Chapitre 7 Rechercher des thèmes (topic modelling)
La recherche de thèmes dans un corpus de textes (plus connu en tant que “topic modelling” en anglais) consiste à identifier un certain nombre de thématiques ou sujets sous-jacents, reflétés dans les textes par l’utilisation privilégiée de certains mots. En d’autres termes, les thèmes (ou topics) sont définis et désignés comme des listes de mots.
Il existe plusieurs méthodes et plusieurs algorithmes pour réaliser une recherche de thèmes, mais dans cette partie je me focaliserai sur le Structural Topic Modelling (STM) et sur sa mise en oeuvre à l’aide du package R stm (Roberts, Stewart, and Tingley 2019).
La vignette de ce package, qui détaille la méthode (algorithme) et sa mise en oeuvre sous R peut être consultée ici.
Les explications de Julia Silge, ici et là sur la méthode et sa mise en oeuvre dans le cadre du tidyverse et de tidytext peuvent également servir…
7.1 Principe, notations, algorithme
Partie à compléter!!
On note
- \(K\) le nombre total de thèmes
- \(P\) le nombre total de mots
- \(N\) le nombre total de documents
Scores \(\beta\) (beta)
On note \(\beta_{k,p}\) la probabilité conditionnelle d’un mot \(p\) pour un thème \(k\)
On peut ainsi représenter les scores \(\beta_{k,p}\) comme une matrice (ou un tableau) \(K*P\) (thèmes x mots distincts dans le corpus).
Ainsi, pour faire simple, on peut noter ces coefficients \(\beta_{k,p}\), mais si vous voulez “visualiser” ces coefficients pour comprendre la suite gardez à l’esprit qu’ils se présentent en fait comme suit:
| \(w_1\) | … | \(w_p\) | … | \(w_P\) | |
|---|---|---|---|---|---|
| \(T_1\) | … | … | … | … | … |
| … | … | … | … | … | … |
| \(T_k\) | … | … | \(\beta_{k,p}\) | … | … |
| … | … | … | … | … | … |
| \(T_K\) | … | … | … | … | … |
FREX
\(FREX\) FRequence and Exclusivité
Le score \(FREX_{k,p}\) d’un mot \(p\) pour un thème \(k\) est:
\[FREX_{k,p}=\left(\frac{w}{F}+\frac{1-w}{E}\right)^{-1}\]
- \(w\) est un poids (choisi entre 0 et 1) qui détermine la part du score \(FREX\) qui correspond à la fréquence (\(F\)) et la part correspondant à l’exclusivité (\(E\))
- \(F\) est le score correspondant à la fréquence, et reflète la probabilité du mot conditionnellement au thème.
- \(E\) est le score correspondant à l’exclusivité , et reflète la probabilité du thème conditionnellement au mot.
Etapes du STM
Le STM repose sur la génération de documents selon le modèle suivant:
- on tire au hasard une distribution des thèmes pour chaque document \(\theta_k\). On peut si on le souhaite, utiliser les métadonnées pour effectuer un tirage autour de moyennes liées à ces métadonnées (i.e. on considère que les métadonnées orientent plutôt vers tel ou tel thème).
- on calcule pour chaque document les valeurs \(\beta_{k,p}\) (donc on a N matrices à calculer, une pour chaque document)
- pour chaque mot dans chaque document,
- on tire un thème \(k\) en fonction de la distribution calculée à l’étape 1
- en se basant sur ce thème \(k\) on tire au hasard un mot à l’aide des valeurs \(\beta_{k,p}\)
Ainsi, partant de \(\theta_k\) et de \(K\) documents, on génère \(K\) nouveau documents.
On itère jusqu’à la convergence du modèle.
7.2 Mise en oeuvre
Considérons une autre manière de représenter l’information textuelle contenue par la table tib_lemmes. Nous allons compter le nombre d’occurences de chaque lemme (lemma) dans chaque document (doc) et mettre cette information sous forme de matrice \(N*p\) (le nombre de documents * le nombre total de lemmes distincts). Nous allons néanmoins exercer un tri préliminaire en retirant les mots qui sont rares à l’échelle du corpus (ici, on ne garde que ceux pour lesquels la fréquence>20).
Il s’agit d’une sorte de tableau lexical pour une partition du corpus qui correspondrait au document.
La matrice résultante est dite “sparse” car beaucoup de ses cases ont pour valeur 0 (i.e. beaucoup de mots ne se trouvent que dans quelques documents).
