
Ah, la mine d’informations (à portée de clic) qu’est le web! Est-ce que ça ne vous fait pas rêver? Moi, si! et c’est pourquoi je vais aujourd’hui m’aventurer à faire un peu de webmining.
S’il est possible de « scraper » (i.e. « râcler », littéralement) n’importe quel site web avec un package comme rvest (qui permet de « parser » le html, i.e. de récupérer attributs et contenus des différentes sections de ce type de documents), certains packages peuvent être plus précisément adaptés à certains sites en particuler.
Je vais ainsi m’essayer au scraping du site Wikipedia, et m’armer, pour ce faire, du package dédié nommé WikipediR.
library(WikipediR)
Il existe plusieurs sites Wikipedia en fonction de la langue que l’on considère: par exemple ‘fr.wikipedia.org’ pour des articles en français ou ‘en.wikipedia.org’ pour des articles en anglais. Notons en outre l’existence d’autres projets (à divers états d’avancement) de la Wikimedia Foundation tels que
- ‘wikiquotes’ (qui recense un certain nombre de citations, par sujets, auteurs ou oeuvres),
- ‘wikisource’ (bibliothèque de textes libres et gratuits),
- ‘wikidata’ (des données)
- ‘wiktionnaire (un dictionnaire universel)
- ‘wikimedia commons’ (des ressources multimedias, images notamment)
- ‘wikiversité’ (des ressources pédagogiques)
- ‘wikinews’ (des actualités)
- ‘wikispecies’ (des informations taxonomiques)
Toutes les fonctions de scraping du package wikipediR ont en commun, de ce fait, les arguments suivants:
- la langue du projet,
- le projet
- le domaine (remplaçant à la fois langue et projet).
Information sur une page
Récupérons tout d’abord les informations relatives à une page (disons la page du « Camembert de Normandie », qui, en tant que monument du patrimoine gastronomique français, devrait parler au plus grand nombre -et surtout à ma fidèle lectrice Ginoute-!):
myinfo=page_info(language="fr",
project="wikipedia",
page="Camembert de Normandie")
print(str(myinfo))
## List of 2
## $ batchcomplete: chr ""
## $ query :List of 1
## ..$ pages:List of 1
## .. ..$ 31542:List of 17
## .. .. ..$ pageid : int 31542
## .. .. ..$ ns : int 0
## .. .. ..$ title : chr "Camembert de Normandie"
## .. .. ..$ contentmodel : chr "wikitext"
## .. .. ..$ pagelanguage : chr "fr"
## .. .. ..$ pagelanguagehtmlcode: chr "fr"
## .. .. ..$ pagelanguagedir : chr "ltr"
## .. .. ..$ touched : chr "2017-05-28T11:03:58Z"
## .. .. ..$ lastrevid : int 133969395
## .. .. ..$ length : int 66903
## .. .. ..$ protection : list()
## .. .. ..$ restrictiontypes :List of 2
## .. .. .. ..$ : chr "edit"
## .. .. .. ..$ : chr "move"
## .. .. ..$ talkid : int 2462365
## .. .. ..$ fullurl : chr "https://fr.wikipedia.org/wiki/Camembert_de_Normandie"
## .. .. ..$ editurl : chr "https://fr.wikipedia.org/w/index.php?title=Camembert_de_Normandie&action=edit"
## .. .. ..$ canonicalurl : chr "https://fr.wikipedia.org/wiki/Camembert_de_Normandie"
## .. .. ..$ displaytitle : chr "Camembert de Normandie"
## - attr(*, "class")= chr "pageinfo"
## NULL
On peut voir ici comment récupérer la longueur de l’article, son url complète, l’identifiant de la dernière révision, etc.
