Contes et stats R
Lise Vaudor
2018-05-16
Chapitre 1 Introduction
1.1 Pourquoi ce livre?

R a d’abord été conçu comme logiciel de statistiques. Sa richesse, en terme de modèles stats, est indéniable. Cependant, malgré (ou peut-être à cause de) cette richesse et de l’hétérogénéité des packages dédiés aux analyses statistiques, il peut être assez compliqué de s’y retrouver, d’un point de vue purement pratique, dans les lignes de commande permettant d’arriver à ses fins… En effet, pour produire l’ensemble d’une analyse, on aura la plupart du temps de combiner des commandes de plusieurs types (certaines pour produire un graphique, d’autres pour ajuster un modèle, etc.)
Ce livre peut ainsi servir d’aide-mémoire pour retrouver plus facilement les lignes de commande permettant de réaliser les différentes étapes des analyses les plus “classiques”.
Au-delà de cet aspect plus logistique, les statistiques sont un sujet épineux qu’il peut être compliqué de s’approprier si l’on a pas le “parcours académique” adéquat… Or nombreuses sont les personnes qui ont besoin de comprendre et d’appliquer des modèles statistiques, sans pour autant avoir eu une formation de base à cette discipline (ou même sans avoir les notions de probabilités mises en jeu). Or, sans cette formation de base, il est délicat d’appliquer un modèle, de le comprendre et d’avoir le recul nécessaire pour interpréter les résultats de ce modèle…
Ce livre vise ainsi à introduire les modèles statistiques et leurs applications en reprenant et en explicitant les notions de probabilités et statistiques sous-jacentes de la manière la plus didactique et accessible possible.
1.2 Packages
1.2.1 Usage du tidyverse
|
|
En terme de data wrangling (ou arrangement de données dans la langue de Molière) j’ai pris l’habitude d’utiliser les packages du tidyverse (ggplot2, dplyr, tidyr, …), qui sont très bien conçus et facilitent beaucoup de tâches… Je priviligierai donc les fonctions du tidyverse plutôt que les commandes de base quand c’est possible. |
Ainsi, avant d’essayer de reproduire toute autre ligne de commande dans ce livre, il faudra (installer et) charger le tidyverse:
install.packages("tidyverse") # installation (si nécessaire)
library(tidyverse) # chargementVoici les quelques packages du tidyverse que j’utiliserai le plus:
|
|
ggplot2 pour produire les graphiques. Dans ce livre, je me servirai très souvent des fonctions de de package pour produire les graphiques (en fait, j’ai essayé, autant que possible, de ne me servir que de ce package pour produire les graphiques statistiques dans cet ouvrage). Vous pouvez en apprendre plus sur ce sujet sur ce billet de blog et disposer d’un aide-mémoire ici.
|
|
|
dplyr pour manipuler et transformer les tables. Dans ce livre, je m’en sers très souvent, notamment pour calculer des statistiques descriptives par groupe. Vous pouvez en apprendre plus sur ce sujet sur ce billet de blog et disposer d’un aide-mémoireici.
|
|
|
purrr pour simplifier l’écriture de procédures itératives. Dans ce livre, je m’en sers notamment pour faire quelques simulations, ajuster quelques modèles de manière itérative… Vous n’en aurez pas forcément besoin pour comprendre les analyses détaillées mais si vous souhaitez en savoir plus à ce sujet vous pouvez aller voir ce billet de blog et disposer d’un aide-mémoireici
|
1.2.2 Autres packages
J’utilise un certain nombre d’autres packages:
|
|
janitor pour nettoyer les données et mettre en forme des tableaux d’effectifs(https://github.com/sfirke/janitor/blob/master/vignettes/tabyls.md).
|
|
|
infer pour réaliser des tests statistiques selon la logique tidyverse, aider à leur compréhension, et à la réalisation des tests par permutation… Package tout récent!
|
1.2.3 Illustrations
Je me suis amusée à créer quelques illustrations pour cet ouvrage, à l’aide du merveilleux logiciel ArtRage. Au cas où, je précise que j’ai fait ça sur mon temps libre et non mes heures de travail ;-) …
Les illustrations servent à rompre la monotonie (formelle) de cet ouvrage (car, oui, malgré le nombre de graphiques statistiques qu’il contient, j’ai bien peur, du fait de sa taille, qu’il puisse être indigeste si on l’appréhende en un bloc…) et à servir de points de repère visuels. Et puis, solliciter un tout petit peu l’imagination par des images, ça favorise la mémorisation et l’apprentissage.
