).
def f():
i = 1
def g():
return i+1
i = 2
return g()
f()
3
Ne vous inquiétez pas ! On peut aussi simuler la capture par valeurs (bounding by value). Pour ce faire, il suffit d'utiliser un paramètre par défaut.
def f():
i = 1
def g(x,i=i):
return i+x
i = 2
return g(20)
f()
21
def f():
A = []
for i in range(10):
def g(i=i):
return i+1
A.append(g)
return A
f()[5]()
6
Bien sûr, c'est le même principe avec une lambda expression.
def f():
return [lambda : i+1 for i in range(10)]
f()[5]()
10
def f():
return [lambda i=i: i+1 for i in range(10)]
f()[5]()
6
Lambda expressions en C++
Premier exemple
Voici un exemple d'une fonction qui trie selon la valeur absolue des nombres :
#include <algorithm>
#include <cmath>
void abssort(float* x, unsigned n) {
std::sort(x, x + n,
[](float a, float b) {
return (std::abs(a) < std::abs(b));
}
);
}
Le [] qui débute la lambda-expression s'appelle clause de capture ou introduction lambda. IL permet en tout cas de dire que la suite est une lambda expression.
Capture de variables
[]
[] que l'on ne peut pas utiliser de variables du scope d'au dessus. Le code suivant ne compile pas car on utilise y dans le corps de f.
int y = 1;
auto f = [](int x) -> int {return x+y;};
printf("%d", f(2));
Capture par valeur
Qu'affiche le programme suivant ?
int y = 1;
auto f = [y](int x) -> int {return x+y;};
y = 2000;
printf("%d", f(2));
y au moment on a écrit la lambda expression.
Capture par référence
Pour réaliser une capture par référence, on utilise [&y].
Qu'affiche le programme suivant ?
int y = 1;
auto f = [&y](int x) -> int {return x+y;};
y = 1000;
printf("%d", f(2));
y par référence. Quand on appelle f(2), on regarde la valeur de y.
On peut mélanger
Bien sûr, on peut mélanger de la capture par valeur et par référence. Par exemple :
[&y, z](int x) -> int {return x+y+z;}
Applications
TODO: trouver un exemple pertinent
Fonctions en Javascript
Javascript a un comportement spécial avec le mot-clé this qui désigne un objet contexte. Pour une fonction déclarée au plus haut niveau, this désigne un objet global globalThis, typiquement la fenêtre du navigateur :
function f() {
// this est globalThis
}
Mais en mode strict, c'est undefined...
En englobant des fonctions c'est pareil :
function f() {
function g() {
return this;
}
return g();
}
L'appelle à f() renvoie globalThis.
Dans une classe, this est l'objet courant.
class A {
f() {
// this ici désigne l'instance de A
}
}
class B {
f() {
function g() {
return this; // ici this est undefined
}
return g();
}
}
Par contre, avec une fonction flèche, le this est conservé :
class C {
f() {
const g = () => this; // ici this est l'instance de C
return g();
}
}
Resource acquisition is initialization
Problème en C
void f() {
Point* p = malloc(sizeof(Point));
//...
//⚠ là C détruit le pointeur p, mais pas la zone mémoire qui contient le Point
}
void f() {
Point p = {.x = 5, .y = 3};
//...
// là C détruit p
}
RAII c'est utiliser le mécanisme de destruction pour détruire les ressources. Du coup, l'idée est d'utiliser la programmation objet pour gérer les ressources (mémoire, fichier, etc.).
## Programmation objet en C++
Elle est similaire à Python. Les différences sont :
- on a des champs et méthodes privées / protégées / publics
- on a surtout, en plus du constructeur, un destructeur.
Définition d'une classe
class RadixTree {
RadixTree() {
//constructeur
}
~RadixTree() {
//destructeur
}
}
Durée de vie
void f() {
Point p = {.x = 5, .y = 3};
//...
// là C détruit p
}
C++ appelle le destructeur au moment où la mémoire est désalloué (là quand on dépile le contexte sur la pile d'appel, comme en C). Du coup, avec constructeur et destructeur, on peut gérer les ressources, sachant que le compilateur va faire que le destructeur est appelé dès que l'objet est détruit :
- au constructeur, on alloue la mémoire, on ouvre un fichier
- au destructeur, on libère la mémoire, on ferme un fichier

En plus C++ a un système d'exception, compatible avec la durée de vie des objets ! Donc si une exception est levé, la mémoire est bien libérée et le destructeur est appelé.
Avantages
- A l'utilisation des ressources, le code est léger. Pas besoin d'écrire explicitement
freeRadixTree(...) - Impossible d'oublier de libérer la mémoire, même en cas d'exception car c'est fait dans le destructeur
- C'est bien organisé. On sait où trouver la création et la libération de ressources : respectivement dans le constructeur et le destructeur.
### Terminologie
Utiliser les constructeurs et destructeurs pour gérer les ressources s'appelle "Resource acquisition is initialization" (RAII). D'autres personnes appellent ça "scope bound resource management".
RAII est utilisé en C++11 et Rust.
Références
En C pour faire un swap, on écrit
void swap(int* p, int* q) {
int tmp = *p;
*p = *q;
*q = tmp;
}
int x, y;
swap(&x, &y)
Soucis avec les pointeurs
Le soucis des pointeurs c'est :
- c'est moche
*p + *qau lieu du naturelx + y; - on peut modifier à la fois
pet*pdonc trop de bugs ; - on peut avoir un pointeur null ou qui pointe vers n'importe quoi
- C'est mieux de directement manipuler des objets
Point pet non pasPoint* pcar ça appelle le destructeur quand la mémoire est libérée
Pour cela, il propose les références.
Définition d'une référence
Une référence est un nouveau nom pour désigner un objet existant.
void swap(int& i, int& j)
{
int tmp = i;
i = j;
j = tmp;
}
int x, y;
swap(x, y);
L'implémentation derrière la scène est la même que les pointeurs. Mais c'est une vision technique. On peut vraiment voir ça comme un nouveau nom.
Exercice
int x = 4;
int& y = x;
y = 5;
Que vaut x à la fin ?
Il vaut 5. Car en vrai, c'est la même chose que :
int x = 4;
int py = &x;
*py = 5;
Voir aussi
[https://isocpp.org/wiki/faq/references]
Copie en C++
Le C++ fonctionne comme le C : par défaut, on copie.
Rappel du C
struct Point {
int x;
int y;
}
int main() {
Point p = {.x = 3, .y = 2};
Point q = p;
q.x = 100;
}
Que vaut p.x ?
En C++ pareil, on copie
vector<int> A = ... un vecteur de 10000000 d'éléments....
vector<int> B = A;
Oui, oui, .... B = A; est hyper looooonnnnnnng.
Constructeur par copie
Par défaut, quand C++ fait une "copie", il fait une copie superficielle. Mais C++ offre la possibilité de définir soi-même un constructeur par copie.
class BigInt {
BigInt(BigInt& x) {
// là on écrit le code qui copie
}
}
Pointeurs intelligents (smart pointers)
Motivation
Le soucis
Voici un code C :
void f() {
int* p = malloc(sizeof(int));
*p = 5;
}
Oh no... On oublier de libérer la mémoire. C'est une fuite mémoire. On aurait du écrire :
void f() {
int* p = malloc(sizeof(int));
*p = 5;
...
free(p);
}
Pareil, le langage C++ offre le même souci :
void f() {
int* p = new int(5);
}
alors qu'il faut écrire :
void f() {
int* p = new int(5);
delete p;
}
C'est trop en demander d'embêter les gens à devoir écrire free(p) (en C) ou delete p (en C++). Il faut un code sûr.
Solution
Les pointeurs intelligents sont des structures de données qui permettent de garantir que la mémoire est libérée automatiquement. Ils sont disponibles en C++ via la STL et sont construit selon le principe RAII : si tu crées, tu t'occupes aussi de détruire. Ils sont disponibles nativement en Rust, et dans une moindre mesure en Python !
On oppose les pointeurs intelligents aux pointeurs bruts du C, C++, Pascal, qui ne sont que des adresses mémoires. Sauf besoin contraire, quand vous programmez en C++ ou Rust, il n'y a pas de raison d'utiliser des pointeurs bruts car ils ne sont pas sûrs (fuite mémoire).
La solution n'est pas parfaite, il peut encore y avoir des fuites mémoire dans des cas spéciaux. On verra ça à la fin. D'abord, soyons optimiste.