Contenu d’une page
Le contenu d’une page est par ailleurs accessible de la manière suivante:
mycontent=page_content(language="fr",
project="wikipedia",
page_name="Camembert de Normandie")
print(str(mycontent))
## List of 1
## $ parse:List of 4
## ..$ title : chr "Camembert de Normandie"
## ..$ pageid: int 31542
## ..$ revid : int 133969395
## ..$ text :List of 1
## .. ..$ *: chr "<div class=\"homonymie\"><a href=\"/wiki/Aide:Homonymie\" title=\"Aide:Homonymie\"><img alt=\"Page d'aide sur l'homonymie\" src"| __truncated__
## - attr(*, "class")= chr "pcontent"
## NULL
Voyez notamment cette partie:
mycontent$parse$text$`*`
On a ici le contenu (en html « brut ») de la page wiki qui nous intéresse. Pour récupérer des éléments de ce html, on pourrait ainsi utiliser le package rvest cité plus haut (cela fera sans doute l’objet d’un prochain billet).
Mais pour le moment, intéressons-nous à des informations plus globales quant à la page wikipedia qui nous occupe ici…
Pages et catégories
Pages depuis catégories
On peut lister l’ensemble des pages de la catégorie « Fromage » depuis le site Wikipedia (France) à l’aide de la fonction pages_in_category() (je charge le package dplyr pour nettoyer un peu ma table en sortie, avant affichage…): On peut lister l’ensemble des pages de la catégorie « Fromage » depuis le site Wikipedia (France) à l’aide de la fonction pages_in_category() (je charge le package dplyr pour nettoyer un peu ma table en sortie, avant affichage…):
mypages=pages_in_category(language="fr",
project="wikipedia",
categories="Fromage",
clean_response=TRUE)
library(dplyr)
print(select(mypages,title))
## title
## 1 Fromage
## 2 Fromage industriel
## 3 Bergkäse
## 4 Savencia Fromage & Dairy
## 5 Brevibacterium linens
## 6 Cloche à fromage
## 7 Confrérie des chevaliers du taste-fromage de France
## 8 Cooper's Hill Cheese-Rolling and Wake
## 9 Couteau à fromage
## 10 Fromage à pâte molle
## 11 Fromage de jument
## 12 Fromage fermier
## 13 Fromage fumé
## 14 Fromage râpé
## 15 Fromage triple-crème
## 16 Fromage végétal
## 17 Fromarsac
## 18 Groupe Savencia
## 19 Histoire du fromage
## 20 International Cheese Awards
## 21 Laiteries Triballat
## 22 Maître fromager
## 23 Musée du fromage cheddar
## 24 Olomoucké syrecky (Olomoucké tvaruky)
## 25 Paradoxe du fromage à trous
## 26 Pivní sýr
## 27 Propionibacterium
## 28 Sirene
## 29 Smaený sýr
## 30 Substitut de fromage
## 31 Types de pâtes de fromage
## 32 Tyrosémiophilie
## 33 Catégorie:Wikipédia:ébauche fromage
## 34 Catégorie:Fabrication du fromage
## 35 Catégorie:Fromage AOP
## 36 Catégorie:Fromage de lactosérum
## 37 Catégorie:Fromage fermier
## 38 Catégorie:Fromage IGP
## 39 Catégorie:Fromage industriel
## 40 Catégorie:Fromage laitier
## 41 Catégorie:Fromager français
## 42 Catégorie:Fromage par lait
## 43 Catégorie:Liste de fromages
## 44 Catégorie:Fromage par type de pâte
## 45 Catégorie:Fromage par pays
## 46 Catégorie:Spécialité à base de fromage
Alternativement, si l’on s’intéresse par exemple au domaine Wikimedia Commons (qui pourrait vous fournir un tas de belles images de fromages), on peut procéder comme suit:
mypages=pages_in_category(domain="commons.wikimedia.org/",
categories="Cheese",
clean_response=TRUE)
print(head(select(mypages,title)))
## title
## 1 Cheese
## 2 Category:Cheese by colour
## 3 Category:Cheese by shape
## 4 Category:Cheese by country
## 5 Category:Cheese-based food
## 6 Category:Organic cheese
Notez que le recours à l’argument clean_response=TRUE permet d’obtenir en sortie un résultat tabulaire relativement clair, plutôt qu’une liste…