1.3 Jeux de données
1.3.1 Des jeux de données fictifs
Dans ce livre, j’utiliserai (presque) exclusivement des jeux de données fictifs, pour une question de facilité et de souplesse… Cela me permettra en effet d’avoir des jeux de données intuitifs qui limiteront l’effort à fournir pour le lecteur pour comprendre ce qu’est telle ou telle variable. En effet, je veux me concentrer sur l’explication de la méthode, pas sur l’explication thématique… Par ailleurs, cela me permet de disposer de données de tous les types, distributions, tailles d’échantillon, etc. qu’il me faut pour expliquer un très large éventail de méthodes statistiques.
Utiliser des jeux de données fictifs, cela va aussi me permettre de prendre des exemples les plus universels possibles… En effet, si je prenais des exemples réels issus d’une discipline particulière (par exemple, tout-à-fait au hasard, la géomorphologie fluviale), ça ne serait pas particulièrement parlant pour les personnes d’une autre discipline (par exemple, la psychologie)… Alors que tout le monde peut se projeter dans les histoires de chevaliers, de magicien(ne)s, et de prince(sse)s :-).
Soyons clairs néanmoins: avoir des bons jeux de vraies données pour expliquer une méthode, c’est super, ça permet de vraiment comprendre les problèmes auxquels on est confrontés dans la “vraie” vie (par exemple les données manquantes, le peu de données, la non-normalité), mais c’est très contraignant et c’est beaucoup de travail (trouver un jeu de donnée “open” et ad hoc pour chaque méthode, le rendre facilement accessible et compréhensible…) et ce n’est donc pas le choix que j’ai fait pour cet ouvrage.
1.3.2 Brocéliande

|
Le jeu de données
|
Le jeu de données broceliande est disponible en ligne à cette adresse.
broceliande=read.csv("http://perso.ens-lyon.fr/lise.vaudor/grimoireStat/datasets/broceliande.csv",
header=TRUE,sep=";")
str(broceliande)## 'data.frame': 864 obs. of 9 variables:
## $ age : num 5.228 20.942 50.651 12.566 0.419 ...
## $ espece : Factor w/ 4 levels "chataignier",..: 2 2 2 2 2 2 2 2 2 2 ...
## $ hauteur : num 219 179 302 265 110 ...
## $ gui : int 0 0 0 0 0 0 0 0 0 0 ...
## $ largeur : num 190 175 320 313 118 ...
## $ enchantement: logi TRUE TRUE TRUE FALSE TRUE FALSE ...
## $ fees : int 1 0 0 0 0 0 0 0 0 0 ...
## $ lutins : int 0 0 0 0 0 0 0 0 0 0 ...
## $ perlimpinpin: num 129 170 153 134 122 ...1.3.3 Châteaux et Boulots

|
Le jeu de données
|
Le jeu de données chateauxEtBoulots est disponible en ligne à cette adresse.
chateauxEtBoulots=read.csv("http://perso.ens-lyon.fr/lise.vaudor/grimoireStat/datasets/chateauxEtBoulots.csv",
header=TRUE, sep=";")
str(chateauxEtBoulots)## 'data.frame': 72 obs. of 4 variables:
## $ activite: Factor w/ 4 levels "chevalerie","enchantements",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ sexe : Factor w/ 2 levels "feminin","masculin": 2 2 2 2 2 2 2 2 2 2 ...
## $ region : Factor w/ 3 levels "bois-jolis","flots-blancs",..: 1 1 1 1 1 1 2 2 2 2 ...
## $ tenue : Factor w/ 5 levels "bleue","grise",..: 1 1 2 4 5 5 1 1 2 3 ...1.3.4 Potions

|
Le jeu de données
|
Parmi les ingrédients, on peut citer par exemple ailes de papillon, bave de crapaud, pierre de lune, etc.
En terme de propriétés on a relevé si les potions permettent
- d’altérer l’apparence, de se transformer en loup-garou ou en plante verte (
altération) - de conjurer des esprits ou des morts-vivants (conjuration) - de lancer des éclairs, des boules de feu ou des pics de glace (
destruction) - de devenir invisible (
invisibilite) - de se protéger des attaques (
resistance)?