La fonction cast_sparse() du package tidytext permet d’effectuer ce reformatage très facilement:
tib_sparse=tib_lemmes %>%
group_by(lemma) %>% # compte pour chaque lemme...
mutate(n=n()) %>% # ...son nombre d'occurrences puis
filter(n>20) %>% # retire ceux représentés moins de 20 fois dans le corpus
ungroup() %>%
cast_sparse(row=doc, column=lemma, value=n)
dim(tib_sparse)## [1] 2867 2403tib_sparse est bien une matrice de N=2868 lignes (le nombre de documents) et de p=2496 colonnes (le nombre de lemmes dont la fréquence dans le corpus est >20)
7.2.1 Calcul du modèle
Chargeons le package stm et faisons tourner l’algorithme STM sur notre table, en demandant une quinzaine de thèmes distincts (cela peut sembler beaucoup mais les thèmes abordés par notre corpus sont de fait assez divers):
library(stm)
set.seed(123)
topic_model<-stm(tib_sparse,K=15, verbose=FALSE)Le calcul du STM se fait de manière itérative. Ici, il a fallu un certain nombre d’itérations (ici une centaine) pour que le modèle converge. Pour donner un ordre de grandeur, il a fallu quelques minutes sur ma machine pour obtenir le résultat.
Les objets stm sont associés à une méthode summary() qui permet de visualiser les thèmes identifiés:
summary(topic_model)## A topic model with 15 topics, 2867 documents and a 2403 word dictionary.## Topic 1 Top Words:
## Highest Prob: grand, hui, objectif, loi, aller, prendre, nouveau
## FREX: hui, remercier, donner, responsabilité, clair, penser, exemple
## Lift: redire, sembler, télécharger, foi, sentiment, époque, parler
## Score: loi, hui, objectif, travail, sentir, grand, européen
## Topic 2 Top Words:
## Highest Prob: presse, ministre, accréditer, rendre, charger, sanitaire, condition
## FREX: adresse, geste, suivant, sanitaire, règle, communication, barrière
## Lift: distanciation, pièce, physique, adresse, strict, retransmettre, barrière
## Score: presse, accréditer, ministre, distanciation, charger, barrière, sanitaire
## Topic 3 Top Words:
## Highest Prob: développement, entreprise, économie, nouveau, acteur, filière, transition
## FREX: filière, entreprise, innovation, développement, industriel, circulaire, économie
## Lift: actif, chimie, incubateur, compétitivité, filière, innovation, leader
## Score: développement, filière, entreprise, actif, économie, innovation, transition
## Topic 4 Top Words:
## Highest Prob: occasion, européen, français, ministère, cadre, public, matière
## FREX: occasion, européen, ministère, français, organiser, matière, international
## Lift: intégralité, occasion, séminaire, suédois, homologue, européen, bilatéral
## Score: occasion, européen, français, ministère, international, cadre, public
## Topic 5 Top Words:
## Highest Prob: énergie, énergétique, permettre, transition, mettre, objectif, logement
## FREX: énergie, énergétique, rénovation, électricité, bâtiment, ménage, logement
## Lift: article, chaudière, tertiaire, chauffer, électricité, énergie, toiture
## Score: énergie, énergétique, article, rénovation, logement, transition, permettre
## Topic 6 Top Words:
## Highest Prob: ministre, travail, charger, public, premier, acteur, cadre
## FREX: travail, réunion, représentant, réunir, délégué, groupe, proposition
## Lift: député, impayé, travail, locatif, réunion, parlementaire, syndical
## Score: ministre, travail, député, charger, délégué, acteur, réunion
## Topic 7 Top Words:
## Highest Prob: action, climatique, objectif, changement, engager, permettre, biodiversité
## FREX: action, climatique, changement, lutte, climat, carbone, biodiversité
## Lift: dollar, instrument, dérèglement, paix, déforestation, action, africain
## Score: action, climatique, changement, biodiversité, objectif, climat, carbone
## Topic 8 Top Words:
## Highest Prob: projet, permettre, loi, appel, cadre, nouveau, premier
## FREX: projet, appel, loi, lauréat, réalisation, financer, retenir
## Lift: synthèse, projet, lauréat, sélection, jury, appel, maître
## Score: projet, loi, appel, permettre, lauréat, cadre, investissement
## Topic 9 Top Words:
## Highest Prob: territoire, collectivité, local, acteur, service, public, objectif
## FREX: territoire, collectivité, local, territorial, élu, association, construire
## Lift: cérémonie, territoire, collectivité, territorial, local, quarantaine, ingénierie
## Score: territoire, collectivité, local, objectif, acteur, territorial, public
## Topic 10 Top Words:
## Highest Prob: écologique, ministre, mettre, solidaire, permettre, transition, ministère
## FREX: écologique, solidaire, produit, hui, mettre, déchet, secrétaire
## Lift: faux, poubelle, décharge, don, fléau, récompenser, écologique
## Score: écologique, solidaire, ministre, mettre, transition, permettre, hui
## Topic 11 Top Words:
## Highest Prob: ministre, écologique, presse, solidaire, accréditer, rendre, secrétaire
## FREX: carte, numéro, indiquer, solidaire, presse, accréditer, secrétaire
## Lift: fédéral, numéro, portable, carte, mail, germain, indiquer
## Score: presse, accréditer, écologique, solidaire, ministre, numéro, carte
## Topic 12 Top Words:
## Highest Prob: transport, mettre, service, permettre, charger, place, mobilité
## FREX: transport, ferroviaire, mobilité, baptiste, aérien, service, infrastructure
## Lift: transporteur, cabotage, transport, détachement, fret, drone, employeur
## Score: transport, charger, mettre, ferroviaire, permettre, baptiste, routier
## Topic 13 Top Words:
## Highest Prob: national, public, plan, acteur, biodiversité, grand, premier
## FREX: national, mer, stratégie, naturel, biodiversité, protection, protéger
## Lift: export, chasseur, mammifère, loup, classement, chasse, cétacé
## Score: national, biodiversité, stratégie, protection, français, public, acteur
## Topic 14 Top Words:
## Highest Prob: mettre, permettre, niveau, mesure, prendre, nouveau, place
## FREX: risque, niveau, compte, mesure, situation, assurer, prendre
## Lift: sécurisation, précaution, allocataire, raffinerie, séisme, stock, substance
## Score: niveau, mettre, permettre, mesure, prendre, risque, sanitaire
## Topic 15 Top Words:
## Highest Prob: national, grand, niveau, route, mettre, circulation, pays
## FREX: autoroute, circulation, classer, départ, heure, dimanche, difficulté
## Lift: danger, orange, classer, min, regagner, prudence, vacancier
## Score: national, autoroute, circulation, niveau, classer, danger, sentirChacun des thèmes est identifié par des termes privilégiés (selon plusieurs métriques différentes: Highest probability i.e. \(beta\), FREX, lift, score)…
termes_thematiques=tidy(topic_model, matrix="beta") %>%