Catégories depuis pages
Inversement, il est possible de récupérer les catégories associées à une page à l’aide de la fonction categories_in_page():
mycategories=categories_in_page(language="fr",
project="wikipedia",
pages="Camembert de Normandie",
clean_response=TRUE)[[1]]
print(select(mycategories$categories,title))
## title
## 1 Catégorie:Appellation fromagère française
## 2 Catégorie:Camembert (fromage)
## 3 Catégorie:Fromage AOC
## 4 Catégorie:Fromage AOP
## 5 Catégorie:Fromage au lait cru
## 6 Catégorie:Fromage au lait de vache
## 7 Catégorie:Fromage de Normandie
## 8 Catégorie:Fromage fermier
## 9 Catégorie:Fromage laitier
## 10 Catégorie:Symbole de la Normandie
Liens
Le package wikipediR permet également de lister, pour une page données, les informations relatives
- aux liens de cette page vers d’autres pages du même domaine (
page_links()) - aux liens de cette page vers des pages externes (
page_external_links()) - aux liens depuis d’autres pages du même domaine vers cette page (
page_backlinks)
Liens vers d’autres pages wiki:
mylinks=page_links("fr",
"wikipedia",
page="Camembert de Normandie",
clean_response=TRUE)[[1]]$links
mylinks=do.call(rbind,mylinks)
print(mylinks)
## ns title
## [1,] "0" "1791"
## [2,] "0" "1890"
## [3,] "0" "1916"
## [4,] "0" "1982"
## [5,] "0" "1996"
## [6,] "0" "2013"
## [7,] "0" "AOC"
## [8,] "0" "Abondance (fromage)"
## [9,] "0" "Acide gras insaturé"
## [10,] "0" "Acides gras saturés"
## [11,] "0" "Affinage du fromage"
## [12,] "0" "Alpha-tocophérol"
## [13,] "0" "Années 1950"
## [14,] "0" "Années 1960"
## [15,] "0" "Appellation d'origine"
## [16,] "0" "Appellation d'origine contrôlée"
## [17,] "0" "Appellation d'origine protégée"
## [18,] "0" "Banon (fromage)"
## [19,] "0" "Basse-Normandie"
## [20,] "0" "Beaufort (fromage)"
## [21,] "0" "Bernières-d'Ailly"
## [22,] "0" "Bleu d'Auvergne"
## [23,] "0" "Bleu de Gex"
## [24,] "0" "Bleu des Causses"
## [25,] "0" "Bleu du Vercors-Sassenage"
## [26,] "0" "Bretonne pie noir"
## [27,] "0" "Brevibacterium linens"
## [28,] "0" "Brie (région)"
## [29,] "0" "Brie de Meaux"
## [30,] "0" "Brie de Melun"
## [31,] "0" "Brillat-savarin (fromage)"
## [32,] "0" "Brocciu"
## [33,] "0" "Cabécou"
## [34,] "0" "Cahier des charges"
## [35,] "0" "Caillé"
## [36,] "0" "Calcium"
## [37,] "0" "Calmann-Lévy"
## [38,] "0" "Calvados (département)"
## [39,] "0" "Camembert"
## [40,] "0" "Camembert (Orne)"
## [41,] "0" "Camembert (fromage)"
## [42,] "0" "Camembert au calvados"
## [43,] "0" "Camembert fermier"
## [44,] "0" "Cantal (fromage)"
## [45,] "0" "Chabichou du Poitou"
## [46,] "0" "Chaource (fromage)"
## [47,] "0" "Charolais (fromage)"
## [48,] "0" "Chevrotin"
## [49,] "0" "Cholestérol"
## [50,] "0" "Comté (fromage)"
La fonction page_links() (avec clean_response=TRUE) renvoie une liste qui comprend autant d’éléments que de pages indiquées en argument d’entrée (donc ici, la liste n’a qu’un seul élément correspondant à la page « camembert de Normandie »). On récupère l’élément « links ».
Cet élément est lui-même une liste, comprenant autant d’éléments qu’il y a de liens en sortie. Pour mettre le tout sous forme de tableau, on passe l’ensemble de ces éléments comme arguments à la fonction rbind() (c’est à ça que sert la deuxième commande, commençant par do.call()).
