Chapitre 3 Manipuler des strings: package stringr
Par exemple, à l’aide du package stringr (Wickham 2022)
![]()
Billet de blog ici.
3.1 Strings
3.1.1 concaténation
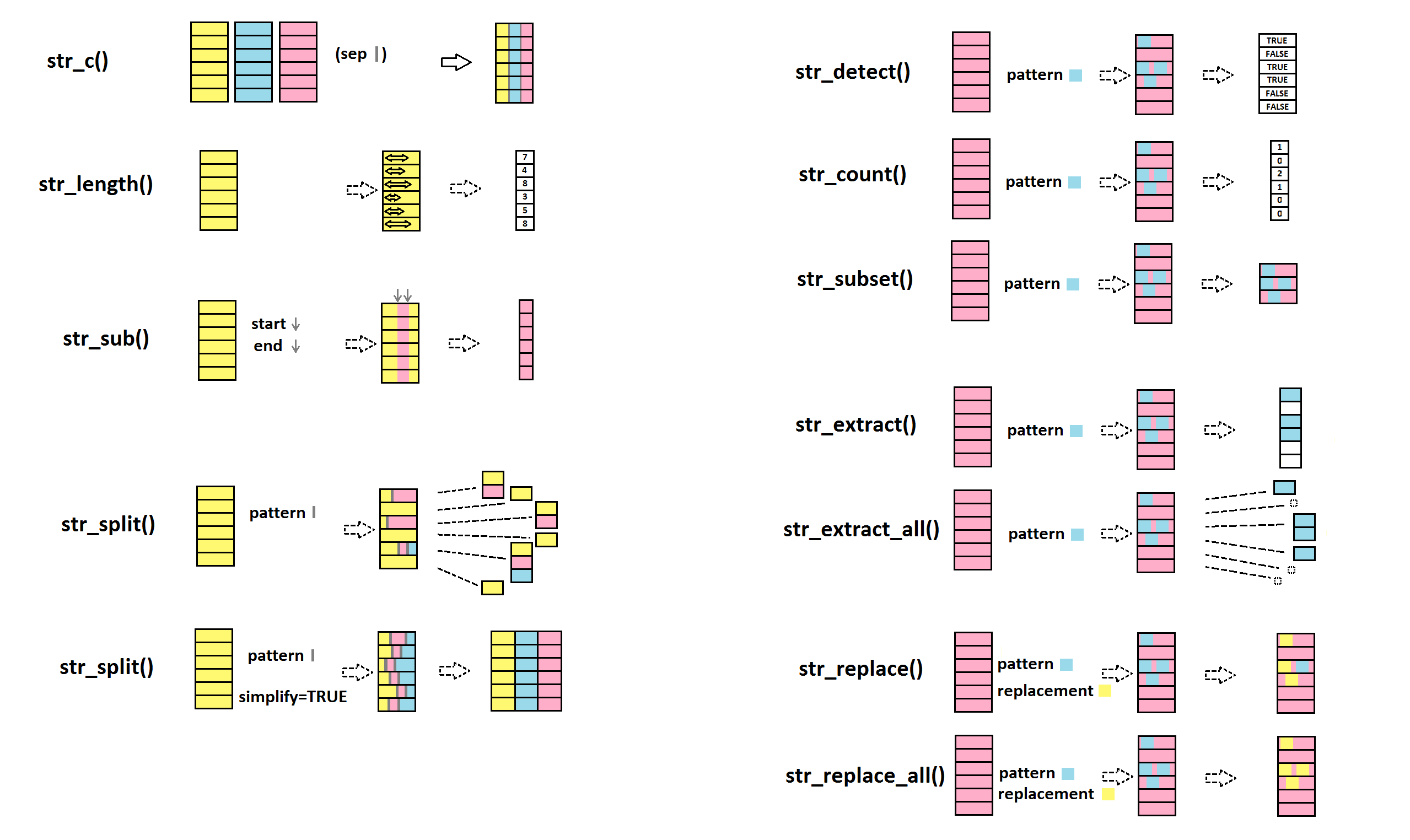
str_c() pour combiner des strings
stringr::str_c("abra","ca","dabra")## [1] "abracadabra"stringr::str_c("Les jeux","de mots laids","sont pour","les gens bêtes", sep=" ")## [1] "Les jeux de mots laids sont pour les gens bêtes"3.1.2 détection, remplacement
str_detect() détecte un pattern

stringr::str_detect(c("Quarante","carottes","crues",
"croient","que","croquer",
"crée","des","crampes."),
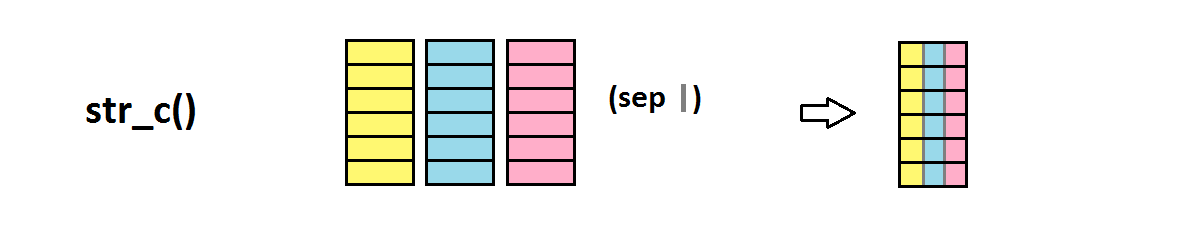
pattern="cr")## [1] FALSE FALSE TRUE TRUE FALSE TRUE TRUE FALSE TRUEstr_replace() remplace le pattern par un autre motif
stringr::str_replace("All we hear is Radio ga ga Radio goo goo Radio ga ga",
pattern="goo",