Principe
Voici un exemple d'utilisation d'un pointeur intelligent en C++ :
std::unique_ptr<int> p = std::make_unique<int>(5);
Pas de soucis car l'objet unique_ptr<int> est propriétaire du pointeur vers d'une zone mémoire où il y a écrit 5. Quand on quitte la fonction, l'objet est détruit et c'est dans le destructeur de l'objet que le pointeur est désalloué. Pas besoin d'utiliser free (C) ou delete.
Une solution qui ne marche pas
template <typename T>
class stupid_smart_ptr
{
T* m_ptr {};
public:
// Pass in a pointer to "own" via the constructor
stupid_smart_ptr(T* ptr=nullptr)
:m_ptr(ptr)
{
}
// The destructor will make sure it gets deallocated
~stupid_smart_ptr()
{
delete m_ptr;
}
// Overload dereference and operator-> so we can use stupid_smart_ptr like m_ptr.
T& operator*() const { return *m_ptr; }
T* operator->() const { return m_ptr; }
};
// A sample class to prove the above works
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
};
int main()
{
stupid_smart_ptr<Resource> res(new Resource()); // Note the allocation of memory here
//...
return 0;
} // no explicit delete needed: res goes out of scope here, and the destructor destroys the allocated Resource for us
Que fait le programme suivant :
int main()
{
Auto_ptr1<Resource> res1(new Resource());
Auto_ptr1<Resource> res2(res1); // Alternatively, don't initialize res2 and then assign res2 = res1;
return 0;
} // res1 and res2 go out of scope here
?
Unique ptr
Un unique pointer est un pointeur intelligent qui ne peut pas être copié. Il est garanti "non copiable".
En C++ :
std::unique_ptr<int> p = std::make_unique<int>(5);
En Rust :
let b = Box::new(5);
Voici une implémentation académique d'une classe de unique pointer :
template <typename T>
class UniquePtr {
private:
T* ptr;
public:
// Default constructor
explicit UniquePtr(T* p = nullptr) noexcept : ptr(p) {}
// Destructor
~UniquePtr() {
delete ptr;
}
// copy constructor and assignment DO NOT EXIST (unique ownership)
UniquePtr(const UniquePtr&) = delete;
UniquePtr& operator=(const UniquePtr&) = delete;
// Move constructor
UniquePtr(UniquePtr&& other) noexcept : ptr(other.ptr) {
other.ptr = nullptr;
}
// Move assignment operator
UniquePtr& operator=(UniquePtr&& other) noexcept {
if (this != &other) {
delete ptr; // free current resource
ptr = other.ptr; // take ownership
other.ptr = nullptr; // release other's ownership
}
return *this;
}
// Access underlying pointer
T* get() const noexcept { return this->ptr; }
// Dereference operators
T& operator*() const noexcept { return *this->ptr; }
T* operator->() const noexcept { return this->ptr; }
};
Shared pointers
Un shared pointer est un pointeur intelligent qui compte combien il y a de référence vers la cellule mémoire. On dit que la cellule mémoire est partagée.
#include <memory>
void f() {
int* rawp = new int(5);
shared_ptr<int> p(rawp);
...
}
- Qu'imprime le programme C++ ci-dessous ?
#include <memory>
void f() {
int* rawp = new int(5);
shared_ptr<int> p(rawp);
auto q = p;
std::cout << q.use_count();
}
Le C++ offre une construction pour carrément faire disparaître le pointeur brut.
#include <memory>
void f() {
auto p = std;;make_shared<int>(5);
auto q = p;
std::cout << q.use_count();
}
Implémentation d'un shared pointer
Solution naïve
On pourrait une structure de données avec le nombre de référence suivi d'un pointeur brut :

Est-ce que ça ça marche ?
Solution en C++
En C++, un pointeur intelligent shared pointer est une structure avec un pointeur (brut) vers le nombre de référence, et un pointeur brut.

Ainsi, si on copie la structure, le nombre de références est partagé. Voici une implémentation fictive en C++ d'un shared pointer :
template<class T>
class my_shared_ptr
{
private:
T * ptr = nullptr;
unsigned int * refCount = nullptr;
public:
//ptr should non nullptr
my_shared_ptr(T * ptr) : ptr(ptr), refCount(new unsigned int(1))
{
}
/*** Copy Semantics ***/
my_shared_ptr(const my_shared_ptr & obj)
{
this->ptr = obj.ptr;
this->refCount = obj.refCount;
(*this->refCount)++;
}
my_shared_ptr& operator=(const my_shared_ptr & obj) // copy assignment
{
__cleanup__(); // cleanup any existing data
this->ptr = obj.ptr;
this->refCount = obj.refCount;
(*this->refCount)++;
}
/*** Move Semantics ***/
my_shared_ptr(my_shared_ptr && dyingObj)
{
this->ptr = dyingObj.ptr;
this->refCount = dyingObj.refCount;
dyingObj.ptr = dyingObj.refCount = nullptr;
}
my_shared_ptr& operator=(my_shared_ptr && dyingObj)
{
__cleanup__();
this->ptr = dyingObj.ptr;
this->refCount = dyingObj.refCount;
dyingObj.ptr = dyingObj.refCount = nullptr;
}
unsigned int get_count() const
{
return *refCount;
}
T* get() const
{
return this->ptr;
}
T* operator->() const
{
return this->ptr;
}
T& operator*() const
{
return *this->ptr;
}
~my_shared_ptr() // destructor
{
__cleanup__();
}
private:
void __cleanup__()
{
if(refCount == nullptr)
return;
(*refCount)--;
if (*refCount == 0)
{
if (nullptr != ptr)
delete ptr;
delete refCount;
}
}
};
En Rust
En Rust, la structure pour un pointeur intelligent shared pointer est un unique pointeur brut vers une structure qui contient le nombre de référence, suivi des données.

En Rust, il y a Rc (Reference Counted) :
#![allow(unused)] fn main() { use std::rc::Rc; let five = Rc::new(5); }
Il y a aussi Arc qui thread safe (en C++ shared_ptr est thread safe) :
#![allow(unused)] fn main() { use std::sync::Arc; let mut data = Arc::new(5); }
Cycles et pointeurs faibles
Motivation
Sur le code Python suivant :
class Node:
def __init__(self):
self.friend = None
def f():
A = Node()
B = Node()
A.friend = B
B.friend = A
f()
On ne libère pas la mémoire car les compteurs de référence pour A et B étaient à 2 et passe à 1.
Weak ptr
Pour éviter des boucles dans le graphe des pointeurs, on peut utiliser des weak pointers. Un weak pointer est une structure de données qui modélise un pointeur vers une donnée, ou peut-être pas, si la donnée a été supprimée.
C++
std::shared_ptr<int> p = std::make_shared<int>(5);
std::weak_ptr wp = p;
if(std::shared_ptr<int> strong_p = wp.lock()) {
//here you can use strong_p
}
else
{
//the data does not exist anymore
}
Rust
En Rust, it is std::rc::Weak, see the manual.
Python
En Python aussi, on peut créer des pointeurs faibles :
import sys
import weakref
class Person:
pass
x = Person()
y = weakref.ref(x)
print(y)
print(y())
sys.getrefcount(x)
Dans le code ci-dessus print(y) donne :
<weakref at 0x7f730681aa40; to 'Person' at 0x7f7307588970>
Et print(y()) permet d'accéder à l'objet :
<__main__.Person object at 0x7f7307588970>
sys.getrefcount(x) donne 2 (pour x et pour la référence à x dans sys.getrefcount(x)).
import sys
import weakref
class Person:
pass
x = Person()
y = weakref.ref(x)
del x
print(y)
print(y())
Ici print(y) montre que y est toujours un pointeur faible, mais il est mort :
<weakref at 0x7f73067cba90; dead>
En accédant à la donnée qui n'existe plus, y() renvoie None.