group_by(topic) %>%
slice_max(beta,n=10) %>%
mutate(rank=row_number()) %>%
arrange(topic,desc(beta)) %>%
ungroup()
termes_thematiques## # A tibble: 150 × 4
## topic term beta rank
## <int> <chr> <dbl> <int>
## 1 1 grand 0.0322 1
## 2 1 hui 0.0281 2
## 3 1 objectif 0.0257 3
## 4 1 loi 0.0230 4
## 5 1 aller 0.0194 5
## 6 1 prendre 0.0176 6
## 7 1 nouveau 0.0145 7
## 8 1 travail 0.0140 8
## 9 1 engager 0.0138 9
## 10 1 année 0.0123 10
## # … with 140 more rowsggplot(termes_thematiques %>%
mutate(topic=as.factor(topic)) %>%
mutate(term=reorder_within(term,by=beta,within=topic)),
aes(x=beta,y=term, fill=topic))+
geom_bar(stat="identity")+
facet_wrap(facets=vars(topic), scales="free")+
theme(legend.position="none")+
scale_y_reordered()
7.3 Assignation d’un thème aux documents
Si la matrice “beta” correspond à la probabilité d’un terme dans un thème, on s’intéresse également à la probabilité qu’un document s’inscrive dans un thème. Cette probabilité est donnée par la matrice gamma:
tib_gamma <- tidy(topic_model, matrix = "gamma") %>%
arrange(document,desc(gamma))
head(tib_gamma, n=15)## # A tibble: 15 × 3
## document topic gamma
## <int> <int> <dbl>
## 1 1 11 0.510
## 2 1 4 0.324
## 3 1 2 0.166
## 4 1 6 0.0000119
## 5 1 3 0.00000553
## 6 1 15 0.00000462
## 7 1 10 0.00000404
## 8 1 12 0.00000362
## 9 1 7 0.00000341
## 10 1 13 0.00000302
## 11 1 9 0.00000282
## 12 1 14 0.00000229
## 13 1 5 0.00000218
## 14 1 8 0.000000893
## 15 1 1 0.000000568Considérons par exemple le sujet 2 qui correspond vraisemblablement à une thématique autour de la mobilité d’après les termes affichés par summary()
tib_gamma %>%
group_by(topic) %>%
slice_max(n=10,gamma) %>%
filter(topic==2)## # A tibble: 10 × 3
## # Groups: topic [1]
## document topic gamma
## <int> <int> <dbl>
## 1 252 2 1.00
## 2 1424 2 1.00
## 3 767 2 1.00
## 4 2485 2 1.00
## 5 240 2 0.977
## 6 60 2 0.955
## 7 315 2 0.933
## 8 23 2 0.933
## 9 165 2 0.913
## 10 815 2 0.911Parmi les documents qui s’inscrivent le mieux dans cette thématique, on a le document 2832. Vérifions le contenu textuel de ce document:
tib_textes %>%
filter(doc=="doc2832") %>%
pull(texte)## [1] "A la suite de la remise le 27 juillet dernier du rapport de _Michel_Delebarre_ sur le désenclavement du _Limousin_ et des territoires limitrophes, _Elisabeth_Borne_, _Ministre_ chargée des _Transports_, a reçu jeudi 28 septembre les élus locaux concernés, comme elle s' y était engagée. _Ce_ rapport, qui fait suite à l' annulation le 15 avril 2016 de la déclaration d' utilité publique sur le projet de ligne à grande vitesse _Poitiers_-Limoges, préconise des solutions alternatives pour améliorer l' accessibilité de ces territoires. Il préconise notamment à court terme la poursuite de la modernisation de la ligne ferroviaire _Paris_-Orléans-Limoges-Toulouse (POLT) et à moyen terme le raccordement de _Limoges_ à la ligne à grande vitesse _Tours_ – _Bordeaux_ (LGV _SEA_) grâce à la mise à niveau de la ligne existante _Poitiers_ – _Limoges_. Cette réunion a permis d' échanger collectivement sur ces conclusions, en présence des élus de l' ensemble des territoires