replacement="ga")## [1] "All we hear is Radio ga ga Radio ga goo Radio ga ga"stringr::str_replace_all("All we hear is Radio ga ga Radio goo goo Radio ga ga",
pattern="goo",
replacement="ga")## [1] "All we hear is Radio ga ga Radio ga ga Radio ga ga"Là encore, notez la différence entre str_replace() et str_replace_all()!!
3.1.3 division, correspondance
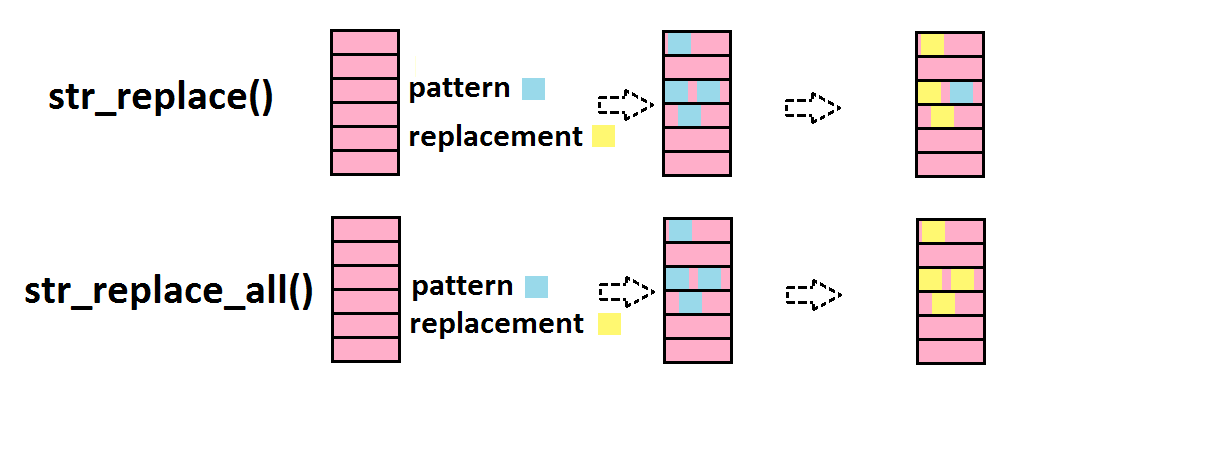
str_split() découpe les strings partout où un pattern (ou motif) est présent
stringr::str_split(c("beau_gros_chat",
"joli_chien",
"vilain_petit_canard"),
"_")## [[1]]
## [1] "beau" "gros" "chat"
##
## [[2]]
## [1] "joli" "chien"
##
## [[3]]
## [1] "vilain" "petit" "canard"Le pattern (ici “_“) peut être présent un nombre variable de fois, donc les éléments en sortie ne sont pas forcément de la même taille. C’est pourquoi cette fonction renvoie une liste.