Implémentation des weak ptr
#include <iostream>
#include <utility>
template <typename T>
class SharedPtr;
template <typename T>
class WeakPtr;
// Contrôle partagé entre SharedPtr et WeakPtr
template <typename T>
struct ControlBlock {
T* ptr;
size_t strong_count;
size_t weak_count;
ControlBlock(T* p) : ptr(p), strong_count(1), weak_count(0) {}
};
// -------- SharedPtr --------
template <typename T>
class SharedPtr {
private:
T* ptr;
ControlBlock<T>* control;
friend class WeakPtr<T>;
public:
// Constructeur
explicit SharedPtr(T* p = nullptr)
: ptr(p), control(p ? new ControlBlock<T>(p) : nullptr) {}
// Destructeur
~SharedPtr() {
release();
}
// Copie (augmente strong_count)
SharedPtr(const SharedPtr& other)
: ptr(other.ptr), control(other.control) {
if (control) control->strong_count++;
}
// Move
SharedPtr(SharedPtr&& other) noexcept
: ptr(other.ptr), control(other.control) {
other.ptr = nullptr;
other.control = nullptr;
}
// Copie depuis WeakPtr
explicit SharedPtr(const WeakPtr<T>& weak);
// Assignation copie
SharedPtr& operator=(const SharedPtr& other) {
if (this != &other) {
release();
ptr = other.ptr;
control = other.control;
if (control) control->strong_count++;
}
return *this;
}
// Assignation move
SharedPtr& operator=(SharedPtr&& other) noexcept {
if (this != &other) {
release();
ptr = other.ptr;
control = other.control;
other.ptr = nullptr;
other.control = nullptr;
}
return *this;
}
// Libère la ressource si plus de SharedPtr
void release() {
if (control) {
if (--control->strong_count == 0) {
delete ptr;
ptr = nullptr;
if (control->weak_count == 0)
delete control;
}
ptr = nullptr;
control = nullptr;
}
}
T* get() const { return ptr; }
T& operator*() const { return *ptr; }
T* operator->() const { return ptr; }
size_t use_count() const { return control ? control->strong_count : 0; }
explicit operator bool() const { return ptr != nullptr; }
};
// -------- WeakPtr --------
template <typename T>
class WeakPtr {
private:
ControlBlock<T>* control;
friend class SharedPtr<T>;
public:
WeakPtr() : control(nullptr) {}
// Constructeur depuis SharedPtr
WeakPtr(const SharedPtr<T>& shared)
: control(shared.control) {
if (control) control->weak_count++;
}
// Copie
WeakPtr(const WeakPtr& other)
: control(other.control) {
if (control) control->weak_count++;
}
// Move
WeakPtr(WeakPtr&& other) noexcept
: control(other.control) {
other.control = nullptr;
}
// Destructeur
~WeakPtr() {
release();
}
void release() {
if (control) {
if (--control->weak_count == 0 && control->strong_count == 0)
delete control;
control = nullptr;
}
}
// Crée un SharedPtr si l’objet existe encore
SharedPtr<T> lock() const {
if (control && control->strong_count > 0) {
control->strong_count++;
return SharedPtr<T>(*this); // appelle le constructeur privé
}
return SharedPtr<T>(); // nul
}
bool expired() const {
return !control || control->strong_count == 0;
}
};
// Constructeur SharedPtr depuis WeakPtr
template <typename T>
SharedPtr<T>::SharedPtr(const WeakPtr<T>& weak)
: ptr(nullptr), control(weak.control) {
if (control && control->strong_count > 0) {
ptr = control->ptr;
control->strong_count++;
} else {
control = nullptr;
}
}
Move semantics
En C++, les objets sont copiés par défaut. C'est inspiré de C. Ca évite les effets de bords.
string s("Bonjour");
vector<string> V;