Quant aux modalités d’élaboration des potions, elles décrivent la nécessité d’une formule ou non, et si oui, et en quelle langue (elfique ou latin). La préparation peut être effectuée par bouillon, macération ou distillation.
Le jeu de données potions est disponible en ligne à cette adresse.
potions=read.csv("http://perso.ens-lyon.fr/lise.vaudor/grimoireStat/datasets/potions.csv",
sep=";", header=T)
str(potions)## 'data.frame': 67 obs. of 17 variables:
## $ m_formule : Factor w/ 3 levels "aucune","elfique",..: 3 1 2 3 3 3 1 3 1 2 ...
## $ m_preparation : Factor w/ 3 levels "bouillon","distillation",..: 1 1 1 1 2 1 1 3 3 2 ...
## $ i_bave_crapaud : num 6.98 13.06 15.61 12.75 6.96 ...
## $ i_sang_hirondelle : num 11.07 16.1 18.07 21.86 8.53 ...
## $ i_aile_papillon : num 3.841 0.271 21.129 31.255 11.125 ...
## $ i_ectoplasme : num 2.197 3.39 1.767 0.935 8.172 ...
## $ i_graisse_troll : num 5.38 2.93 16.62 13.8 6.93 ...
## $ i_pied_lutin : num 14.77 22.99 2526.39 4.84 30.15 ...
## $ i_givreboises : num 36.84 99.44 30.89 541.82 9.61 ...
## $ i_pierre_lune : num 1.57e+05 6.39e+06 3.89e+02 1.88e+10 2.07e+19 ...
## $ i_larmes_crocodile: num 0.312 4.393 2.131 0.586 20.246 ...
## $ p_resistance : num 4.12 4.9 2.39 11.28 3.75 ...
## $ p_destruction : num 0.421 0.664 0.491 -0.154 1.212 ...
## $ p_invisibilite : num 7.24 8.62 7.53 14.76 21.18 ...
## $ p_transformation : num 46 18.2 26.1 23.8 20.6 ...
## $ p_conjuration : num -0.876 -2.174 14.245 3.827 5.215 ...
## $ p_alteration : num 4.33 4.98 8.28 4.49 4.04 ...1.4 Rappels
Quelques rappels des fonctions de bases pour décrire ses données
1.4.1 Décrire un tableau
Affichage des dimensions, nombre de lignes, nombre de colonnes :
dim(broceliande)## [1] 864 9nrow(broceliande)## [1] 864ncol(broceliande)## [1] 9Affichage des premières lignes, ou dernières lignes ou de l’ensemble du tableau dans le “Viewer” de RStudio:
head(broceliande)## age espece hauteur gui largeur enchantement fees lutins
## 1 5.228017 chene 219.1 0 189.6339 TRUE 1 0
## 2 20.942126 chene 178.7 0 174.9923 TRUE 0 0
## 3 50.651180 chene 301.8 0 320.0635 TRUE 0 0
## 4 12.565862 chene 265.2 0 312.5803 FALSE 0 0
## 5 0.419487 chene 109.9 0 117.7305 TRUE 0 0
## 6 152.585839 chene 287.9 0 329.7500 FALSE 0 0
## perlimpinpin
## 1 129.0095
## 2 170.2561
## 3 153.1471
## 4 134.0399
## 5 122.3146
## 6 154.5884tail(broceliande)## age espece hauteur gui largeur enchantement fees lutins
## 859 4.4723849 sapin 248.4 0 249.8085 FALSE 0 0
## 860 38.3755844 sapin 252.2 1 243.1223 FALSE 0 0
## 861 8.9334070 sapin 274.8 3 227.3613 TRUE 0 0
## 862 7.2500990 sapin 177.0 1 159.6963 FALSE 0 0
## 863 250.3051182 sapin 195.0 1 214.0476 FALSE 0 0
## 864 0.1406944 sapin 272.3 4 219.6357 FALSE 0 0
## perlimpinpin
## 859 112.41735
## 860 84.04768
## 861 156.11338
## 862 133.52802
## 863 140.52587
## 864 139.22678Affichage de la structure, d’un résumé de la distribution des variables du tableau:
str(broceliande)## 'data.frame': 864 obs. of 9 variables:
## $ age : num 5.228 20.942 50.651 12.566 0.419 ...
## $ espece : Factor w/ 4 levels "chataignier",..: 2 2 2 2 2 2 2 2 2 2 ...
## $ hauteur : num 219 179 302 265 110 ...
## $ gui : int 0 0 0 0 0 0 0 0 0 0 ...
## $ largeur : num 190 175 320 313 118 ...
## $ enchantement: logi TRUE TRUE TRUE FALSE TRUE FALSE ...
## $ fees : int 1 0 0 0 0 0 0 0 0 0 ...
## $ lutins : int 0 0 0 0 0 0 0 0 0 0 ...
## $ perlimpinpin: num 129 170 153 134 122 ...summary(broceliande)## age espece hauteur gui
## Min. : 0.046 chataignier:265 Min. : 7.9 Min. :0.0000
## 1st Qu.: 2.867 chene :351 1st Qu.:149.4 1st Qu.:0.0000
## Median : 12.938 hetre :174 Median :197.6 Median :0.0000
## Mean : 88.433 sapin : 74 Mean :216.0 Mean :0.3032
## 3rd Qu.: 46.224 3rd Qu.:268.8 3rd Qu.:0.0000
## Max. :4500.259 Max. :853.2 Max. :7.0000
## largeur enchantement fees lutins
## Min. : 9.087 Mode :logical Min. : 0.0000 Min. : 0.000
## 1st Qu.:144.073 FALSE:698 1st Qu.: 0.0000 1st Qu.: 0.000
## Median :207.499 TRUE :166 Median : 0.0000 Median : 0.000
## Mean :228.269 Mean : 0.2442 Mean : 1.258
## 3rd Qu.:289.223 3rd Qu.: 0.0000 3rd Qu.: 0.000
## Max. :792.646 Max. :22.0000 Max. :718.000
## perlimpinpin
## Min. : 70.01
## 1st Qu.:104.98
## Median :119.84
## Mean :120.25
## 3rd Qu.:134.36
## Max. :185.411.4.2 Décrire vecteur numérique
1.4.2.1 par une métrique
Longueur du vecteur:
length(broceliande$hauteur)## [1] 864Minimum, maximum, étendue d’un vecteur
min(broceliande$hauteur)## [1] 7.9max(broceliande$hauteur)## [1] 853.2range(broceliande$hauteur)## [1] 7.9 853.2Tendance centrale: moyenne, médiane:
La moyenne d’une variable \(X\) (ou espérance, \(E(X)\)) correspond à:
\[\begin{eqnarray} E(X) &=&\frac{1}{N}(X_1+X_2+....+X_N)\\ &=&\frac{1}{N}\sum_{i=1}^{i=N}{X_i} \end{eqnarray}\]mean(broceliande$hauteur)## [1] 216.0025median(broceliande$hauteur)## [1] 197.6Variabilité: écart-type, variance:
La variance d’une variable (\(V(X)\)) correspond à:
\[\begin{eqnarray} V(X)&=&\frac{1}{N-1}[(X_1-\bar X)^2+...+(X_N-\bar X)^2]\\ &=& \frac{1}{N-1}\sum_{i=1}^{i=N}(X_i-\bar X)^2\\ &=& sd(X)^2 \end{eqnarray}\]sd(broceliande$hauteur)## [1] 97.94254var(broceliande$hauteur)## [1] 9592.741Distribution: quantiles, résumé
Le quantile d’ordre \(q\) d’une variable \(X\) est la valeur \(x\) telle que :
\[pr(X\leq x)=q\].
On parle de premier, deuxième, et troisième quartiles pour les quantiles d’ordre 0.25, 0.5, et 0.75.
Le deuxième quartile est en outre équivalent à la médiane.