En revanche, si l’on sait que tous les éléments de l’input seront découpés en autant de morceaux, alors on peut demander une sortie sous forme de matrice, plus pratique à manipuler par la suite, à l’aide de l’argument simplify=TRUE.
stringr::str_split(c("beau_gros_chat",
"joli_petit_chien",
"vilain_petit_canard"),
"_",
simplify=TRUE)## [,1] [,2] [,3]
## [1,] "beau" "gros" "chat"
## [2,] "joli" "petit" "chien"
## [3,] "vilain" "petit" "canard"Cette opération est un peu similaire à celle que réalise la fonction str_match(), que l’on abordera un peu plus tard…
3.1.4 extraction
str_extract() extrait le pattern (là où il est présent)
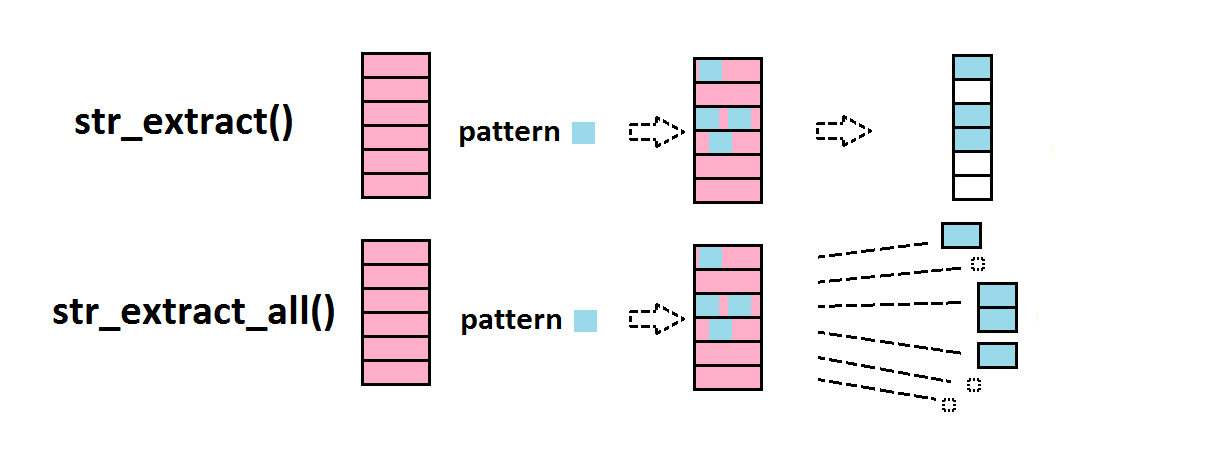
stringr::str_extract(c("L'âne","Trotro","trotte","à une allure",
"traitreusement","tranquille"),
pattern="tr")## [1] NA "tr" "tr" NA "tr" "tr"Notez la différence entre str_extract() et str_extract_all():
stringr::str_extract_all(c("L'âne","Trotro","trotte","à une allure",
"traitreusement","tranquille"),
pattern="tr")## [[1]]
## character(0)
##
## [[2]]
## [1] "tr"
##
## [[3]]
## [1] "tr"
##
## [[4]]
## character(0)
##
## [[5]]
## [1] "tr" "tr"
##
## [[6]]
## [1] "tr"Si un pattern est présent plusieurs fois dans un des éléments du vecteur en input, alors il correspondra à plusieurs éléments dans l’output (ainsi l’output correspond non pas à un vecteur de même taille que l’input, mais à une liste).