V.push_back(s);
... on continue à utiliser
s[1] = "c"; // s est modifé mais pas la copie de s dans V
Parfois copier c'est débile
Supposons que l'on a un tableau de trucs.
class MyVector {
string* data;
size_t size;
size_t capacity;
public:
vector(){
size = 0;
capacity = 2;
data = new truc[capacity];
}
resize(size_t new_capacity) {
truc* new_data = new truc[new_capacity];
for(int i = 0; i < size; i++) {
new_data[i] = data[i];
}
std::swap(data, new_data);
delete[] new_data;
capacity = new_capacity;
}
void push_back(const truc& s){
if(size == capacity) {
resize(capacity * 2);
}
data[size] = s;
size++;
}
}
Le problème est dans
```cpp
new_data[i] = data[i];
```
Ca fait une copie des trucs ! alors que data va disparaître juste après.
Idée
Ce qu'on fait avec la copie :
TODO image avec des fruits
Idée pour améliorer :
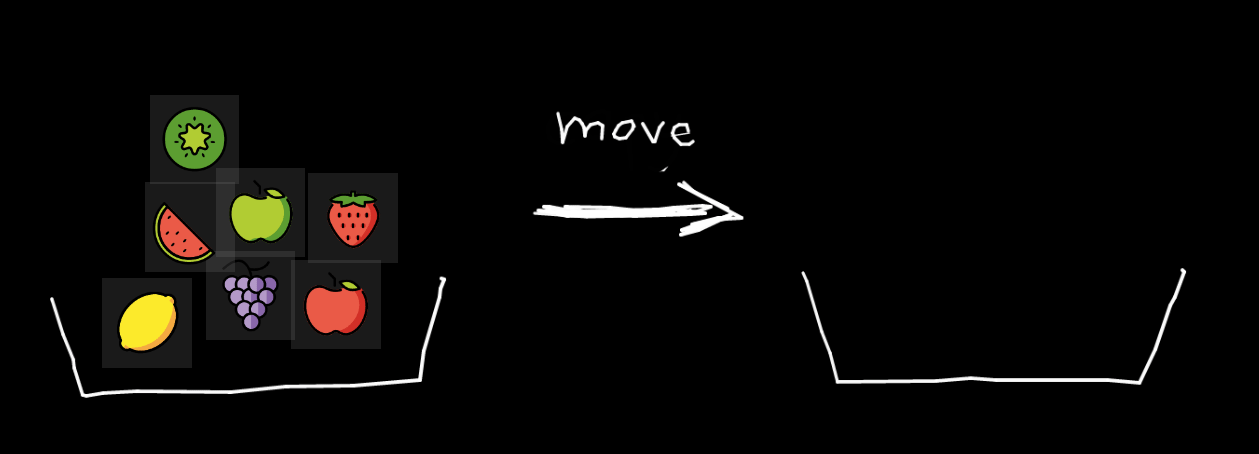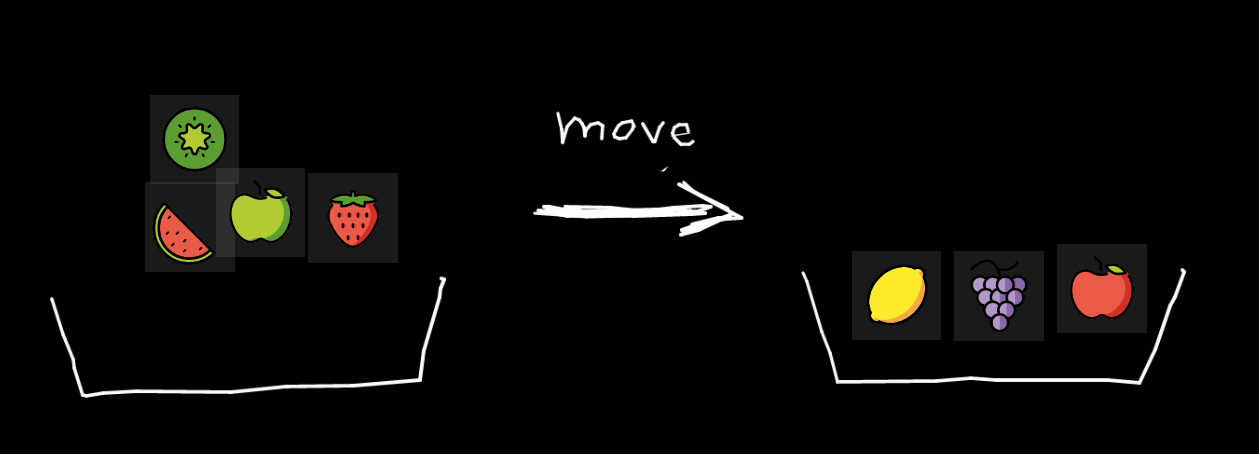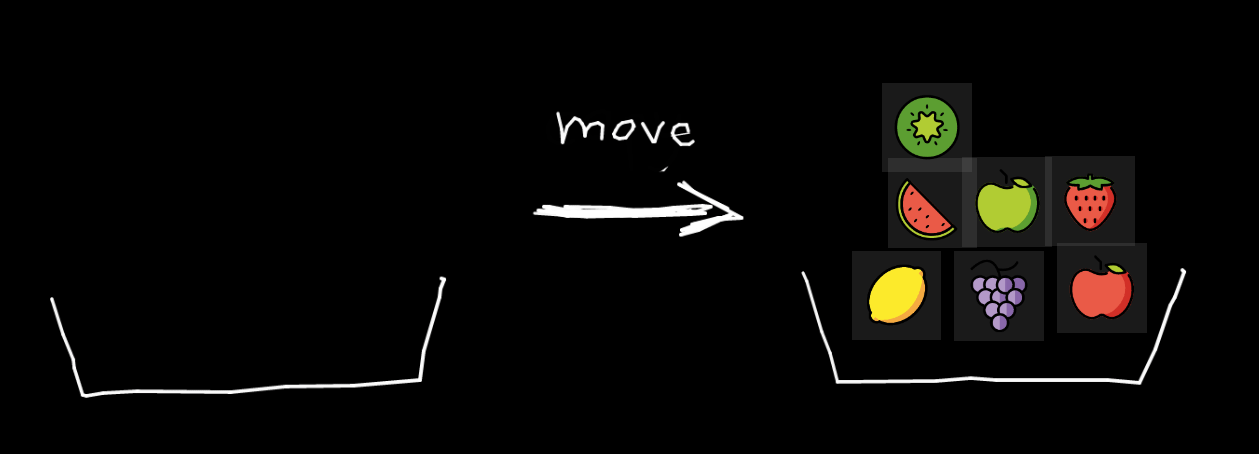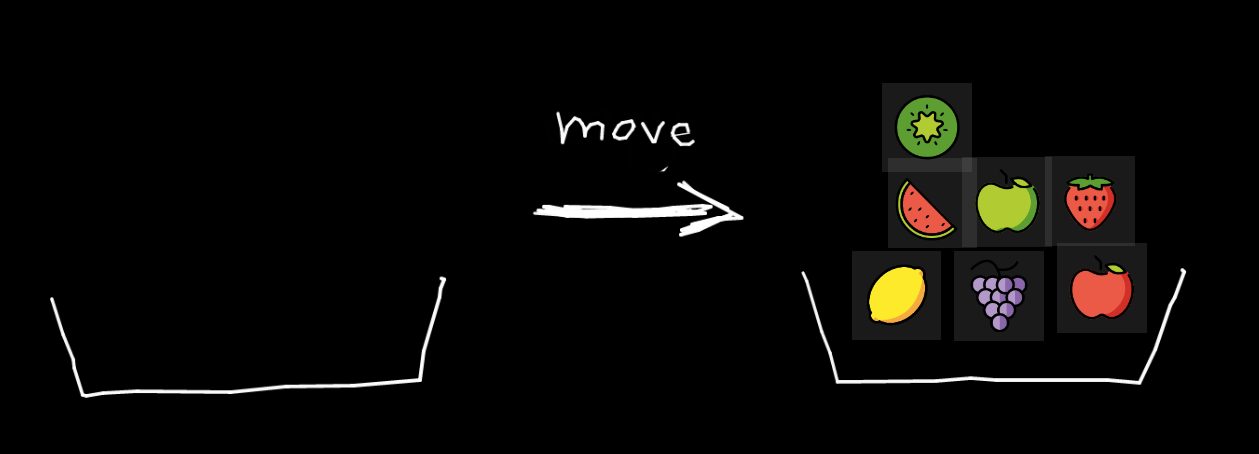
Idée générale de la move semantics
Depuis C++11 (hé oui !), il y a la move semantics. Un move c'est une copie superficielle + on rend l'ancien élément "vide". En reprenant l'exemple précédent, voici comment cela fonctionne :
- on met les données dans
new_data[i] data[i]est maintenant dans un état de sorte de coquille vide
Le compilateur ne pouvait pas deviner que data[i] allait être perdu. Là, on l'a rendu "coquille vide" donc ce n'est pas grave.
Exemples
Voici des situations où C++ fait une copie alors qu'un move aurait été plus efficace, mais le compilateur ne peut pas le deviner.
- Situation où on a un nom car on utilise l'objet plusieurs fois :
{
string s("Bloup");
V.push_back(s); // là on aurait du faire move semantics car s est de toute façon détruit après le }
}
- Situation où on a un paramètre
void reinit(string& s) {
history.push_back(s); // là on aimerait avoir move semantics car s n'est plus utilisé après
s = getDefaultValue();
}
Solution
La solution est d'utiliser std::move :
{
string s("Bloup");
V.push_back(std::move(s)); // :)
}
et
void reinit(string& s) {
history.push_back(std::move(s)); // :)
s = getDefaultValue();
}
Recap
std::move(s) signifie intuitivement :
sn'est plus utile ici- tu me déplaces au lieu de me copier
- après l'appel
sest toujours un objet valide mais sa valeur est quelconque (souvent vide a priori). On peut réutiliser la variables.
void swap(string& a, string& b) {
string tmp(std::move(a));
a = std::move(b);
b = std::move(tmp);
}
Comment ça marche... que fait std::move ?
En C++, on distingue :
- les
lvalue: ce sont des noms de variables, ou des cellules mémoires adressées par un pointeur, etc. (lpour location, ou pour left) - les
rvaluequi sont des valeurs non nommés comme5,f(3)(rpour right)
On va s'appuyer sur cette distinction. En effet, les lvalue sont amenés à rester en mémoire, alors que les rvalue sont amenés à mourir vite.
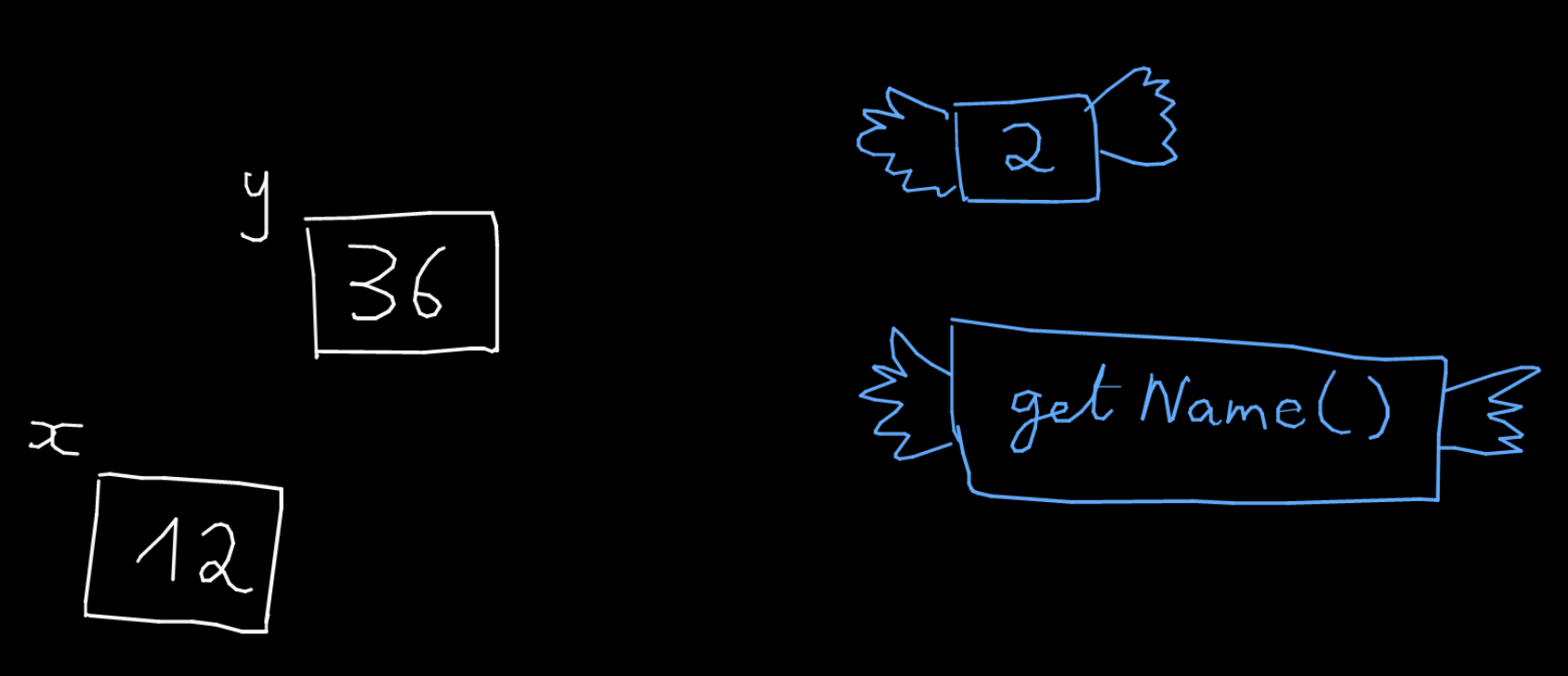
En C++, on note :
string&une référence sur unelvaluestring&&une référence sur unervalue(c'est unelvaluequi est une référence sur unervalue)
L'appel std::move(s) renvoie s mais en tant que rvalue pour dire qu'elle va mourir et donc qu'il faut faire une move semantics. En fait, std::move(s) c'est équivalent à static_cast<string&&>(y). Maintenant y, tu vas mourir !
