Seminar of MLO team in EPFL
Presenting Network DP to EPFL
I was invited to give a talk on a short introduction to Differential Privacy and my paper Privacy Amplification by Decentralization at the seminar of the MLO team.

Phd Student in Privacy Preserving Machine Learning
Presenting Network DP to EPFL
I was invited to give a talk on a short introduction to Differential Privacy and my paper Privacy Amplification by Decentralization at the seminar of the MLO team.
Talk at IHPST seminar on the relationship between data and algorithms induced by differential privacy

In line with last year event, I gave a talk to this workshop. The goal is to widen our understanding of algorithms to face the challenges raised by the diversity of algorithms currently deployed. The discussion between lawyers, logicians, machine learning users and philosophers allows to question our practices and bias in how we define the concept of algorithm.
Abstract The recent advances of technology, that make the storage and the processing of large amount of data affordable, drove up the collection of sensitive data. For instance, a smartphone can track its owner position, her sport activity, her messages, her photos, her queries and browsing. Data leakage, malicious or not, is thus a burning issue of the digital era. How can we guarantee privacy, this slippery concept on the fringe of obfuscation, unlinkability, anonymity, confidentiality and data minimization ? Differential privacy is currently the gold standard both in research and industry for machine learning applications. It quantifies the privacy loss occurring during the use of a record, by synthesizing its impact in a scalar. This presentation addresses how the definition was introduced and its implicit assumptions. We see how the context of digitization induces a shift in the privacy protection and test the limit of differential privacy through its variants and real-world implications, connecting it with regulations and other notions of protection.
Differential Privacy: a new notion of the privacy for a new paradigm of data?
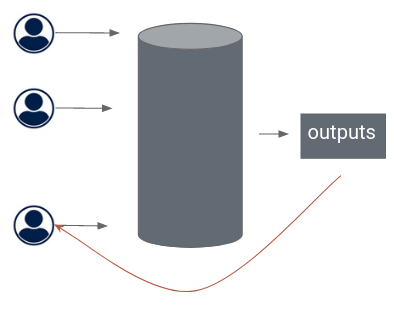
The recent advances of technology, that make the storage and processing of large amount of data affordable, have led to increasing collect of sensitive data. A consequence of the Big Data phenomenon is that the traditional definition of what is personal information, used to define boundary of privacy, seems inaccurate. Indeed, “anonymized” dataset can be massively re-identify, and increases further desanonymization in a vicious circle. Differential Privacy has been proposed as a more relevant way ta measure to what extent a contribution to a database threatens the individual, and it has become the gold standard in Machine Learning research. I will briefly present the key points of the definition, highlight its strengths and the issues that are imposed by this framework.
Official page of the conference: SCAI