3.1.5 comptage, subset
str_count() compte les occurrences d’un pattern

stringr::str_count(c("L'âne","Trotro","trotte","à une allure","traitreusement","tranquille"),
pattern="tr")## [1] 0 1 1 0 2 1str_subset() crée un subset du vecteur où le pattern est présent

stringr::str_subset(c("Quarante","carottes","crues",
"croient","que","croquer",
"crée","des","crampes."),
pattern="cr")## [1] "crues" "croient" "croquer" "crée" "crampes."3.1.6 longueur, sous-partie
str_length() compte le nombre de caractères dans un string

stringr::str_length("anticonstitutionnellement")## [1] 25** str_sub()** extrait les caractères de la chaîne, de l’emplacement start à l’emplacement end

stringr::str_sub("youpiyaya",start=1,end=5)## [1] "youpi"stringr::str_sub("youpiyaya",start=-4)## [1] "yaya"stringr::str_sub("youpiyaya",start=4)## [1] "piyaya"3.2 Expressions régulières
Les expressions régulières servent à effectuer des recherches de patterns dans les strings en définissant les règles qui régissent ces patterns.Un tuto ici
 .
.
3.2.1 classes de caractères et groupes
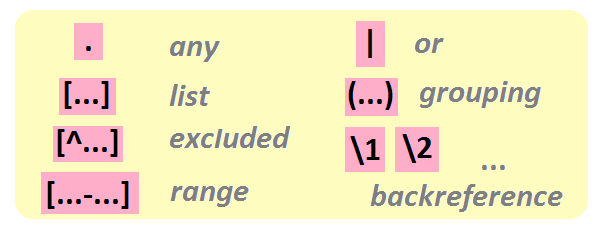
On peut rechercher une classe de caractères en utilisant la notation [...].
Par exemple, si je veux rechercher toutes les voyelles dans mon string:
stringr::str_view_all("youp la boum",
"[aeiou]")## Warning: `str_view()` was deprecated in stringr 1.5.0.
## ℹ Please use `str_view_all()` instead.## [1] │ y<o><u>p l<a> b<o><u>mRemarquez bien la différence:
stringr::str_view_all("A132-f445-e34-C308-M2244-Z449-E18",
"[308]")## [1] │ A1<3>2-f445-e<3>4-C<3><0><8>-M2244-Z449-E1<8>stringr::str_view_all("A132-f445-e34-C308-M2244-Z449-E18",
"308")## [1] │ A132-f445-e34-C<308>-M2244-Z449-E18Si l’on veut désigner un caractère quelconque, alors on peut utiliser la notation ..
Par exemple, si l’on souhaite rechercher n’importe quel caractère (excepté le retour à la ligne) suivi d’une lettre minuscule:
stringr::str_view_all("32a-B44-552-98eEf",
".[a-z]")## [1] │ 3<2a>-B44-552-9<8e><Ef>3.2.2 caractères spéciaux
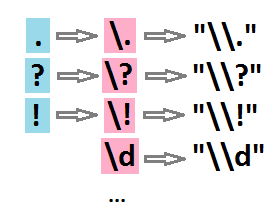
Si je veux trouver tous les points, points d’interrogation ou points d’exclamation:
stringr::str_view_all(c("Allô, John-John? Ici Joe la frite. Surprise!"),
"[\\.\\?\\!]")## [1] │ Allô, John-John<?> Ici Joe la frite<.> Surprise<!>Remarquez qu’on ne cherche pas le pattern "[.?!]", mais le pattern "[\\.\\?\\!]".
. (comme nous l’avons vu précédemment), mais aussi ? et ! sont des caractères spéciaux dans le cadre des expressions régulières. Donc, pour dire qu’on parle d’un “vrai” point, point d’interrogation ou point d’exclamation, on utilise l’escape character \. L’expression régulière est donc [\.\?\!]…
Mais on ne s’arrête pas là… En effet, ce n’est pas directement une expression régulière que l’on passe à la fonction, mais plutôt une chaîne de caractères qui est elle-même “transformée” en expression régulière… Il faut donc utiliser l’escape character \ devant les \. Et voilà comment on se retrouve à passer le pattern "[\\.\\?\\!]".
3.2.3 caractères exclus, gammes de caractères
On peut définir une classe de caractères en listant les caractères qu’elle inclut, mais également en listant l’ensemble des caractères exclus en utilisant la notation [^...]:
Par exemple, pour trouver tous les caractères qui ne sont ni une voyelle ni un espace:
stringr::str_view_all("turlututu chapeau pointu",
"[^aeiou ]")## [1] │ <t>u<r><l>u<t>u<t>u <c><h>a<p>eau <p>oi<n><t>uEnfin, on peut définir des classes de caractères correspondant à des gammes de valeurs en utilisant la notation [...-...]