concernés, des services de l' _Etat_ (préfets, administration) et des représentants de la _SNCF_. Elisabeth _Borne_ a réaffirmé sa détermination à améliorer la qualité de la desserte et de l' accessibilité de cette région. A ce titre, elle a confirmé les travaux de modernisation de la ligne _POLT_, avec un programme de plus de 1 _Md_€ engagé sur 2015-2025. Elle a demandé à _SNCF_Réseau_ de présenter un programme de modernisation de la ligne existante entre _Poitiers_ et _Limoges_ ainsi que les gains qui en résulteraient en matière d' accessibilité et de temps de parcours. Elle s' est engagée à étudier les modalités d' une desserte aérienne adaptée aux besoins des territoires, et notamment de _Limoges_. Un point sera fait au printemps 2018 sur l' ensemble de ces sujets, et notamment sur le schéma directeur de la ligne _POLT_ en cours de préparation, ainsi que sur le programme qui pourrait être mis en œuvre pour la mise à niveau de la ligne existante afin d' accéder à la _LGV_SEA_ via _Poitiers_."Pour cet exemple, c’est plutôt convaincant!
Pour analyser l’information relative aux thématiques à l’échelle du document, il peut être utile de “ré-étiqueter” les thèmes non pas en topic 1, 2, 3, etc. mais en utilisant les termes qui leurs sont spécifiques:
thematiques=termes_thematiques %>%
group_by(topic) %>%
nest()%>%
summarise(topic_terms=map(data, ~paste(.$term,collapse=", "))) %>%
unnest()
thematiques## # A tibble: 15 × 2
## topic topic_terms
## <int> <chr>
## 1 1 grand, hui, objectif, loi, aller, prendre, nouveau, travail, engager, …
## 2 2 presse, ministre, accréditer, rendre, charger, sanitaire, condition, c…
## 3 3 développement, entreprise, économie, nouveau, acteur, filière, transit…
## 4 4 occasion, européen, français, ministère, cadre, public, matière, prése…
## 5 5 énergie, énergétique, permettre, transition, mettre, objectif, logemen…
## 6 6 ministre, travail, charger, public, premier, acteur, cadre, rendre, en…
## 7 7 action, climatique, objectif, changement, engager, permettre, biodiver…
## 8 8 projet, permettre, loi, appel, cadre, nouveau, premier, public, grand,…
## 9 9 territoire, collectivité, local, acteur, service, public, objectif, pe…
## 10 10 écologique, ministre, mettre, solidaire, permettre, transition, minist…
## 11 11 ministre, écologique, presse, solidaire, accréditer, rendre, secrétair…
## 12 12 transport, mettre, service, permettre, charger, place, mobilité, publi…
## 13 13 national, public, plan, acteur, biodiversité, grand, premier, cadre, f…
## 14 14 mettre, permettre, niveau, mesure, prendre, nouveau, place, année, ser…
## 15 15 national, grand, niveau, route, mettre, circulation, pays, information…Dès lors, on peut essayer d’analyser l’occurrence de ces thématiques en fonction d’une ou plusieurs covariables issues des métadonnées
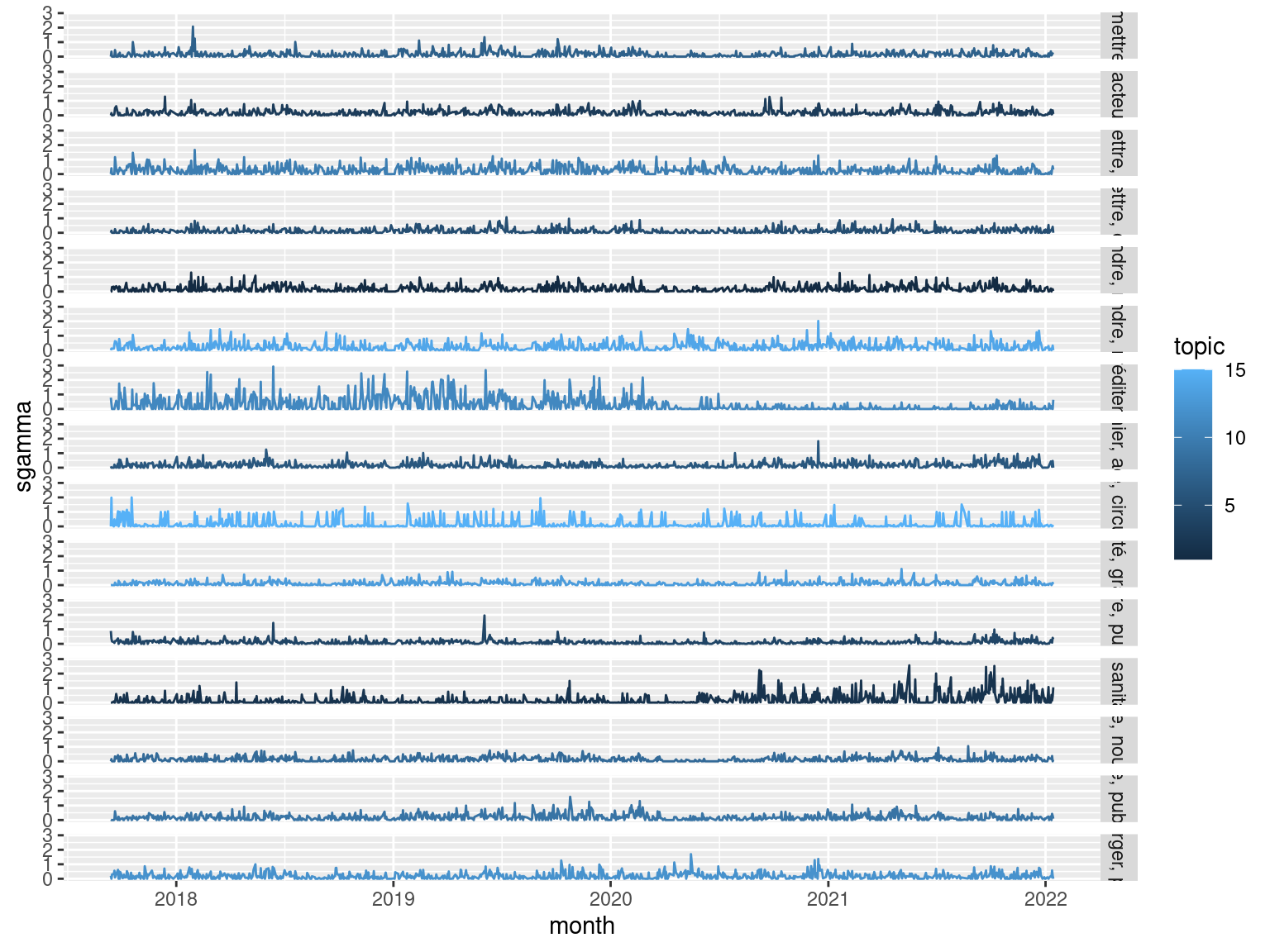
tib_meta_thematiques=tib_meta %>%
mutate(month=lubridate::ymd(date)) %>%
left_join(mutate(tib_gamma, doc=paste0("doc",document))) %>%
left_join(thematiques,by="topic") %>%
group_by(month,topic,topic_terms) %>%
summarise(sgamma=sum(gamma)) %>%
ungroup() %>%
na.omit()
ggplot(tib_meta_thematiques,
aes(x=month,y=sgamma,col=topic))+
geom_path()+
facet_grid(rows=vars(topic_terms))