Move semantics sur une méthode quelconque
template <typename T>
class vector {
public:
//copy elem into the vector
void push_back(const T& elem);
//**move** elem into the vector
void push_back(T&& elem);
}
void push_back(const T& elem)is called in old version of C++ ;) or in C++11 when there is a variable name in the call (e.g.V.push_back(s))- In C++11,
void push_back(T&& elem)is called when there is no name (e.g.V.push_back(2),V.push_back(getName())) or it is explicitely a moved object (e.g.V.push_back(move(s))).
Move semantics sur un constructeur
class string {
private:
int len;
char* data;
public:
// copy constructor
string(const string& a) : len(s.len) {
data = new char(len+1);
memcpy(data, s.data, len+1);
}
//move constructor
string(string&& s) : len(s.len), data(s.data) {
s.data = nullptr;
s.len = 0;
}
}
Pour aller plus loin
- https://www.thecodedmessage.com/posts/cpp-move/
- Vidéo à CPPCON 2021 sur la move semantics, dont est inspiré ce cours https://www.youtube.com/watch?v=Bt3zcJZIalk
Élision de copie
V.push_back(getStringFromClient())
getStringFromClient()renvoie un objetstringque l'on note A (il n'y a pas de variable A dans le programme)- On crée une copie A' que l'on donne à
push_back - Puis A est supprimé
Euh non, le compilateur fait une move semantics automatique dans ce cas là. On appelle ça une élision de copie.
Héritage
Exemple de déclaration
#include <iostream>
#include <vector>
using namespace std;
class Animal
{
private:
int legs;
public:
virtual void parler()
{
cout << "je sais pas parler car je suis un animal générique" << endl;
}
};
class Chat : public Animal
{
private:
int vibrissae = 6;
public:
void parler()
{
cout << "miaou" << vibrissae << endl;
i++;
}
};
class Crapaud : public Animal
{
public:
void parler()
{
cout << "crooaaaa" << endl;
}
};
Programme qui ne fonctionne pas bien
int main()
{
vector<Animal> S;
S.push_back(Chat());
S.push_back(Crapaud());
for (Animal &a : S)
{
a.parler();
}
}
Sans pointeurs, pas possible de faire du polymorphisme de sous-typage. En effet, quand on met dans une zone mémoire pour un Animal, ce qui dépasse (propre à Cat ou Frog) est juste rogné. Donc on ne peut pas appliquer des méthodes de Cat qui ne vont pas trouver les données propres à un chat. Bref, on a vraiment que des objets de la classe Animal.

Programme qui fonctionne mais bon...
En C++, on peut utiliser des pointeurs à l'ancienne et ça marche.
int main()
{
vector<Animal*> S;
S.push_back(new Chat());
S.push_back(new Crapaud());
for (Animal*& a : S)
{
a->parler();
}
}
Programme chouette
#include <memory.h>
int main()
{
vector< shared_ptr<Animal> > S;
S.push_back(shared_ptr<Animal>(new Chat()));
S.push_back(shared_ptr<Animal>(new Crapaud()));
for (shared_ptr<Animal>& a : S)
{
a->parler();
}
}
Virtual method table
C++ creates a table for each class containing a pointer for each method declared as virtual. It is called a virtual method table (or vtable, or VMT). Then each object starts with a pointer to the appropriate virtual method table.

Virtual method tables are built at compile-time and solely contains virtual methods. Non-virtual methods are just called directly, without any look-up in a vtable.
Conclusion
Copy semantics VS move semantics
| Languages | Paradigm |
|---|---|
| C | copy semantics + pointers |
| C++ | copy semantics by default + move semantics possible + pointers |
| Rust | move semantics by default + copy possible if mentionned + pointers |
| Python | pointers only |
In C, C++, assignments in general make copies by default.
x = y;`
Such a small instruction can be very cooooostly!
In Rust, assignments make move by defaut:
x = y;
//impossible to use `y` anymore!
except for types that implement the Copy trait, e.g. integers:
y = 5;
x = y;
//still possible to use `y`
In Python, variables are pointers!
x = y:
Memory managements
| Languages | Data location |
|---|---|
| C | stack & heap |
| C++ | stack & heap |
| Rust | stack & heap |
| Python/Java/Javascript etc. | Pointers to data in the heap |
| Languages | Paradigm |
|---|---|
| C | do it yourself |
| C++ | do it yourself + RAII encouraged |
| Rust | RAII |
| Python/Java/Javascript etc. | Garbage collection |
Type systems
| Languages | Paradigm |
|---|---|
| C | weak, static, no genericity |
| C++ | strong, static |
| Rust | strong, static + lifetime |
| Python | strong, dynamic (+ static gradual typing) |
I hope...
- that the C part will be useful for you in the architecture & system course in L3S2!
- that the Python part will be useful for you in the compiler course in M1S1!
- that you understand more C and Python for agregation
- that you are more fluent in programming languages for:
- your internship
- your research and/or teachr career!
Happy christmas!
Template
Problématique
On pourrait s'amuser à créer plusieurs fois la même fonction pour différents types :
int Min(int x, int y)
{
return x<y ? x : y;
}
std::string Min(std::string x, std::string y)
{
return x<y ? x : y;
}
Solution
Templates offer compile-time parametric polymorphism. The following function works for all types with < implemented.
template <class T>
T Min(T x, T y)
{
return x<y ? x : y;
}
Pareil pour les classes
template <class T>
class Stack
{
// just use T for a type
}
Automatic memory management
What is nice in Python, but also in Java, Javascript, Lisp, OCaml etc.: we do not have to explicit free the memory occupied by unused objects. It is automatic!
Reference counting
import sys
x = [1, 2]
y = x
sys.getrefcount(x)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[23], line 4
2 x = [1, 2]
3 y = x
----> 4 x.__weakref__
5 sys.getrefcount(x)
AttributeError: 'list' object has no attribute '__weakref__'
def f():
x = [1, 2]
Reference counting in CPython
See https://github.com/python/cpython/blob/3.12/Include/object.h
When a reference is created, we increment the reference counter.
/* Function to use in case the object pointer can be NULL: */
static inline void Py_XINCREF(PyObject *op)
{
if (op != _Py_NULL) {
Py_INCREF(op);
}
}
When a variable is destroyed, the reference counter is decremented. Objects with reference counting 0 are destroyed.
static inline void Py_DECREF(const char *filename, int lineno, PyObject *op)
{
if (op->ob_refcnt <= 0) {
_Py_NegativeRefcount(filename, lineno, op);
}
if (_Py_IsImmortal(op)) {
return;
}
_Py_DECREF_STAT_INC();
_Py_DECREF_DecRefTotal();
if (--op->ob_refcnt == 0) {
_Py_Dealloc(op);
}
}
Explicit deletion of a placeholder
In Python, del is destroying a variable name. It is not destroying an object, it just decrements the reference counter.
x = 2
del x
Limitation: Cyclic references
Reference counting is nice but not sufficient for freeing memory.
class Node:
def __init__(self):
self.friend = None
def f():
A = Node()
B = Node()
A.friend = B
B.friend = A
f()
Garbage collection
Garbage collection consists in freeing the memory occupied by unused objects, even when reference counting is non-zero. The garbage collector is sometimes called and performs the following algorithm called mark-and-sweep:
- mark. DFS from variables to mark reachable objects
- sweep. Free the memory of unmarked objects.
Optimisation
CPython tends to call garbage collection less frequently on old objects.
import gc
# you can call the garbage collection directly like this, but I do not see the point...
gc.collect()
Weak references
A weak reference is a reference that leaves the reference counter as it is. A weak reference does not own the object.
import sys
import weakref
class Person:
pass
x = Person()
y = weakref.ref(x)
print(y)
print(y())
sys.getrefcount(x)
<weakref at 0x7f730681aa40; to 'Person' at 0x7f7307588970>
<__main__.Person object at 0x7f7307588970>
2
Rust
Rust est un langage bas-niveau comme C, mais plus sûr et qui permet la programmation générique.
Immutabilité par défaut
#![allow(unused)] fn main() { let x = 1; x = 2; // erreur }
#![allow(unused)] fn main() { let mut x = 1; x = 2; //ok }
Types
Les types sont inférés. Pas obligé de tout dire.
#![allow(unused)] fn main() { let x = 1; }
Mais on peut aussi dire :
#![allow(unused)] fn main() { let x: i32 = 1; }
Contrairement au C, les noms des types sont clairs.
-
Qu'est ce que
i8?Un entier sur 8 bits. Un charen C. -
Qu'est ce que
u8?Un entier non signé sur 8 bits. Un unsigned charen C. -
Qu'est ce que
f64?Un flottant sur 64 bits. Un doubleen C.