Par exemple, pour trouver tous les chiffres entre 1 et 5:
stringr::str_view_all(c("3 petits cochons", "101 dalmations", "7 nains"),
"[1-5]")## [1] │ <3> petits cochons
## [2] │ <1>0<1> dalmations
## [3] │ 7 nainsPour trouver toutes les lettres entre A et F:
stringr::str_view_all("A132-f445-e34-C308-M2244-Z449-E18",
"[A-F]")## [1] │ <A>132-f445-e34-<C>308-M2244-Z449-<E>18Pour trouver toutes les lettres entre A et F et a et e:
stringr::str_view_all("A132-f445-e34-C308-M2244-Z449-E18",
"[A-Fa-e]")## [1] │ <A>132-f445-<e>34-<C>308-M2244-Z449-<E>183.2.4 classes prédéfinies
Notez qu’il existe des classes de caractères prédéfinies
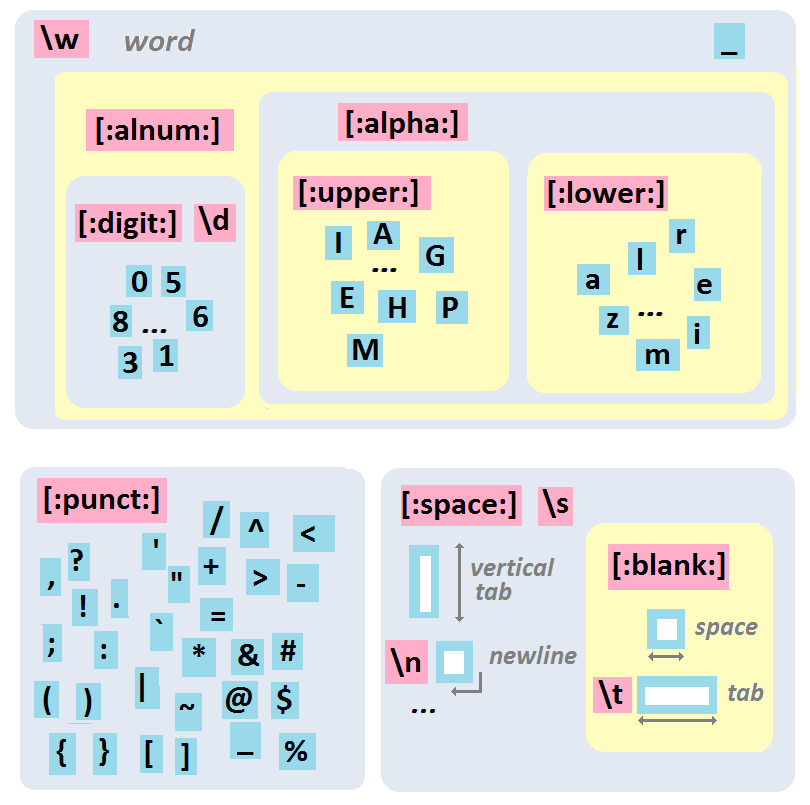
\w: un caractère alphabétique, ou un chiffre, ou un underscore_[:alnum:]: un caractère alphanumérique (caractère alphabétique ou chiffre)[:alpha:]: une caractère alphabétique[:lower:]: une caractère alphabétique minuscule[:upper:]: une caractère alphabétique majuscule[:digit:](qu’on peut aussi écrire\d): un chiffre[:punct:]: un caractère de ponctuation[:space:]: un espace (espace simple, tabulation, tabulation verticale, nouvelle ligne, etc.)[:blank:]: un “blanc” (espace simple ou tabulation)
3.2.5 quelques exemples pour bien comprendre
Une lettre entre A and E, puis un chiffre entre 1 et 6, puis un point, puis “txt”:
stringr::str_view_all(c("A2.txt","B5.png","C3.txt","E6.txt","E9.txt","F4.txt"),
"[A-E][1-6]\\.txt")## [1] │ <A2.txt>
## [2] │ B5.png
## [3] │ <C3.txt>
## [4] │ <E6.txt>
## [5] │ E9.txt
## [6] │ F4.txtUn chiffre suivi d’un espace:
stringr::str_view_all(c("7 nains","3 petits cochons","101 dalmatiens"),
"[0-9] ")## [1] │ <7 >nains
## [2] │ <3 >petits cochons
## [3] │ 10<1 >dalmatiensUn caractère suivi d’un chiffre suivi d’un point:
stringr::str_view_all(c("/pouet3.kebop4.kekepwek.kwak"),
".[0-9]\\.")## [1] │ /poue<t3.>kebo<p4.>kekepwek.kwakUn caractère de ponctuation suivi d’un espace simple et d’une lettre en majuscule:
stringr::str_view_all(c("Allô? c'est John John. Tu as 5 minutes?"),
"[:punct:] [:upper:]")## [1] │ Allô? c'est John John<. T>u as 5 minutes?3.2.6 groupes et références arrières
Il est possible de créer des groupes au sein des expressions régulières, à l’aide de la notation (...)