(Eh oui! le webscraping c’est sympa, mais ça demande d’être capable de manipuler des listes car on manipule des informations imbriquées, et de tailles variables…)
Liens vers des pages externes
myexternallinks=page_external_links("fr",
"wikipedia",
page="Camembert de Normandie",
clean_response=TRUE)[[1]]$extlinks
print(data.frame(myexternallinks))
## myexternallinks
## 1 http://alimentation.gouv.fr/camembert-de-normandie
## 2 http://books.google.fr/books?id=617vdru4xjkC&printsec=frontcover&hl=fr&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false
## 3 http://www.afssa.fr/TableCIQUAL/index.htm
## 4 http://www.agro-media.fr/actualite/leaop-camembert-de-normandie-en-guerre-contre-les-industriels-5791.html
## 5 http://www.cnrtl.fr/lexicographie/maturation
## 6 http://www.cra-normandie.fr/pac_lait/mono.pdf
## 7 http://www.fromage-normandie.com/fr/camembert-normandie/presentation-camembert.html
## 8 http://www.fromage-normandie.com/fr/camembert-normandie/lien-terroir.html
## 9 http://www.fromageriegillot.fr
## 10 http://www.inao.gouv.fr/public/produits/detailProduit.php?ID_PRODUIT=3270
Liens depuis d’autres pages wiki:
On peut également lister les backlinks i.e. les liens depuis d’autres pages, vers la page du Camembert de Normandie:
mybacklinks=page_backlinks("fr",
"wikipedia",
page="Camembert de Normandie",
clean_response=TRUE)
mybacklinks=do.call(rbind, mybacklinks)
print(head(mybacklinks))
## pageid ns title
## [1,] "393" "0" "Basse-Normandie"
## [2,] "1095" "0" "France"
## [3,] "1100" "0" "Liste de fromages français"
## [4,] "2663" "0" "Reblochon"
## [5,] "3752" "0" "28 avril"
## [6,] "7674" "1" "Discussion:Liste de fromages français"
Un exemple d’application
Pour finir, voici un exemple d’application (un peu sommaire certes -j’espère que la confrérie du camembert ne me fustigera pas pour mes méthodes discutables et mes conclusions hâtives!-), mais qui vous permettra peut-être un peu de vous « projeter » dans les applications possibles du package WikipediR)…
Mettons que je m’intéresse à l’ensemble des fromages AOC, et que mon hypothèse (chauvine) de travail est que le camembert de Normandie est celui qui a la plus grande importance patrimoniale. Pour corroborer mon hypothèse, je vais m’intéresser aux longueurs des articles wikipedia associés
pages_fromages_AOC= pages_in_category("fr",
"wikipedia",
categories="Fromage AOC",
clean_response=TRUE)
print(data.frame(pages_fromages_AOC$title))