Fonctions
#![allow(unused)] fn main() { fn addition(a: i32, b: i32) -> i32 { return a + b; } println!("{:?}", addition(1, 2)); }
Slices
Une slice représente une zone de la mémoire. Une slice est implémentée comme un pointeur (sur le début de la zone) muni d'un entier (la taille de la zone).
#![allow(unused)] fn main() { let A = [0, 1, 2]; println!("{:?}", A); let slice = &A[1..]; println!("{:?}", slice); }
Le & veut dire qu'on met l'adresse mémoire (et la taille) dans slice.
TODO: pourquoi on a pas besoin de déréfencer à la ligne 4 ?
Les conditionnelles sont des expressions
#![allow(unused)] fn main() { println!("{:?}", if 1 < 2 {3} else {4}); }
Pattern-matching
Le pattern maching ou filtrage par motif permet de faire une conditionnelle sur expression.
Mais attention ce code ne marche pas :
#![allow(unused)] fn main() { let s = "hello"; match s { "bonjour" => {println!("tu parles français")} "hello" => {println!("tu parles anglais")} "guten tag" => {println!("tu parles allemand")} } }
Pourquoi ne fonctionne-t-il pas d'après vous ?
On peut écrire :
#![allow(unused)] fn main() { let s = "hello"; match s { "bonjour" => {println!("tu parles français")} "hello" => {println!("tu parles anglais")} "guten tag" => {println!("tu parles allemand")} _ => {println!("tu dis n'importe quoi")} } }
#![allow(unused)] fn main() { let age: u8 = 25; match age { 0..=3 => println!("bébé"), 4..=18 => println!("mineur"), 19.. => println!("grande personne de {:?} ans", age) } }
Boucles
#![allow(unused)] fn main() { let mut i: i32 = 0; while i < 10 { println!("coucou !"); i += 1; } }
Les boucles for s'appuie sur des objets (comme 0..4) qui peuvent être converti en itérateur :
#![allow(unused)] fn main() { for i in 0..4 { println!("{}", i); } }
Enum
enum Item { Book(f64, String, i64), Mug(f64, String), Shirt(f64, String, i32, i32) } fn main() { let item = Item::Shirt(10.0, "miaou".to_string(), 0, 2); match item { Item::Book(price, title, nb_pages) => &println!("The book {} is available!", title), Item::Mug(price, design) => &println!("Mug with {} available!", design), Item::Shirt(price, design, color, size) => &println!("Shirt with {} of size {} available!", design, size), }; }
Dans un jeu vidéo au tour par tour, on peut représenter une action avec un enum :
#![allow(unused)] fn main() { enum Action { Bouger(piece: Piece, nouvelle_position: Position), Passer } }
Les structures en Rust
Des structures tuple
#![allow(unused)] fn main() { struct EntierASelectionner(i32, bool); let i = EntierASelectionner(5, false); }
Des structures classiques
#![allow(unused)] fn main() { struct Point { x: i32, y: i32 } let p = Point {x: 5, y: 2}; }
Accès aux champs
#![allow(unused)] fn main() { struct Point { x: i32, y: i32 } let p = Point {x: 5, y: 2}; println!("{}", p.x); }
Méthodes
#![allow(unused)] fn main() { struct Point { x: i32, y: i32 } impl Point { fn unitX() -> Point { return Point(1, 0) } fn norm2(&self) -> i32 { return self.x ** 2 + self.y ** 2; } } let u = Point::unitX(); let p = Point {x: 5, y: 2}; println!("{}", p.norm2()); }
Erreurs en Rust
Rappel en C
#include <stdio.h>
int main() {
FILE *f = fopen("fichier.txt","rt");
if(f == NULL) {
/** gestion de l'erreur mais
si tu veux faire n'importe
quoi et utiliser f en essayant
de lire le fichier car tu es bornée tu peux **/
}
...
}
Python
x = 0
En Rust
En Rust, File::open("fichier.txt") renvoie une valeur de type Result qui est un enum comme ça :
#![allow(unused)] fn main() { pub enum Result<T, E> { Ok(T), Err(E), } }
où T est le type de l'objet attendu (ici un fichier) et E est le type de l'erreur.
Ainsi on fait du pattern matching :
#![allow(unused)] fn main() { use std::fs::File; match File::open("fichier.txt") { Ok(f) => { /* l'ouverture s'est bien déroulée on fait mumuse avec le fichier*/ } Err(e) => { /* il y a eu une erreur et on ne peut pas faire trop de bêtise avec le fichier car on ne l'a même pas sous la main ! */ } } }
Traits
Un trait est une sorte d'interface abstraite que des types peuvent implémenter (en gros c'est une liste de méthodes).
Pouvoir être additionné
On peut additionner des i32. Le type i32 implémente le trait Add.
#![allow(unused)] fn main() { struct Point { x: i32; y: i32; } impl Add for Point { type Output = Self; fn add(self, other: Self) -> Self::Output { x: self.x + other.x, y: self.y + other.y, } } println!({}, Point { x: 1, y: 0 } + Point { x: 2, y: 3 }); }
En fait, on peut "dériver" que implémenter le trait Add se fait en utilisant le trait Add déjà implémenté sur chaque champ :
#![allow(unused)] fn main() { #[derive(Add)] struct Point2D { x: i32, y: i32, } }
Définir un trait
Contrairement aux interfaces en Java, aux classes abstraites (où tout est abstrait) en C++, Python, on peut ajouter une implémentation d'un trait sur n'importe quel type, y compris un type existant comme un entier sur 32 bits. On n'est pas obligé de modifier "une classe" pour y ajouter un trait. Par exemple :
trait Colored {
fn is_red(&self) -> bool;
}
impl Colored for i32 {
fn is_red(&self) -> bool {
return self % 2 == 0;
}
}
En Java, C++, on ne peut pas avec des classes faire cela avec de l'héritage. Il faudrait modifier la "classe i32".
Ownership
En Rust, une donnée sur le tas a un unique propriétaire. C'est lui qui se charge de libérer la mémoire.
Transfert d'ownership
Cette fonction crée un vecteur avec 5 et 12 dedans. C'est v qui est le propriétaire. En faisant, v2 = v, on met les données dans v2 qui devient le propriétaire des données. v ne possède plus rien. C'est de la move semantics.
fn main() { let v = vec![5, 12]; let v2 = v; println!("{}", v[0]); // non }
Pareil, si on appelle une fonction sur v, c'est l'argument dans f qui est le propriétaire.
#![allow(unused)] fn main() { fn f(argv: Vec<i32>) { ... } }
fn main() { let v = vec![5, 12]; f(v); println!("{}", v[0]); // non }
Une solution pourrait être que la fonction renvoie v pour que v redevienne propriétaire des données :
fn main() { let v = vec![5, 12]; v = f(v); println!("{}", v[0]); // non }
Mais ça peut être lourdingue, surtout si une fonction a plusieurs paramètres, ou si on veut renvoyer une autre valeur.
Références et emprunt
#![allow(unused)] fn main() { fn f(argv: &Vec<i32>) { ... } }
Le & permet d'emprunter des données, les utiliser, mais sans en être propriétaire. La fonction f ici ne va pas détruire le vecteur. C'est une référence. Penser une référence Rust comme un pointeur C (et pas comme une référence C++), comme une adresse mémoire.
Contrairement à C, le pointeur nul n'existe pas dans le langage Rust. (il existe dans son implémentation)
Déréférencement
Comme en C, *argv signifie les données à l'adresse argv.
fn f(argv: &Vec<i32>) { println!("{}", (*argv)[1]); } fn main() { let v = vec![5, 12]; f(&v); println!("{}", v[0]); }
Mais en fait, il y a du déférencement automatique. Donc l'étoile * peut être omise :
fn f(argv: &Vec<i32>) { println!("{}", argv[1]); } fn main() { let v = vec![5, 12]; f(&v); println!("{}", v[0]); }
Règles d'emprunt
- Une référence ne peut pas vivre plus longtemps que la variable qu'elle référence. Ce code est faux :
#![allow(unused)] fn main() { let reference: &i32; { let x = 5; reference = &x; } println!("{}", reference); }
- Autant de références immutables que l'on veut
- Au plus une référence mutable sur une variable mutable
- Impossible d'avoir une référence mutable et une autre immutable sur une même variable
Vecteurs et chaînes de caractères
| Vecteurs | Chaînes de caractères | |
|---|---|---|
| Type pour la grosse structure où on peut changer la taille | Vec<T> | String |
| Type vue mémoire (taille, pointeur) | slice<T> | str |
str
#![allow(unused)] fn main() { let x: &str = "Bonjour"; println!("{}", s); }
Attention, on ne peut pas écrire *s car *s n'a pas de taille connue à la compilation (à la compilation on ne sait pas sur combien de caractères le pointeur pointe).