Par exemple, je peux créer un premier groupe défini par une consonne suivie d’une voyelle à travers l’expression régulière ([^aeiou ][aeiou]), et un deuxième groupe défini de la même manière.
Utilisées avec la fonction str_match_all(), l’usage des parenthèses permet d’isoler différentes parties du pattern:
stringr::str_match_all(c("tili tili woup lala tutu pop"),
"([^aeiou ][aeiou])([^aeiou ][aeiou])")## [[1]]
## [,1] [,2] [,3]
## [1,] "tili" "ti" "li"
## [2,] "tili" "ti" "li"
## [3,] "lala" "la" "la"
## [4,] "tutu" "tu" "tu"L’usage conjoint des groupes et des références arrières permet par ailleurs de rechercher des répétitions de motifs dans les patterns.
Ainsi, pour chercher un pattern composé d’une consonne suivi d’une voyelle, répété deux fois, on peut utiliser une référence arrière \1, \2, etc. (Comme d’habitude, pour passer l’expression régulière à la fonction on utilise un string, donc on double le \):
stringr::str_view_all(c("turlututu tralala"),
"([^aeiou ][aeiou])\\1")## [1] │ turlu<tutu> tra<lala>Ici on recherche un motif (il n’y en a qu’un, donc il est numéroté “1”), répété immédiatement après sa première occurrence.
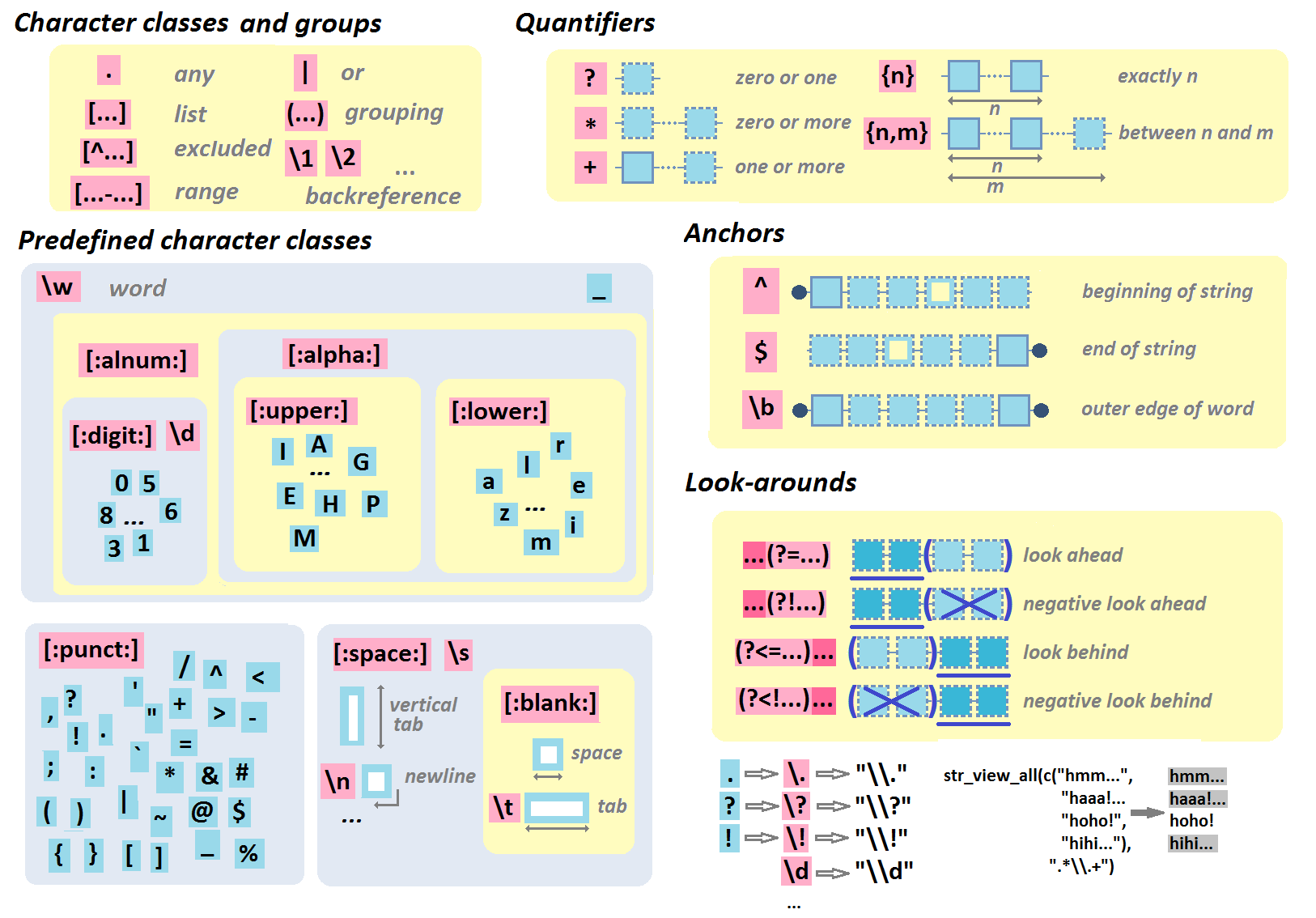
3.2.7 quantificateurs
Les quantificateurs permettent de préciser le nombre d’occurrences consécutives d’une classe de caractères ou d’un groupe.