## pages_fromages_AOC.title
## 1 Liste des AOC laitières
## 2 Abondance (fromage)
## 3 Banon (fromage)
## 4 Beaufort (fromage)
## 5 Berner Alpkäse
## 6 Bleu d'Auvergne
## 7 Bleu de Gex
## 8 Bleu des Causses
## 9 Bleu du Vercors-Sassenage
## 10 Bloderkäse-Sauerkäse AOC
## 11 Brie de Meaux
## 12 Brie de Melun
## 13 Brocciu
## 14 Camembert de Normandie
## 15 Cantal (fromage)
## 16 Chabichou du Poitou
## 17 Chaource (fromage)
## 18 Charolais (fromage)
## 19 Chevrotin
## 20 Comté (fromage)
## 21 Crottin de Chavignol
## 22 Emmental
## 23 Époisses (fromage)
## 24 Formaggio d'alpe ticinese
## 25 Fourme d'Ambert
## 26 Fourme de Montbrison
## 27 Glarner Alpkäse
## 28 Gruyère suisse
## 29 Laguiole (fromage)
## 30 Langres (fromage)
## 31 L'Etivaz
## 32 Livarot (fromage)
## 33 Mâconnais (fromage)
## 34 Maroilles (fromage)
## 35 Mont d'Or (fromage)
## 36 Morbier (fromage)
## 37 Munster (fromage)
## 38 Neufchâtel (fromage)
## 39 Ossau-iraty
## 40 Pélardon
## 41 Picodon
## 42 Pont-l'évêque
## 43 Pouligny-saint-pierre
## 44 Raclette (fromage)
## 45 Reblochon
## 46 Rigotte de Condrieu
## 47 Rocamadour (fromage)
## 48 Roquefort (fromage)
## 49 Saint-nectaire
## 50 Sainte-maure-de-touraine
Ici j’ai récupéré l’ensemble des titres de pages correspondant à la catégorie « Fromage AOC ». Je vais maintenant parcourir ces pages une à une et enregistrer leur longueur dans la variable longueur_pages
data=data.frame(title=pages_fromages_AOC$title,
longueur_pages=rep(NA,nrow(pages_fromages_AOC)),
stringsAsFactors=FALSE)
for (i in 1:nrow(data)){
info=page_info("fr",
"wikipedia",
page=data$title[i])
data$longueur_pages[i]=info$query$pages[[1]][["length"]]
}
data=arrange(data,longueur_pages) %>% mutate(ID=length(title):1)
print(head(data))
## title longueur_pages ID
## 1 Glarner Alpkäse 1078 50
## 2 Mâconnais (fromage) 1704 49
## 3 Berner Alpkäse 1893 48
## 4 Bloderkäse-Sauerkäse AOC 2762 47
## 5 Langres (fromage) 3386 46
## 6 Chevrotin 3686 45
Enfin, pour le plaisir des yeux, je produis un graphique pour représenter ces résultats:
library(ggplot2)
p=ggplot(data, aes(x=ID, y=longueur_pages))+
geom_bar(aes(fill=title),stat="identity",show.legend=FALSE)+
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_x_continuous(labels=data$title, breaks=data$ID)
p
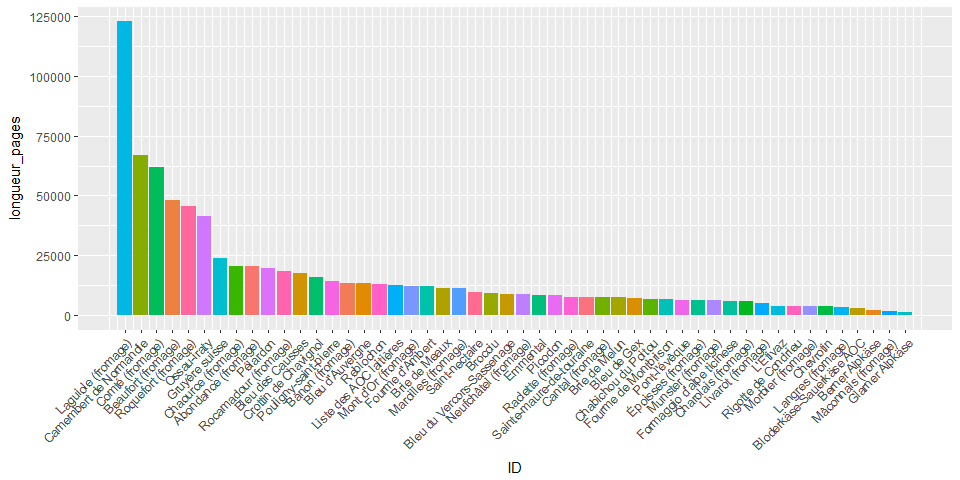
Damned! Il semble qu’un (ou plusieurs) contributeur(s) de la page relative au Laguiole ait été particulièrement inspiré (mettant à mal mon hypothèse quant à la longueur de la page « Camembert de Normandie » qui devait excéder toutes les autres…)
A la réflexion, je devrais peut-être utiliser une autre métrique que la longueur de la page pour caractériser l' »importance patrimoniale » de mes fromages… Peut-être le nombre de liens depuis les pages ou vers les pages pourrait-il mieux caractériser cette importance?