String
- Pour transformer une
strenString:String::from - Pour avoir la
strtotale d'unString: on déréférence !
#![allow(unused)] fn main() { let x: &str = "Bonjour"; let s: String = String::from(x); let y: &str = &s; println!("{}", s); }
Quiz
Questions sur C
- Est-ce que c'est
int *pouint* p? - Est-ce que les tableaux dans une fonction sont stockés sur la pile ?
- Peut-on avoir un tableau A[4] dans un struct ?
- passage par valeur tableau, struct. Est-ce que ça change la valeur ?
- &A et &A[0] c'est pareil ?
- &*p = p ?
- *p et p[0] c'est pareil ?
- **p a du sens ?
- &&x a du sens ?
- type de fonctions ?
- const char * VS char * const ?
- combien de mémoire prend un pointeur ?
- pourquoi pas de tableau de taille qcq avant C99 ?
- pourquoi les arguments sont posés dans l'ordre inverse sur la pile ?
- pourquoi la pile est à l'envers dans la mémoire ?
- Est-ce que la mémoire d'un processus est limité à 4Go même pour un processus 64bits ?
- Comment coder un dictionnaire en C ? (rien dans la librairie standard, mais des choses dans glib, la librairie de GNOME)
- Pourquoi les adresses mémoire commencent par 0x ? (0 c'est pour dire que c'est une constante et x pour dire que c'est de l'hexadécimal.)
- Est-ce que &&ptr a du sens ?
- Idées d'application de variables
static?- mutex de protection de ta fonction contre des appels concurrents
- compteur d'appels
- compteur pour debug
- compteur pour comportement execptionnel (un truc à faire une fois sur dix)
- initialisation d'une constante à calculer qu'une fois (je crois que l'expression est faite/évaluée qu'au premier passage dans la fonction)
- drag and drop de souris
Questions sur Python
- Comment s'appelle les méthodes de la forme
__XXXX__comme__init__,__add__, etc. ? ("Dunder methods" or "magic methods", "méthodes spéciales") - En Python, à quoi peut servir une fonction avec yield ?
- Pour des raisons de mémoire, par exemple, lire un énorme fichier texte ligne par ligne => on fait yield
- Simuler une séquence infini
- Est-ce qu'un générateur est un itérateur ?
- Oui, mais pas l'inverse ! Un itérateur peut être plus compliqué (comme un objet où il y a aussi une méthode pour avoir l'élément courant, changer d'état etc. et pas juste next(.) ; mais s'il y a juste next(.) un générateur suffit !)
- Comment est codé le type list en Python ? Comment le tableau est dynamiquement redimensionné ?
- Comment est représenté une table de hachage pour un dictionnaire ? C'est quoi le hash d'un str, d'un tuple ?
- Est-ce que le type "immutable" existe bien ? Ou c'est juste qu'il y a un hash pour mettre dans un set ou utiliser comme key d'un dict ?
- Y-a-t-il des génériques en Python ? Oui on écrit
Sequence[Employee]par exemple.
Questions concept
- encapsulation
Questions culture générale
- En quoi était codé Super Mario Bros ? Doom ?
- En quoi est codé Firefox ?
- En quel langage est codé le noyau Linux ?
- Nom du système d'exploitation écrit en Rust ?
- En quoi est codé TeX ?
- C'est quoi big endian et little endian ? C'est utilisé où ?
Question C++
- Est-il possible d'avoir une fuite mémoire en n'utilisant que des pointeurs intelligents ?
Reviews de code - TP 1
void print_laby(int n, int m, char** A) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
printf("%c", A[i][j]);
}
printf("\n");
}
printf("\n");
}
int eratosthene(int n)
{
int *nums = malloc((n - 1) * sizeof(int));
int pi = 0;
for (int i = 0; i < n - 1; i++)
{
int x = i + 2;
if (nums[i] != -1)
{
nums[i] = x;
pi++;
printf("%d ", x);
}
for (int j = 1; j * x - 2 < n - 1; j++)
nums[j * x - 2] = -1;
}
free(nums);
printf("\n");
return pi;
}
int somme(int tab[], int taille)
{
int acc = 0;
for (int i = 0; i < taille; i++)
acc += tab[i];
return acc;
}
int somme(int tableau[], int taille) {
int i ;
int accumulateur ;
accumulateur = 0 ;
for (i=0 ; i<taille ; i++) {
accumulateur = accumulateur + tableau[i] ;
}
return accumulateur ;
}
bool est_vide_liste(liste *lst){
return lst->start == NULL;
}
Reviews de code - TP 2
gaussint lit(char *str) {
int i = 0;
gaussint ans = {0, 0};
int state = 0;
int pow = 1;
while (str[i]) {
int k = (int) str[i] - (int) '0';
if (!state && str[i] == '+') {
state = 1;
pow = 1;
i++;
} else if (k >= 0 && k <= 9) {
if (state == 1) {
ans.im += pow * k;
pow *= 10;
i++;
} else if (!state) {
ans.re += pow * k;
pow *= 10;
i++;
}
} else if (str[i] == 'i') {
if (!state) {
ans.im = ans.re;
ans.re = 0;
}
i++;
} else {
return (gaussint) {0, 0};
}
}
return ans;
}
void push(dynarray *array, element x) {
if (array->size >= array->capacity) {
element *new_data = malloc((9 * array->capacity / 8 + 4) * sizeof(element));
for (int i = 0; i < array->size; i++) {
new_data[i] = array->begin[i];
}
free(array->begin);
array->begin = new_data;
array->capacity = 9 * array->capacity / 8 + 4;
}
array->begin[array->size] = x;
array->size++;
}
void free_array(dynarray *array) {
free(array->begin);
}
element get(dynarray *tab, int i) {
assert(i < tab->size);
return tab->begin[i];
}
Glossaire
- Arguments VS paramètres : les paramètres sont les variables apparaissant dans la signature. Par exemple dans
int f(int x, char c)les paramètres sontxetc. Les arguments sont les valeurs passées lors d'un appel. Dansf(3, 'c')les arguments sont3et'c'. - Capture par valeur/référence : désigne si au moment de la création d'une lambda expression/function si une variable est remplacée par sa valeur ou si cela fait toujours référence à la variable globale
- Classe : description d'un type avec des champs et des méthodes
- Classe abstraite : classe avec des méthodes non implémentées
- Composition : relation avoir un. Par exemple : tout
Chatpossède uneMoustache. Remplace parfois l'héritage : toutChatpossède les données d'unAnimalgénéral. - Héritage : relation est un. Par exemple : tout
Chatest unAnimal - Interface : Type qui présente des méthodes à implémenter pour des sous-types.
- Lambda expression, ou fonction anonyme : fonction non nommé. Par exemple, en Python :
lambda x: 2*x. - Méthode : Fonction attachée à une classe
- Objet : instance d'une classe
- Paramètres : v ;,nbvoir Arguments VS paramètres
- Polymorphisme : Mot qui désigne un mécanisme où on écrit du code qui fonctionne pour plusieurs types. Voir polymorphisme paramétré, par sous-type, surcharge.
- Polymorphisme paramétré. Le fait d'avoir des variables
Tde types comme dansList<T>,Tree<T>. - Polymorphisme par sous-typage / par héritage. Le fait d'écrire une fonction qui marche pour tout
Animal(Chat,Crapaud, etc.) - Struct : Type qui présente des champs
- Surcharge (overloading). Un même nom de fonction utilisée pour plusieurs types :
string toString(int x),string toString(double x), etc. - Trait. (En Rust) Similaire aux interfaces Java mais peut s'appliquer à un type existant.
- Tuple : Type qui présente des champs numérotés. En Python
("bonjour", 1)est un tuple.
Projet de programmation
Vous allez être impliqué dans la réalisation d'un projet de programmation de votre choix par groupe de deux ou trois (deux préférables) personnes. Le choix du projet est libre mais la suite donne quelques idées de projets. Tous les langages sont autorisées (C, C++, Rust, Python, etc.).
Dépôt git
Dans votre dépôt git, il faut les informations suivantes dans README.md :
- titre
- noms des étudiants
- description du projet (paragraphe)
- objectifs (liste à point de quoi faire)
- technologie (languages etc.)
- description de l'état de l'art (si projet existant)
Idées de projets
MCTS Monte Carlo Tree Search
Rapidly exploring random tree et le voyageur de piano
Interpréteur Scheme
Scheme est un dialecte de Lisp, un langage fonctionnel à typage fort et dynamique. L'avantage est que les expressions sont faciles à analyser syntaxiquement (à parser) car ce sont des expressions préfixes parenthésées.