zéro ou un: On utilise la notation ? à la suite du caractère ou motif recherché.
stringr::str_view_all(c("file1990-fileB1990-file2005-fileAbis2005-fileA2005"),
"file[:alpha:]?\\d\\d\\d\\d")## [1] │ <file1990>-<fileB1990>-<file2005>-fileAbis2005-<fileA2005>zéro ou plus: On utilise la notation * à la suite du caractère ou motif recherché.
stringr::str_view_all(c("fileA088-fileA-fileB-fileA862"),
"fileA\\d*")## [1] │ <fileA088>-<fileA>-fileB-<fileA862>un ou plus : On utilise la notation + à la suite du caractère ou motif recherché.
stringr::str_view_all(c("fileA0885-fileA-fileB-fileA862"),
"fileA\\d+")## [1] │ <fileA0885>-fileA-fileB-<fileA862>exactement n fois: On utilise la notation {n} à la suite du caractère ou motif recherché.
stringr::str_view_all(c("fileA885.txt-fileA1506.txt-fileA1.txt-fileA862.txt"),
"fileA\\d{4}\\.txt")## [1] │ fileA885.txt-<fileA1506.txt>-fileA1.txt-fileA862.txtde n à m fois
On utilise la notation {n,m} à la suite du caractère ou motif recherché.
stringr::str_view_all("fileA885.txt-fileA1506.txt-fileA1.txt-fileA862.txt",
"fileA\\d{2,4}\\.txt")## [1] │ <fileA885.txt>-<fileA1506.txt>-fileA1.txt-<fileA862.txt>3.2.8 ancres et assertions avant-arrière
Les ancres permettent de spécifier l’emplacement du motif par rapport à un mot ou à un string.