quantile(broceliande$hauteur,0.05)## 5%
## 87.09quantile(broceliande$hauteur,c(0.05,0.95))## 5% 95%
## 87.09 374.44summary(broceliande$hauteur)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 7.9 149.4 197.6 216.0 268.8 853.2Si le nombre de valeurs différentes est limité, affichage des effectifs par valeur:
table(broceliande$fees)##
## 0 1 2 3 4 5 6 7 11 22
## 769 53 23 6 4 3 2 1 2 1ou bien par les fonctions du tidyverse (ici package dplyr):
broceliande %>%
group_by(fees) %>%
summarise(n=n())## # A tibble: 10 x 2
## fees n
## <int> <int>
## 1 0 769
## 2 1 53
## 3 2 23
## 4 3 6
## 5 4 4
## 6 5 3
## 7 6 2
## 8 7 1
## 9 11 2
## 10 22 11.4.2.2 par un graphique
ggplot(broceliande, aes(x=hauteur))+
geom_histogram(fill="forestgreen")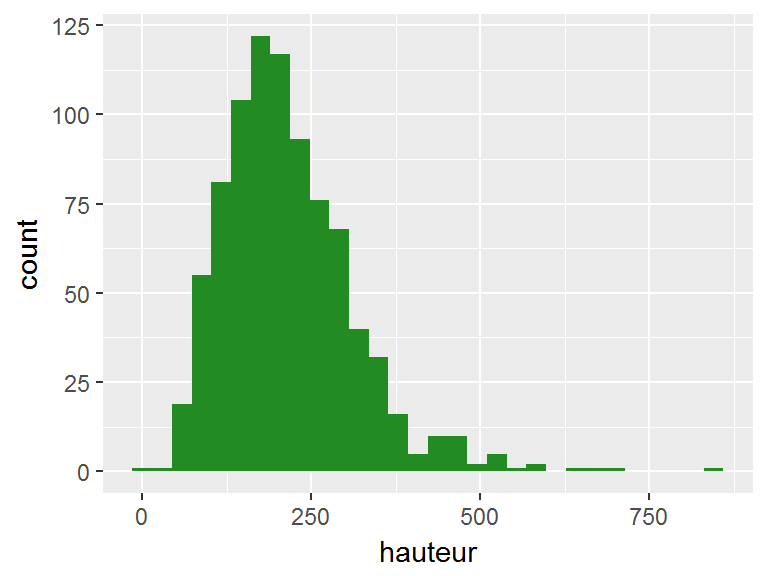
1.4.3 Décrire un vecteur catégoriel:
1.4.3.1 par une métrique
Longueur du vecteur:
length(broceliande$espece)## [1] 864Affichage des effectifs par valeur:
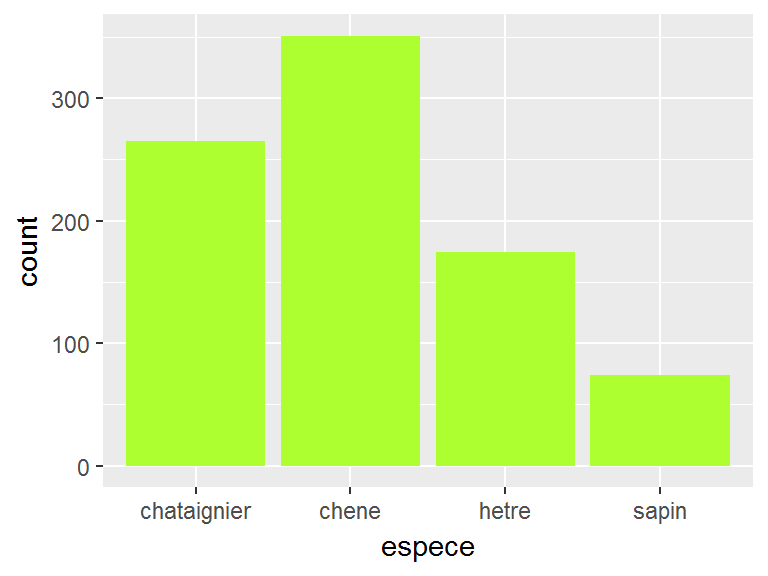
table(broceliande$espece)##
## chataignier chene hetre sapin
## 265 351 174 74ou bien par les fonctions du tidyverse (ici package dplyr):
broceliande %>%
group_by(espece) %>%
summarise(n=n())## # A tibble: 4 x 2
## espece n
## <fct> <int>
## 1 chataignier 265
## 2 chene 351
## 3 hetre 174
## 4 sapin 74Le package janitor propose également quelques fonctions qui permettent d’“arranger” plus facilement ces tables d’effectifs en tables de proportions (avec quelques infos supplémentaires -fonctions adorn_xxx()-):
##install.packages("janitor")
library(janitor)
tabyl(broceliande$espece) %>%
adorn_pct_formatting() %>% # rajoute pourcentage
adorn_totals("row") # rajoute total des lignes## broceliande$espece n percent
## chataignier 265 30.7%
## chene 351 40.6%
## hetre 174 20.1%
## sapin 74 8.6%
## Total 864 -1.4.3.2 par un graphique
ggplot(broceliande,aes(x=espece))+
geom_bar(fill="greenyellow")