- Ecrire un interpréteur pour des expressions simples
(+ 1 2)etc. - Etendre aux définitions de fonction etc.
- Implémenter une gestion d'exception, le
call/cc - Implémenter un bidding Python/C pour appeler votre fonction C/Rust d'évaluation d'expression Scheme en Python
Multi-agent path finding
On considère un environnement qui est une grille où certaines cases contiennent des obstacles (immobiles). Un nombre n de robots occupent des positions initiales (des cases libres) et doivent se rendre à des positions finales (des cases libres aussi).
L'objectif est de construire un chemin pour chaque robot (qui se déplace horizontalement ou verticalement d'une case à chaque étape, ou reste sur place) qui l'amène de sa position initiale à sa position finale telle que :
- les robots n'entrent pas en collision
- la durée totale de la mission (le max des longueurs des chemins) soit minimale.
- Construire un programme qui permet de charger des environnements et des instances
- Développer un algorithme basé sur A*
- Implémenter l'algorithme de [https://ojs.aaai.org/index.php/AAAI/article/view/8140]
- Implémenter les améliorations de CBS
Implémentation d'un algorithme pour CLIQUE COVER
Implémenter l'algorithme proposée dans https://arxiv.org/abs/2410.03609
Débugueur en raylib (projet très libre)
L'idée est de faire un programme qui discute avec gdb et affiche le contenu de la mémoire graphiquement. J'ai commencé un prototype existant. Je pourrais vous montrer.
Apprentissage et MINST (projet très libre)
Réimplémenter l'architecture utilisé par Yann LeCun pour apprendre à reconnaître des chiffres.
Quelques idées en vrac
- programmer un jeu comme :
- block blast
- un jeu en mode terminal
- un jeu quelconque
- entiers arbitrairement grands
- algorithme de Rho de Polard
- test de Fermat
- génération de nombres premiers grands
- interpréteur LISP/langage de leur choix à écrire en C
- Diagramme de Voronoi et Delaunay
- Fractales (d'autres choses, à définir ?)
- Raytracing?
- Dancing links et backtracking
- MCTS et résolution de jeux
- Génération de niveau de Sokoban
- Génération de labyrinthes (variantes, sur une sphère etc.)
- quelque chose avec des quadtrees, quoi ?
- Voyageur de commerce et recuit simulé
- Apprentissage par renforcement
- https://fr.wikipedia.org/wiki/Algorithme_de_Bron-Kerbosch
- https://adriann.github.io/Ullman%20subgraph%20isomorphism.html
- https://nbviewer.org/urls/staff.science.uva.nl/u.endriss/teaching/ijcai-2024/sat4sct.ipynb problème de vote du tutorial de Ulle Endriss
- Composantes dans un graphe randomisé de Erdos avec faible proba, phénomène de seuil, avec algo de Kruskal (voir avec Stephan Thomassé)
- Génération d'arbres uniforme avec n sommets
- Codage de Pruffer ? Il y a une bijection entre code et arbre. On génère une suite aléatoire uniforme puis on décode
- Kruskal. Puis le diamètre de l'arbre est de taille n^{2/3}
- Génération d'arbres uniforme couvrant dans un arbre
- Marche aléatoire dans le graphe original
- on ajoute une arête dès qu'on est sur un nouveau sommet
- On prend le graphe et chaque arête c'est une résistance de 1 ohm. La résistance entre deux aretes e c'est #nb arbre courant contenant e / #nb arbre couvrant.
- Galey-Shapley
- constater les différences de choix quand c'est les hommes ou les femmes qui proposent
- lancer en moyenne
- triangulation : on peut toujours passer d'une triangulation coloriée avec des + et - à une autre avec des flips
- des algos pour trouver des vecteurs proches https://en.wikipedia.org/wiki/Vector_database
- jeu de la vie, simulation de particules (rouge s'assemble avec rouge, rouge aime vert, vert aime pas rouge etc.)
Projet pédagogique
Le but de ce projet est de s'entraîner à expliquer et à enseigner des concepts aux autres personnes de la promotion. Seul ou à deux.
Au choix.
- [COURS] Soit une présentation sur un sujet avancé
- [WIKI] Soit modification d'une page Wikipedia
- [VIDEO] Soit une vidéo, un poster
[COURS] Idées de sujets avancées
- programmation d'un émulateur NES
- Bot Discord
- Mod d'un jeu vidéo
- Shaders
- Présentation d'un langage, par exemple C#, Haskell, FORTH, etc.
- Programmation d'un OS
- Présentation d'un projet que vous avez fait
[WIKI] Page Wikipedia à modifier
Vous pouvez modifier une page, proposer des idées de figures. Voici des pistes mais toute autre proposition intéressante est la bienvenue :
- traduire https://en.wikipedia.org/wiki/Dangling_pointer
- https://fr.wikipedia.org/wiki/Threads_POSIX
- https://fr.wikipedia.org/wiki/Address_space_layout_randomization
- traduire https://en.wikipedia.org/wiki/Union_type
- traduire https://en.wikipedia.org/wiki/Global_interpreter_lock
- Nettoyer https://fr.wikipedia.org/wiki/Eval
- https://fr.wikipedia.org/wiki/R%C3%A9flexion_(informatique)
- https://fr.wikipedia.org/wiki/M%C3%A9taobjet
- https://en.wikipedia.org/wiki/Doctest
- https://fr.wikipedia.org/wiki/Conversion_de_type
- https://fr.wikipedia.org/wiki/Patron_de_conception
- https://en.wikipedia.org/wiki/Struct_(C_programming_language)
- Etendre https://fr.wikipedia.org/wiki/Pointeur_intelligent
- Etendre https://fr.wikipedia.org/wiki/Pointeur_(programmation) avec de l'histoire, des exemples
Consignes
- Pour se lancer dans un projet Wikipedia, il faut vous créer un compte Wikipedia (si ce n'est pas déjà fait).
- Attention, sur Wikipedia il faut citer des sources.
[VIDEO] Créer une vidéo
Ce projet est similaire à une présentation en cours, sauf que vous produisez une vidéo.
Annonces
25 septembre 2024
-
TD 5 ou TD 6 sera noté
-
N'ayez pas peur de raylib, c'est juste une librairie parmi d'autres
-
Projets challenge pour les élèves qui le veulent
-
Je vais essayer d'être plus lent en cours
-
Vous, posez des questions en cours. N'abandonnez pas !
-
Office hours lundi de 15h30 à 16h30 si vous avez des questions
-
Les élèves qui veulent écouter peuvent venir devant dans l'amphi et les autres (qui font les projets challenge se mettent derrière et écoutent d'une oreille)
-
SVP mettez vos codes de TPs sur vos dépôts git respectifs
2 octobre
- Commitez, pushez vos codes de TPs afin d'innonder les reviews de code du début de cours.
- TP 5 sera noté. Vous aurez les instructions de préparation au TP 4.
19 novembre
- Beaucoup de personne ne comite et pushe pas leur code. C'est pénible pour faire les reviews de code de début de cours.
- DM noté pour mercredi 27 novembre à 12h15.
- Nous envoyer (à François, Alice et moi) par mail le lien vers votre dépôt git avec vos TPs avec comme objet du mail
[PROG] git. - Implémenter Dijkstra/A* avec une classe abstraite de file de priorité et implémenter le tas binaire qui hérite de la classe abstraite. Code simple mais efficace. Vous pouvez reprendre le code du cours et ce que vous avez fait en TP. Pas besoin de faire quelque chose d'original. Mais il faut que le code écrit soit le plus propre possible : commenté, respecte à peu près les principes SOLID, des tests, typer le code.
- L'implémentation Dijkstra/A* doit être pushé sur vos TDs.
- Nous envoyer (à François, Alice et moi) par mail le lien vers votre dépôt git avec vos TPs avec comme objet du mail
- Projet Python noté par groupe de trois ou quatre personnes sur les trois prochaines séances : mardi 26 novembre, mercredi 27 novembre, mardi 3 décembre.
- Le sujet est libre mais vous trouverez deux sujets possibles https://etudes.ens-lyon.fr/course/view.php?id=6334
- Ici vous trouverez un squelette pour utiliser pygame (pour ceux celles qui veulent) : https://gitlab.aliens-lyon.fr/enslyon-l3-prog/code-vu-en-cours/-/tree/main/python_pygame?ref_type=heads
- Soutenance le mercredi 4 décembre (démonstration + questions sur le code, pas de transparents à faire).