(Voyez la « démarche scientifique »: je vais m’acharner jusqu’à réussir à prouver mon hypothèse ;-))
data=data.frame(data,
nb_pages_vers=NA,
nb_pages_depuis=NA)
for (i in 1:nrow(data)){
mybacklinks=page_backlinks("fr",
"wikipedia",
page=data$title[i],
limit=500,
clean_response=TRUE)
data$nb_pages_depuis[i]=length(mybacklinks)
mylinks=page_links("fr",
"wikipedia",
page=data$title[i],
limit=500,
clean_response=TRUE)[[1]]$links
data$nb_pages_vers[i]=length(mylinks)
}
print(head(arrange(data,desc(nb_pages_vers))))
## title longueur_pages ID nb_pages_vers nb_pages_depuis
## 1 Ossau-iraty 41561 6 500 500
## 2 Comté (fromage) 61808 3 500 500
## 3 Laguiole (fromage) 122767 1 467 308
## 4 Abondance (fromage) 20546 9 390 315
## 5 Beaufort (fromage) 47885 4 362 369
## 6 Crottin de Chavignol 16008 13 354 262
print(head(arrange(data,desc(nb_pages_depuis))))
## title longueur_pages ID nb_pages_vers nb_pages_depuis
## 1 Ossau-iraty 41561 6 500 500
## 2 Comté (fromage) 61808 3 500 500
## 3 Roquefort (fromage) 45640 5 237 439
## 4 Beaufort (fromage) 47885 4 362 369
## 5 Reblochon 12973 17 230 329
## 6 Camembert de Normandie 66903 2 172 329
Une fois de plus, je ne parviens pas ici à faire valoir mon point de vue sur le camembert. Est-ce parce que j’ai tort (?!), ou bien est-ce à cause de l’existence d’une page « camembert » parallèle à la page « camembert de Normandie », ou encore est-ce lié au caractère quelque peu « ubiquiste » » du camembert (qui en ferait un fromage un peu moins « patrimonialement connecté » sur Wikipedia?). Je ne saurais le dire, en l’état, et pour tout vous dire je vais laisser cette question en suspens car ce billet est déjà très long!.
En revanche, je ne résiste pas à la tentation de vous montrer que à l’étranger au moins, le camembert est bien le fromage-ambassadeur de la France:
pages_French_cheeses=pages_in_category("en",
"wikipedia",
categories="French cheeses", clean_response=TRUE)
data=data.frame(title=pages_French_cheeses$title,
longueur_pages=rep(NA,nrow(pages_French_cheeses)),
nb_pages_vers=NA,
nb_pages_depuis=NA,
stringsAsFactors=FALSE)
for (i in 1:nrow(data)){
info=page_info("en",
"wikipedia",
page=data$title[i])
data$longueur_pages[i]=info$query$pages[[1]][["length"]]
mybacklinks=page_backlinks("en",
"wikipedia",
page=data$title[i],
limit=500,
clean_response=TRUE)
data$nb_pages_depuis[i]=length(mybacklinks)
mylinks=page_links("en",
"wikipedia",
page=data$title[i],
limit=500,
clean_response=TRUE)[[1]]$links
data$nb_pages_vers[i]=length(mylinks)
}
data=arrange(data,desc(longueur_pages)) %>% mutate(ID=length(title):1)
print(head(data))
## title longueur_pages nb_pages_vers nb_pages_depuis ID
## 1 List of French cheeses 10595 216 500 50
## 2 Brie 10560 124 319 49
## 3 Bleu des Causses 9333 244 128 48
## 4 Camembert 8826 118 211 47
## 5 Comté cheese 6947 102 103 46
## 6 Époisses de Bourgogne 5846 113 112 45
What??? Oh, non!! le fromage français qui suscite le plus d’explications sur Wikipedia en anglais, ce n’est pas le camembert, mais le brie!!
Décidemment, la rédaction de ce billet m’a réservé bien des désillusions (sur le monde qui ne se conforme pas à mes hypothèses, sur mon acharnement qui se révèle vain, sur le camembert qui n’écrase pas tout sur son passage).
J’espère tout de même que ce billet permettra à certains d’entre vous d’envisager de travailler avec les connaissances collaboratives complexes, mais riches, qu’offrent Wikipedia et consorts!
2 Comments
Simon
Je ne suis pas certain de ce que je vais pouvoir faire du savoir acquis en lisant ce post. Mais j’ai bien ri à la lecture de l’exemple d’application.
Merci encore !
lvaudor
🙂