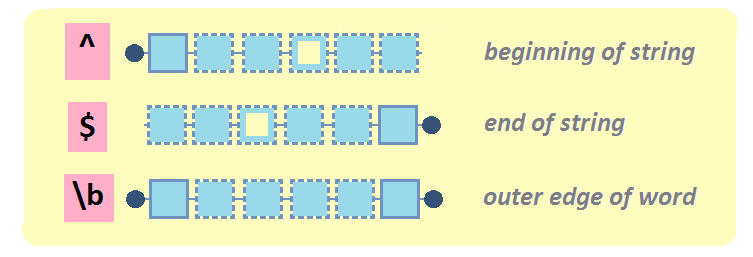
L’ancre ^ fait référence au début d’un string.
stringr::str_view_all(c("Ah! C'est toi John-John?","Ben ça alors, Joe la Frite!"),
"^[:upper:]") # on cherche une majuscule en début de string:## [1] │ <A>h! C'est toi John-John?
## [2] │ <B>en ça alors, Joe la Frite!L’ancre $ fait référence à la fin d’un string.
stringr::str_view_all(c("Allô? John-John?"),
"\\?$")## [1] │ Allô? John-John<?>L’ancre \\b fait référence au début ou à la fin d’un mot.
# tous les mots se terminant par "a":
stringr::str_view_all(c("Carla Lea Armelle Marie Lisa Alexia Nina"),
"a\\b")## [1] │ Carl<a> Le<a> Armelle Marie Lis<a> Alexi<a> Nin<a># tous les mots commençant par une majuscule:
stringr::str_view_all(c("hey Bertrand, aLLeZ vIeNs, il y aura Magda et John-John!"),
"\\b[:upper:]")## [1] │ hey <B>ertrand, aLLeZ vIeNs, il y aura <M>agda et <J>ohn-<J>ohn!3.2.9 assertions avant-arrière
Ces assertions servent à vérifier si un motif existe dans un pattern, sans inclure ce motif dans le résultat.
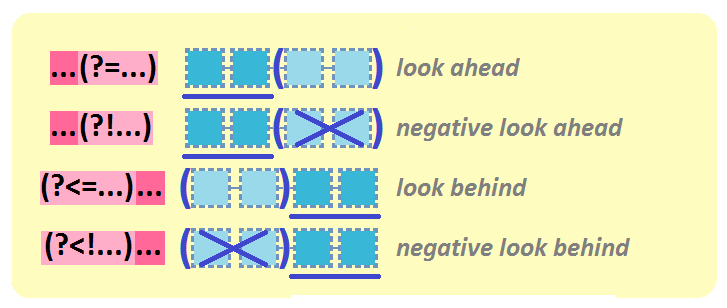
(?=...): Assertion avant(?!...): Assertion avant négative(?<=...): Assertion arrière(?<!...): Assertion arrière négative
Exemple d’assertion avant: on cherche les nombres (\b\d+\b) qui sont suivis de ” dalmatiens”
stringr::str_view_all(c("12 labradors, 101 dalmatiens et 4 loulous"),
"\\b\\d+\\b(?= dalmatiens)")## [1] │ 12 labradors, <101> dalmatiens et 4 loulousExemple d’assertion avant négative: on cherche les nombres (\b\d+\b) qui ne sont pas suivi de ” dalmatiens”
stringr::str_view_all("12 labradors, 101 dalmatiens et 4 loulous",
"\\d+\\b(?! dalmatiens)")## [1] │ <12> labradors, 101 dalmatiens et <4> loulousExemple d’assertion arrière: on cherche les mots commençant par une majuscule ([:upper:][:lower:]*) précédés de “Mr”:
stringr::str_view_all("Mr X, Mr Robot, James Bond et Jon Snow",
"(?<=Mr )[:upper:][:lower:]*")## [1] │ Mr <X>, Mr <Robot>, James Bond et Jon SnowExemple d’assertion arrière négative: on cherche tous les mots commençant par une majuscule et finissant les strings ([:upper:][:lower:]*$) précédés par autre chose que “Mr”:
stringr::str_view_all("Mr X, Mr Robot, James Bond et Jon Snow",
"(?<!Mr )[:upper:][:lower:]*$")## [1] │ Mr X, Mr Robot, James Bond et Jon <Snow>